
一种用于语义分割的大规模遥感场景数据集构建
【摘 要】 随着深度学习在计算机视觉任务中的进步,它在其他领域的应用得到了推动。该技术已越来越多地应用于遥感图像的解译,显示出巨大的潜在经济和社会意义,例如自动绘制土地覆盖图。然而,该模型需要相当数量的样本进行训练,现在由于缺乏大规模数据集而受到不利影响。而且,标注样本是一项费时费力的工作,尚未建立适合深度学习的完整土地分类体系。这种限制阻碍了深度学习的发展和应用。为了满足遥感领域深度学习的数据需求,本研究开发了 JSsampleP,这是一个用于分割的大规模数据集,生成了 110,170 个数据样本,涵盖了中国江苏省内的各类场景。充分利用江苏现有地理国情数据集(GCD)和基础测绘数据集(BSMD),显著降低样本标注成本。此外,样品经过严格的清洁过程以确保数据质量。最后使用 U-Net 模型验证数据集的准确性,后续版本会不断优化。
【原 文】 Xu, L. et al. (2023) ‘A large-scale remote sensing scene dataset construction for semantic segmentation’, International Journal of Image and Data Fusion, 0(0), pp. 1–25. Available at: https://doi.org/10.1080/19479832.2023.2199005.
1 引言
深度卷积神经网络是目前图像识别中最常用的深度学习形式 (Li 2022 [28], Ma 等 2022 [32])。这些神经网络强大的识别性能背后的前提是海量样本的训练。随着大数据时代的到来,像 ImageNet (Deng 等 2009 [17]) 这样大量收集自然图像的数据集为这些模型的开发提供了有价值的数据平台。由于其强大的特征提取能力,这些模型也被用于卫星或航拍图像识别(Campos-Taberner 等 2020 [6], Ding 等 2022 [18], Lu 等 2022 [31])。
通过自动解读遥感图像,可以获得土地覆盖信息(Robinson 等 2019 [34], Vali 等 2020 [41], Kazemi Garajeh 等 2022 [26], Sertel 等 2022 [36])。城市规划者广泛使用这些信息来协助管理任务,例如城市规划和土地使用性质调查,最终可以导致环境保护和经济发展。
大多数现有的遥感数据集只包含几个类别,而实际的土地覆盖类别要多样化得多。这种限制无法满足对土地覆盖信息日益增长的需求。这些数据集中的图像样本数量通常只有几千个左右,这使得深度学习模型很难达到更高的精度。尽管这些数据集中的大多数都可用于场景分类,但像素级分类对于更精细的映射更有意义。此外,用于分割的样本标记过程耗时耗力,使得难以从遥感图像生成大型、高质量的数据集。不仅获取高分辨率遥感影像不易,相应的影像标注也难以完成。此外,遥感图像通常非常大,而深度学习模型的输入尺寸相对较小。许多数据集没有考虑到这些细节,大图像及其相应的标签通常需要在使用这些数据集进行训练时进行裁剪。
为了应对上述挑战,我们将中国江苏省公共部门开发的两种产品 GCD 和 BSMD 确定为数据集的数据源。这些产品包括图像数据库和矢量数据库。图像数据库提供高分辨率卫星或航空图像。专业制图员使用图像作为解释依据来标注江苏省的地表。最终制图结果主要存储在采用土地覆盖或土地利用分类标准的矢量数据库中,并通过实地验证确保矢量数据库的准确性。总的来说,映射过程本质上等同于手动样本注释。通过分析这些数据并充分利用它们,构建了我们的分割数据集。深度学习模型通过对该数据集的训练可以更准确地解读土地覆盖信息,实现土地覆盖和土地利用变化的自动监测。我们预计,江苏土地覆盖和相关变化的自动更新将成为现实,最终帮助规划人员就环境和土地利用管理做出更明智的决策。
本研究旨在实现两个主要目标。
(1) 该研究综合分析了江苏省 GCD 和 BSMD 的不同土地覆盖类别,然后将它们汇总并合并到我们的数据集 JSsampleP 的统一土地覆盖类别系统中。基于图像和矢量数据库生成样本,以确保我们的大规模数据集更适合语义分割研究。
(2) 为进一步保证样本的高质量,初步完成了基于 U-Net 模型的辅助清洗。此外,为后续研究提供了使用深度学习方法进行语义分割的基线。
2 相关工作
2.1 大规模遥感数据集。
(1)场景分类数据集:
- SAT-4 和 SAT-6 (Basu 等 2015 [4]) 是具有多个类别标签的卫星图像分类数据集。
- AID (Xia 等 2017 [50]) 是一个用于航空场景分类的大型数据集,它收集并标注了 30 类中的一万多张航空场景图像。它比 UC-Merced 数据集 (Yang and Newsam 2010 [54]) 和 WHU-RS19 (Hu 等 2015 [23]) 拥有更多的数据,有助于开发遥感场景分类算法。
- NWPU-RESISC45(Cheng 等 2017 [12])和 RSI-CB(Li 等 2017 [29])的数据量也达到了数万,涵盖了数十个类别。
- BigEarthNet(Sumbul 等,2019 年 [37])由 590,326 个 Sentinel-2 图像块组成,每个图像块都由多个土地覆盖类进行注释。
- fMoW (Christie 等 2017 [15]) 包含来自 200 多个国家的超过 100 万张图像,旨在根据卫星的时间序列和丰富的图像元数据特征预测土地利用。
- EuroSAT(Helber 等,2019 年 [22])基于 Sentinel-2 卫星图像,涵盖 13 个光谱带,由 10 个类别组成,共有 27,000 张带标签和地理参考的图像。
(2)目标检测数据集:
(3)语义分割数据集:
- WHU(Ji 等 2019 [25])、AIRS(Chen 等 2018 [10])和 SpaceNet MVOI(Weir 等 2019 [49])用于研究建筑物提取,并使用 Agriculture-Vision(Chiu 等 2020 [14])探索现场异常模式。这些数据集都专注于特定单类特征的映射和分析。
- ISPRS Vaihingen (Wang 等 2022b [47])、ISPRS Potsdam (Wang 等 2022a [46])、Zurich Summer (Volpi and Ferrari 2015 [43]) 和 Zeebruges (Marcos 等 2018 [33]) 都在高分辨率图像上标注了多类土地覆盖但主要研究城市场景语义解析;
- DeepGlobe(Demir 等,2018 年 [16])和
LandCover.ai(Boguszewski 等,2021 年 [5])涉及更多农村地区。 - LandCoverNet(Alemohammad 和 Booth 2020 [1])提供了一个用于土地覆盖分类的全球训练数据集。然而,Sentinel-2 观测的空间分辨率仅为 10 m,标注的类别无法进行更细粒度的扩展。
- iSAID (Waqas Zamir 等 2019 [48]) 和 SkyScapes (Azimi 等 2019 [2]) 都具有高精度、细粒度的像素级语义标注标注,但由于标注成本高,覆盖范围非常有限。
- MiniFrance 套件(Castillo-Navarro 等 2022 [8])、GID(Tong 等 2020 [40])和 LoveDA(Wang 等 2021a [44])都是为特定任务制作的数据集,其中:
- MiniFrance 套件包含标记数据和未标记数据,这便于研究半监督学习。
- GID 包含 150 张高分二号卫星图像,其中标注了 5 个主要类别和 15 个子类别,用于迁移学习土地覆盖分类。
- LoveDA 数据集收集了城市和农村地区 166,768 个带注释对象的图像,用于领域自适应语义分割。
- Satlas (Bastani 等 2022 [3]) 是一个用于遥感图像理解的大规模、多任务数据集,但尚未正式发布。
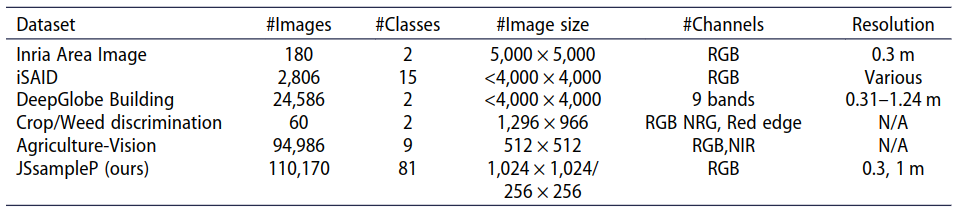
所有这些数据集都是根据其特定任务制作的,数据集区域和传感器的差异使其不具有通用性。目前遥感地物像素级分类具有广泛的应用意义,如制图、环境规划、数字地球等,但目前发布的语义分割数据集较少,且对象类别数量有限和数据量。相反, JSsampleP 提供了 86 个对象类别,超过 110,000 张图像和标签数据用于遥感对象的语义分割(见 表 1 中的比较)。
表 1. 其他数据集的统计数据
2.2 遥感自监督学习
近年来,自监督学习已成为无监督表示学习的有前途的候选者(Caron 等 2020,Grill 等 2020,Van Gansbeke 等 2021,Wang 等 2021b,Xie 等 2021,He 等 2022)。它在视觉领域获得了极大的关注,其高效的视觉表示能力和独立于标签数据的能力也引起了遥感领域众多研究者的关注(Hua 等 2021, Wang 等 2022c)。
研究证明,遥感图像的自监督预训练比自然场景图像的监督预训练效果更好,可以提高下游任务的性能,例如土地覆盖的语义分割和地表变化监测(Chen 等 2022 年,Tarasiou 和 Zafeiriou 2022 年,Tarasiou 等 2022 年)。 Siamese 网络(Chen 和 He 2021,Xie 等 2022)已成为近期各种自监督视觉表示学习模型中的常见结构。我们使用这个神经网络在没有任何标记数据的情况下预训练了骨干 resnet。与最常用的初始化方法(如随机初始化和 ImageNet 预训练)相比,它开辟了使用所提出的预训练方案而不是地球观测任务的随机初始化来提高遥感语义分割性能的可能性。
3 数据与方法
3.1 数据准备
(1)遥感数据
江苏省研究区地处中国大陆东部沿海中部,横跨东经116°18′至121°57′,北纬30°45′至35°20′。陆地面积10.72万平方公里,交通便利,海域面积3.75万平方公里,水网密集。江苏省自然资源丰富,植被种类繁多。此外,作为经济发达地区,它拥有更丰富、更全面的地表信息,包括一个覆盖地球表面10万平方公里的遥感影像库。选择 GCD 和 BSMD 中的图像数据库作为我们数据集的图像源。它们包含覆盖全省的高分辨率航拍和卫星图像。为了确保图像之间的准确空间比较,严格要求将它们几何配准到一个公共坐标系。此外,还应用了其他预处理技术来促进我们数据集的建立。执行大气校正以消除图像之间的任何差异。在将图像存储在图像数据库中之前,实现了图块/场景之间的无缝过渡和无云覆盖。由于它们旨在提供土地覆盖和相关变化的固定年度周期性更新,当前图像与遗留数据相结合为我们提供了广泛的光学图像以用于我们的数据集。由于这些图像的分辨率可以达到 1 m 以内,因此由于这种像素大小,在 1:100,00 以下的比例尺中进行映射会变得更加容易。这为细粒度类别的语义分割创造了良好的条件。简而言之,我们的 JSsampleP 包括 Google Earth 提供的覆盖整个江苏省的卫星图像(1 m/像素)和江苏省可用的江苏省地理信息中心拍摄的高分辨率航拍图像(0.3 m/像素)。这些分辨率上的显著差异使 JSsampleP 更加真实和丰富,因为所选图像在时间上最接近矢量数据。所有图像都包含三个通道(红色、绿色和蓝色)。
(2)矢量数据
BSMD 和 GCD 中的矢量数据库存储图像中景观元素的地理位置信息。 BSMD 侧重于土地利用制图,而 GCD 主要用于土地覆盖制图。由于它们的功能不同,它们的分类系统也各不相同。 BSMD 中的数据库平均每 5 年更新一次,分为九个数据集,包括水、居住区和设施、植被和土壤质量。每个数据集由制图规范要求的点、线性和多边形图层组成。图 1 显示了图像上不同独立层的一些特征。由于制图比例尺的限制和制图要求,许多要素类型都是用点或线几何表示的。带有描述(例如坡度和海拔)的地理空间数据也被编辑以产生更多的专题地图作为衍生品。 GCD 中的数据库每年更新一次,主要包括土地覆盖数据。它根据GCD分为三个级别(8级I,46级II和86级III)。为了提供高质量的空间表示,所有自然要素都以多边形表示,并具有足够的顶点来描绘它们。图 2 表明特征表示在图像上具有足够的细节。需要为每种土地覆盖类型制定一系列解释符号,以减少技术人员解释造成的错误。就位置精度而言,GCD 中标记特征与相应图像之间的平均偏移量限制为 5 个像素。我们总结了两个矢量数据源之间的异同。它们都是通过目视解译从遥感图像中获得的。通过不同专业人员的反复解读和现场验证,确保质量控制。
他们都有严格的标注流程。虽然位置精度与两种数据一致,但 GCD 具有更高的语义精度和形状精度。同时,它们有不同的分类系统,其中 BSMD 包含更多的人为特征,GCD 包含更多的自然特征。
3.2 数据集构建
3.2.1 JSsampleP 类别的层次结构
3.2.2 JSsampleP 的属性
3.3 样本制作流程
每个遥感图像都与一张矢量地图配对,用于土地覆盖注释。在整个江苏省,同一类别的地图要素密度分布不均,很多对于样本制作来说是多余的。特征的清晰度通常与特征的大小相关联。当使用滑动窗口裁剪大注释时,我们还会丢弃任何只有背景像素的图像块。通过施加≥10%的阈值(标注实例在类中的面积与对应样本的面积比),过滤掉地图层中不具有代表性的矢量数据,使该类的面积在样本中占主导地位。根据过滤后不同地图图层中每个多边形的地理坐标信息,生成平面网格(256×256 或 1024×1024)并扩展每个图层。这些网格是从遥感图像中截取的。同时,相应的向量也被栅格化以形成二进制掩码作为标签。根据每一层的特征类型,确定样本所属的类别。以上通过不同的空间分析工具实现,形成自动化生产模式。如图 8 所示,每个样本都记录了信息(例如图像拍摄时间和空间分辨率以及图像传感器和样本类别)以方便数据集的管理。我们最终样本库的原图保存为 jpg 格式,而标签保存为二进制图片 png 格式。裁剪后的图像和相应的标签按数字排序。由于手动标记的错误是不可避免的,因此当我们的数据集达到一定数量时,采用预训练的深度学习模型半自动清洗样本。上述过程如图 9 所示。首先将大的粗样本放入模型进行训练,然后分别对样本进行测试,并设置一定的半自动辅助清洗阈值。其次,对分割结果不佳的样本进行人工检查,以确定是否需要重新标记。正确的样本放入 Type A,错误的样本放入 Type B。Type B 的样本重新修改后恢复到样本库中(图 10)。
3.4 实验设置
U-Net 模型(Ronneberger 等 2015)用于评估数据集,分为模型训练、模型验证和模型测试。样本分为训练 (80%) 和测试 (20%)。为保证数据的独立性,我们的训练数据和测试数据分别选自江苏省不同地区的样本。在训练阶段,训练数据也会根据不同的区域随机分为训练集和验证集(5:1)。为了避免相似的样本,我们遵循两步法。首先,我们根据江苏省的行政地理随机划分两组的数据位置。其次,我们将每个样本分配给与其地理位置属性相对应的拆分,该属性可用于我们库中的每个样本类别。这种方法保证来自同一区域的裁剪图像不会出现在我们训练数据的多个分割中,从而减少潜在的偏差并提高我们模型的通用性。批量大小为 32,实验的学习率设置为 1 × 10−8。训练过程平均进行了 120 个时期。优化算法 Adam 用于微调损失值。在这项研究中,Intel® Xeon® 处理器 E5–2630 v4 2.20 GHz 和 NVIDIA Tesla P100 GPU 16GB 是实验硬件平台,而深度学习框架是 TensorFlow。
3.5 实验指标
为了便于在数据集上进行模型测试,选择了以下四个评价指标来完成工作:交集并集(IOU)、Precision、Recall和F1 score。具体公式如下:
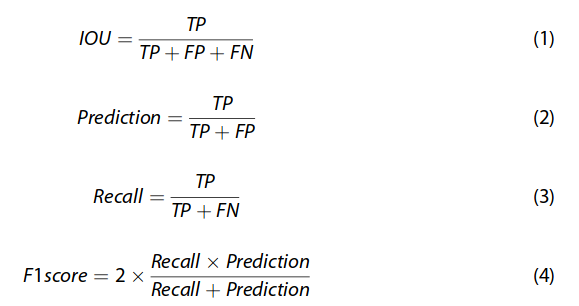
其中 TP 代表真阳性,TN 代表真阴性,FP 代表假阳性,FN 代表假阴性。
4 结果与讨论
4.1 结果分析
我们从我们的数据集中选择了几十个类别进行训练和测试,大多数样本类的整体 IOU 在 50% 到 80% 之间。一般来说,种植地、地表和水系统表现良好,只有少数表现不佳,如建筑用地。这种糟糕的表现可能是由于样本数量有限以及此类的变化和多样性导致的挑战增加。图 11 展示了 U-Net 模型在 JSsampleP 的几个类别中的结果可视化,展示了其在各种地物中的良好表现。

图11. 干地、工业设施、陆地表面、稻田、铁路、森林和草地以及非铁路道路的模型测试结果(从左到右)。
属于同一个二级类的一些三级类合并训练。对于农业用地类,将水田和旱地合并进行训练,以测试模型对语义重叠度高的类的效果。由表 4 可知,旱地和水田合并后的评价结果与单独水田和旱地的评价结果一致。可能的原因是水田和旱地之间存在一定的语义相似性。地表和水的评估结果低于其子类。江苏省地表样本数量较少,地表材质差异显著,因此地表纹理信息也存在显著差异,导致合并评价结果存在较大差异。其他结果表明,森林和草地覆盖类的总体准确性高于细粒度类。森林和草地覆盖率的准确性差是出乎意料的,可能与样本之间的类别不平衡有关。水相关样本合并后效果不佳可能与正负水像素比例不均有关。尽管水子类别的内部特征非常相似,但根据其预期用途将它们分成不同的子类别。然而,对于类别(例如河流、运河和水库),样本图像中的比例差异很大。河流、运河形状狭长,而水库面积大,在一幅图像中的比例变化很大,可能会削弱模型学习数据分布的能力。
表4. 模型评估结果

此外,我们使用航空训练数据在 resnet34 上进行自我监督训练 (Chen and He 2021),并将其与测试集上的 Imagenet 预训练 resnet34 (He 等 2016) 进行比较。两种不同方法产生的 resnet34 在前向推理时选择第四层 64 维的 feature map 进行归一化操作。随机选择热图进行视觉比较。图 12 暗示了在自监督方法中训练的 backbone 可以更好地表示表面类别的特征,具有更强的表示学习能力。这有助于提高下游性能。

图 12. 原始图像(第一和第二行);通过在 ImageNet 上预训练的 resnet34 可视化的热图结果(第三和第四行);通过使用自监督预训练的 resnet34 可视化的结果(第五和第六行)。
4.2 遥感解译
我们使用了一种基于 U-Net 模型的机制,该机制通过集成嵌套进行优化来分割遥感图像。该模型在 JSsampleP 数据集上进行了训练,并解释了测试数据集。为了增强模型的轮廓提取能力,我们采用了形态学后处理方法。此外,我们在 JSsampleP 上使用分辨率为 0.3 m 的航拍图像进行了像素级分类。
为了评估我们的方法的性能,我们将其与 DeeplabV3(Chen 等 2017)、PSPNet(Zhao 等 2017)和 PAN(Li 等 2018)在 JSsampleP 数据集上进行比较,使用五类 房屋、农业、铁路、公路和森林。我们的方法分别实现了 0.8314、0.8909、0.5865、0.6978 和 0.6931 的 IOU 分数,每个类别的补丁大小为 1024 × 1024(表 5)。如表中所示,我们的方法在 IOU 中优于其他三个模型。这是因为我们的方法利用 U-Net 结构的多尺度输出来提取尺度特征信息,从而取得了更好的结果。事实证明,我们集成尺度特征信息的方法背后的简单直觉可以有效提高模型的性能。
表 5. JSsampleP 中不同模型的 IOU 结果

表 6. 在 JSsampleP 中使用不同初始化方法的 IOU 结果,使用我们的模型

House、Agriculture 和 Forest 类别的 IOU 得分均能达到 60%,而 Railway 和 Highway 的模型表现并不理想,因为这两类物体在图像中的像素比例极低。 Railway 特征不如 Highway 明显,更容易被背景混淆,使得 Railway 提取比 Highway 更具挑战性。
为了验证我们改进模型的稳健性,我们在 1 m 分辨率的数据集中对房屋、农业、道路、温室和森林进行了一些消融实验。我们使用预训练的主干来微调我们的模型,并从头开始训练所有层的参数,并分别进行随机初始化以进行比较。我们的模型在 IOU 指标上没有太大差异。表 6 显示了实际的定量结果。图 13 显示了我们模型使用两种不同初始化方法的训练过程。图 14 给出了我们的模型在五个类别中的分割结果。
如图 15(a1、b1、c1 和 d1)所示,森林和草地覆盖度的模型结果由于缺乏其他波段的信息而不太准确,降低了模型的识别能力。然而,在高分辨率遥感图像识别中,农田规则的形状和纹理更容易与周围植被形成鲜明对比,有助于准确提取标准大片农田的识别等高线,如图图 15(a2、b2、c2 和 d2)。这部分是由于数据集中的常规农田样本占绝大多数,以及模型对常规农田的敏感性。建筑类别的结果优于其他类别,如图 15(a3、b3、c3 和 d3)所示。在道路识别方面,该模型能够对市区道路神经网络进行整体识别,如图 15(a4、b4、c4 和 d4)所示。然而,乡村道路识别的效果并不理想,这可能是由于数据集中的路径样本较少所致。

图13. 我们的模型在不同初始化方法下的损失。

图14. 我们方法在不同初始值下的分割结果。从左到右每列分别为原始图像、真实标签、预训练分割结果和非预训练分割结果。(A)农业(B)温室(C)房屋(D)道路(E)森林。

图 15. 图像解译
5 结论
在本研究中,引入了一个大型遥感数据集 JSsampleP。由于它们应用于实际的遥感解译场景,因此也建立了完整的分类体系。本文对示例库进行了分析,并详细讲解了 JSsampleP 的构建过程。此外,在 U-Net 模型训练后提供了一些基线。与最先进的方法相比,我们提供了一些基线。此外,我们还提供了一个使用自监督训练的骨干神经网络 resnet。实验证明其强大的表示能力优于 ImageNet 预训练的骨干权重。从我们样本库实际应用的角度来看,我们也使用我们的样本库进行自动判读。我们相信 JSsampleP 将成为卫星和航空图像理解的宝贵基准,促进遥感和地球科学领域的发展。
探索性研究表明,我们仍处于早期阶段。我们比较了不同省份 GCD 和 BSMD 的差异。这将有助于了解是否可以推广使用这两种类型的数据进行样品生产的潜力。
参考文献
- [1] Alemohammad, H., and Booth, K., 2020. LandCoverNet: a global benchmark land cover classification training dataset. arXiv preprint, arXiv:2012.03111.
- [2] Azimi, S.M., et al., 2019. SkyScapes fine-grained semantic understanding of aerial scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 27 October 2 November 2019. Seoul, Korea (South): IEEE, 7393–7403.
- [3] Bastani, F., et al., 2022. Satlas: a large-scale, multi-task dataset for remote sensing image understanding. arXiv preprint, arXiv:2211.15660.
- [4] Basu, S., et al., 2015. DeepSat: a learning framework for satellite imagery. In: Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, 36 November 2015, Seattle, Washington, USA. New York, NY, USA: Association for Computing Machinery, 1–10.
- [5] Boguszewski, A., et al., 2021. LandCover.Ai: dataset for automatic mapping of buildings, woodlands, water and roads from aerial imagery. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVRP) Workshops, 19–25 June 2021. Nashville, TN, USA: IEEE, 1102–1110.
- [6] Campos-Taberner, M., et al., 2020. Understanding deep learning in land use classification based on Sentinel-2 time series. Scientific Reports, 10 (1), 17188. doi:10.1038/s41598-020-74215-5.
- [7] Caron, M., et al., 2020. Unsupervised learning of visual features by contrasting cluster assignments. In: Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020 (NeurIPS 2020), 6–12 December 2020. 9912–9924.
- [9] Chen, L.C., et al., 2017. Rethinking atrous convolution for semantic image segmentation. arXiv preprint, arXiv:1706.05587.
- [10] Chen, Q., et al., 2018. Aerial imagery for roof segmentation: a large-scale dataset towards automatic mapping of buildings. arXiv preprint, arXiv:1807.09532.
- [11] Chen, H., et al., 2022. Semantic-aware dense representation learning for remote sensing image change detection. arXiv preprint, arXiv:2205.13769.
- [12] Cheng, G., Han, J., and Lu, X., 2017. Remote sensing image scene classification: benchmark and state of the art. Proceedings of the IEEE, 105 (10), 1865–1883. doi:10.1109/JPROC.2017.2675998.
- [13] Chen, X., and He, K., 2021. Exploring simple siamese representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 20–25 June 2021. Nashville, TN, USA: IEEE, 15750–15758.
- [14] Chiu, M.T., et al., 2020. Agriculture-vision: a large aerial image database for agricultural pattern analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13–19 June 2020. Seattle, WA, USA: IEEE, 2828–2838.
- [15] Christie, G., et al., 2017. Functional map of the world. arXiv preprint, arXiv:1711.07846.
- [16] Demir, I., et al., 2018. DeepGlobe 2018: a challenge to parse the earth through satellite images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVRP) Workshops, 18–22 June 2018. Salt Lake City, UT, USA: IEEE, 172–181.
- [17] Deng, J., et al., 2009. ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, 20–25 June 2009. Miami, FL, USA: IEEE, 248–255.
- [18] Ding, L., et al., 2022. Looking outside the window: wide-context transformer for the semantic segmentation of high-resolution remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 60, 4410313. doi:10.1109/TGRS.2022.3168697.
- [19] Grill, J.B., et al., 2020. Bootstrap your own latent – a new approach to self-supervised learning. In: Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020 (NeurIPS 2020), 6–12 December 2020. 21271–21284.
- [20] He, K., et al., 2016. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 27–30 June 2016. Las Vegas, Nevada, USA: IEEE, 770–778.
- [21] He, K., et al., 2022. Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 18–24 June 2022. New Orleans, LA, USA: IEEE, 16000–16009.
- [22] Helber, P., et al., 2019. EuroSAT: a novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12 (7), 2217–2226. doi:10.1109/JSTARS.2019.2918242.
- [23] Hu, F., et al., 2015. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sensing, 7 (11), 14680–14707. doi:10.3390/ rs71114680.
- [24] Hua, Y., et al., 2021. Semantic segmentation of remote sensing images with sparse annotations. arXiv preprint, arXiv:2101.03492.
- [25] Ji, S., Wei, S., and Lu, M., 2019. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Transactions on Geoscience and Remote Sensing, 57 (1), 574–586. doi:10.1109/TGRS.2018.2858817.
- [26] Kazemi Garajeh, M., et al., 2022. Developing an integrated approach based on geographic object-based image analysis and convolutional neural network for volcanic and glacial landforms mapping. Scientific Reports, 12 (1), 21396. doi:10.1038/s41598-022-26026-z.
- [27] Lam, D., et al., 2018. xView: objects in context in overhead imagery. arXiv preprint, arXiv:1802.07856.
- [28] Li, Y., 2022. Research and application of deep learning in image recognition. In: 2022 IEEE 2nd International Conference on Power, Electronics and Computer Applications (ICPECA), 2123 January 2022. Shenyang, China: IEEE, 994–999.
- [29] Li, H., et al., 2017. RSI-CB: a large scale remote sensing image classification benchmark via crowdsource data. arXiv preprint, arXiv:1705.10450.
- [30] Li, H., et al., 2018. Pyramid attention network for semantic segmentation. arXiv preprint, arXiv:1805.10180.
- [31] Lu, D., et al., 2022. Multi-scale feature progressive fusion network for remote sensing image change detection. Scientific Reports, 12 (1), 11968. doi:10.1038/s41598-022-16329-6.
- [32] Ma, W., et al., 2022. Semantic clustering based deduction learning for image recognition and classification. Pattern Recognition, 124, 108440. doi:10.1016/j.patcog.2021.108440.
- [33] Marcos, D., et al., 2018. Land cover mapping at very high resolution with rotation equivariant CNNs: towards small yet accurate models. ISPRS Journal of Photogrammetry and Remote Sensing, 145, 96–107. doi:10.1016/j.isprsjprs.2018.01.021.
- [34] Robinson, C., et al., 2019. Large scale high-resolution land cover mapping with multi-resolution data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1519 June 2019. Long Beach, CA, USA: IEEE, 12726–12735.
- [35] Ronneberger, O., Fischer, P., and Brox, T., 2015. U-net: convolutional networks for biomedical image segmentation. In: 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), 5–9 October 2015, Munich, Germany. 234–241.
- [36] Sertel, E., et al., 2022. Land use and land cover mapping using deep learning based segmentation approaches and VHR worldview-3 images. Remote Sensing, 14 (18), 4558. doi:10.3390/rs14184558.
- [37] Sumbul, G., et al., 2019. Bigearthnet: a large-scale benchmark archive for remote sensing image understanding. In: IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, 28 July 2019 – 02 August 2019. Yokohama, Japan: IEEE, 5901–5904.
- [38] Tarasiou, M., Güler, R.A., and Zafeiriou, S., 2022. Context-self contrastive pretraining for crop type semantic segmentation. IEEE Transactions on Geoscience and Remote Sensing, 60, 4413317. doi:10.1109/TGRS.2022.3198187.
- [39] Tarasiou, M., and Zafeiriou, S., 2022. Embedding earth: self-supervised contrastive pre-training for dense land cover classification. arXiv preprint, arXiv:2203.06041.
- [40] Tong, X.Y., et al., 2020. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sensing of Environment, 237, 111322. doi:10.1016/j.rse.2019.111322.
- [41] Vali, A., Comai, S., and Matteucci, M., 2020. Deep learning for land use and land cover classification based on hyperspectral and multispectral earth observation data: a review. Remote Sensing, 12 (15), 2495. doi:10.3390/rs12152495.
- [42] Van Gansbeke, W., et al., 2021. Unsupervised semantic segmentation by contrasting object mask proposals. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 1117 October 2021. IEEE, 10052–10062.
- [43] Volpi, M. and Ferrari, V., 2015. Semantic segmentation of urban scenes by learning local class interactions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 7–12 June 2015. Boston, MA, USA: IEEE, 1–9.
- [44] Wang, J., et al., 2021a. LoveDA: a remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv preprint, arXiv:2110.08733.
- [45] Wang, X., et al., 2021b. Dense contrastive learning for self-supervised visual pre-training. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 June 2021. Nashville, TN, USA: IEEE, 3024–3033.
- [46] Wang, D., et al., 2022a. Advancing plain vision transformer towards remote sensing foundation model. IEEE Transactions on Geoscience and Remote Sensing. doi:10.1109/TGRS.2022.3222818.
- [47] Wang, L., et al., 2022b. UNetFormer: a UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS Journal of Photogrammetry and Remote Sensing, 190, 196–214. doi:10.1016/j.isprsjprs.2022.06.008. Wang, Y., et al., 2022c. Self-supervised learning in remote sensing: a review. arXiv preprint, arXiv:2206.13188.
- [48] Waqas Zamir, S., et al., 2019. iSAID: a large-scale dataset for instance segmentation in aerial images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 15–20 June 2019. Long Beach, CA, USA: IEEE, 28–37.
- [49] Weir, N., et al., 2019. SpaceNet MVOI: a multi-view overhead imagery dataset. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 27 October 2019 – 2 November 2019. Seoul, Korea (South): IEEE, 992–1001.
- [50] Xia, G.S., et al., 2017. AID: a benchmark data set for performance evaluation of aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing, 55 (7), 3965–3981. doi:10. 1109/TGRS.2017.2685945.
- [51] Xia, G.S., et al., 2018. DOTA: a large-scale dataset for object detection in aerial images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 18–23 June 2018. Salt Lake City, UT, USA: IEEE, 3974–3983.
- [52] Xie, Z., et al., 2021. Propagate yourself: exploring pixel-level consistency for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 20–25 June 2021. Nashville, TN, USA: IEEE, 16684–16693.
- [53] Xie, Z., et al., 2022. SimMIM: a simple framework for masked image modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 18–24 June 2022. New Orleans, LA, USA: IEEE, 9653–9663.
- [54] Yang, Y. and Newsam, S., 2010. Bag-of-visual-words and spatial extensions for land-use classification. In: Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, 2–5 November 2010, San Jose, California, USA. New York, NY, USA: Association for Computing Machinery, 270–279.
- [55] Zhao, H., et al., 2017. Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 21–26 July 2017. Honolulu, Hawaii, USA: IEEE, 2881–2890.