NLP预训练模型【5】 – T r a n s f o r m e r Transformer T r an s f or m er
《 A t t e n t i o n Attention A tt e n t i o n 是一篇Google提出的将 A t t e n t i o n Attention A tt e n t i o n T r a n s f o r m e r Transformer T r an s f or m er T r a n s f o r m e r Transformer T r an s f or m er
2.1 总体结构
T r a n s f o r m e r Transformer T r an s f or m er A t t e n t i o n Attention A tt e n t i o n T r a n s f o r m e r Transformer T r an s f or m er E n c o e r − D e c o d e r Encoer- Decoder E n coer − Deco d er A t t e n t i o n Attention A tt e n t i o n E n c o d e r Encoder E n co d er E n c o d e r Encoder E n co d er D e c o d e r Decoder Deco d er
不了解 A t t e n t i o n Attention A tt e n t i o n
每一个 E n c o d e r Encoder E n co d er D e c o d e r Decoder Deco d er
E n c o d e r Encoder E n co d er s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n D e c o d e r Decoder Deco d er E n c o d e r Encoder E n co d er A t t e n t i o n Attention A tt e n t i o n
2.2 E n c o d e r Encoder E n co d er
首先,模型需要对输入的数据进行一个 E m b e d d i n g Embedding E mb e dd in g w o r d 2 v e c word2vec w or d 2 v ec E m b e d d i n g Embedding E mb e dd in g E n c o d e r Encoder E n co d er s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n E n c o d e r Encoder E n co d er
2.2.1 Positional Encoding
T r a n s f o r m e r Transformer T r an s f or m er T r a n s f o r m e r Transformer T r an s f or m er E n c o d e r Encoder E n co d er D e c o d e r Decoder Deco d er P o s i t i o n a l E n c o d i n g Positional \quad Encoding P os i t i o na l E n co d in g E m b e d d i n g Embedding E mb e dd in g
P E ( p o s , 2 i ) = sin ( p o s 10000 1 d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( pos 10000 1 i d m o d e l ) \begin{equation}
\begin{aligned}
P E(p o s, 2 i)&=\sin \left(\frac{p o s}{10000^{\frac{1}{d_{m o d e l}}}}\right) \\\\
P E(p o s, 2 i+1)&=\cos \left(\frac{\text { pos }}{10000^{\frac{1 i}{d_{m o d e l}}}}\right)
\end{aligned}
\end{equation}
PE ( p os , 2 i ) PE ( p os , 2 i + 1 ) = sin ( 1000 0 d m o d e l 1 p os ) = cos ( 1000 0 d m o d e l 1 i pos )
其中 p o s pos p os i i i i n d e x index in d e x 偶数位置,使用正弦编码,在奇数位置,使用余弦编码 。
最后把这个 P o s i t i o n a l E n c o d i n g Positional Encoding P os i t i o na lE n co d in g E m b e d d i n g Embedding E mb e dd in g
2.2.2 S e l f − A t t e n t i o n Self- Attention S e l f − A tt e n t i o n
接下来我们详细看一下 s e l f − A t t e n t i o n self- Attention se l f − A tt e n t i o n A t t e n t i o n Attention A tt e n t i o n s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n T r a n s f o r m e r Transformer T r an s f or m er
The animal didn’t cross the street because it was too tired
这里的 it 到底代表的是 animal 还是 street 呢,对于我们来说能很简单的判断出来,但是对于机器来说,是很难判断的,s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n
首先,s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n Q u e r y Query Q u ery K e y Key Key V a l u e Value Va l u e E m b e d d i n g Embedding E mb e dd in g E m b e d d i n g Embedding E mb e dd in g
然后,计算 s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n E n c o d e Encode E n co d e Q u e r y Query Q u ery K e y Key Key q 1 ⋅ k 1 q_1·k_1 q 1 ⋅ k 1 q 1 ⋅ k 2 q_1·k_2 q 1 ⋅ k 2
接下来,把点乘的结果除以一个常数,这里我们除以 8 ,这个值一般是采用上文提到的矩阵的第一个维度的开方即 64 的开方 8 ,当然也可以选择其他的值,然后把得到的结果做一个 s o f t m a x softmax so f t ma x
下一步就是把 V a l u e Value Va l u e s o f t m a x softmax so f t ma x s e l f − a t t e n t i o n self-attention se l f − a tt e n t i o n
在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出 Q u e r y Query Q u ery K e y Key Key V a l u e Value Va l u e E m b e d d i n g Embedding E mb e dd in g s o f t m a x softmax so f t ma x
这种通过 Q u e r y Query Q u ery K e y Key Key V a l u e Value Va l u e
2.2.3 Multi-Headed A t t e n t i o n Attention A tt e n t i o n
这篇论文更牛逼的地方是给 s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n M u l t i − H e a d e r A t t e n t i o n Multi-Header \quad Attention M u lt i − He a d er A tt e n t i o n 就是说不仅仅只初始化一组 Q 、 K 、 V Q、K、V Q 、 K 、 V T r a n f o r m e r Tranformer T r an f or m er ,所以最后得到的结果是 8 个矩阵。
2.2.4 Layer normalization
在 T r a n s f o r m e r Transformer T r an s f or m er s e l f − a t t e n t i o n self-attention se l f − a tt e n t i o n F e e d F o r w a r d N e u r a l N e t w o r k Feed \quad Forward \quad Neural \quad Network F ee d F or w a r d N e u r a l N e tw or k L a y e r N o r m a l i z a t i o n Layer \quad Normalization L a yer N or ma l i z a t i o n
N o r m a l i z a t i o n Normalization N or ma l i z a t i o n n o r m a l i z a t i o n normalization n or ma l i z a t i o n
Batch Normalization
BN 的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。BN 的具体做法就是对每一小批数据,在批这个方向上做归一化。
Layer normalization
它也是归一化数据的一种方式,不过** LN 是在每一个样本上计算均值和方差**,而不是 BN 那种在批方向计算均值和方差!公式如下:
L N ( x i ) = α ∗ x i − μ L σ L 2 + ε + β L N\left(x_{i}\right)=\alpha * \frac{x_{i}-\mu_{L}}{\sqrt{\sigma_{L}^{2}+\varepsilon}}+\beta
L N ( x i ) = α ∗ σ L 2 + ε x i − μ L + β
2.2.5 Feed Forward Neural Network
这给我们留下了一个小的挑战,前馈神经网络没法输入 8 个矩阵呀,这该怎么办呢?所以我们需要一种方式,把 8 个矩阵降为 1 个,首先,我们把 8 个矩阵连在一起,这样会得到一个大的矩阵,再随机初始化一个矩阵和这个组合好的矩阵相乘,最后得到一个最终的矩阵。
2.3 D e c o d e r Decoder Deco d er
根据上面的总体结构图可以看出, D e c o d e r Decoder Deco d er E n c o d e r Encoder E n co d er P o s i t i o n a l E n c o d i n g Positional \quad Encoding P os i t i o na l E n co d in g M a s k e d M u t i l − h e a d A t t e n t i o n Masked \quad Mutil-head \quad Attention M a s k e d M u t i l − h e a d A tt e n t i o n m a s k mask ma s k T r a n s f o r m e r Transformer T r an s f or m er
其余的层结构与 E n c o d e r Encoder E n co d er E n c o d e r Encoder E n co d er
2.3.1 Masked Mutil-head Attention
mask表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果 。 T r a n s f o r m e r Transformer T r an s f or m er m a s k mask ma s k p a d d i n g m a s k padding \quad mask p a dd in g ma s k s e q u e n c e m a s k sequence \quad mask se q u e n ce ma s k p a d d i n g m a s k padding \quad mask p a dd in g ma s k s c a l e d d o t − p r o d u c t A t t e n t i o n scaled dot-product Attention sc a l e dd o t − p ro d u c t A tt e n t i o n s e q u e n c e m a s k sequence \quad mask se q u e n ce ma s k D e c o d e r Decoder Deco d er s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n
(1) p a d d i n g m a s k padding \quad mask p a dd in g ma s k
什么是 p a d d i n g m a s k padding \quad mask p a dd in g ma s k A t t e n t i o n Attention A tt e n t i o n
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 s o f t m a x softmax so f t ma x
而我们的 p a d d i n g m a s k padding \quad mask p a dd in g ma s k
(2) s e q u e n c e m a s k sequence \quad mask se q u e n ce ma s k
文章前面也提到, s o f t m a x softmax so f t ma x D e c o d e r Decoder Deco d er
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的 。
对于 D e c o d e r Decoder Deco d er s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n p a d d i n g m a s k padding \quad mask p a dd in g ma s k s e q u e n c e m a s k sequence \quad mask se q u e n ce ma s k a t t n − m a s k attn-mask a tt n − ma s k m a s k mask ma s k a t t n − m a s k attn-mask a tt n − ma s k
其他情况,a t t n − m a s k attn-mask a tt n − ma s k p a d d i n g m a s k padding \quad mask p a dd in g ma s k
2.3.2 Output层
当 D e c o d e r Decoder Deco d er s o f t m a x softmax so f t ma x s o f t m a x softmax so f t ma x
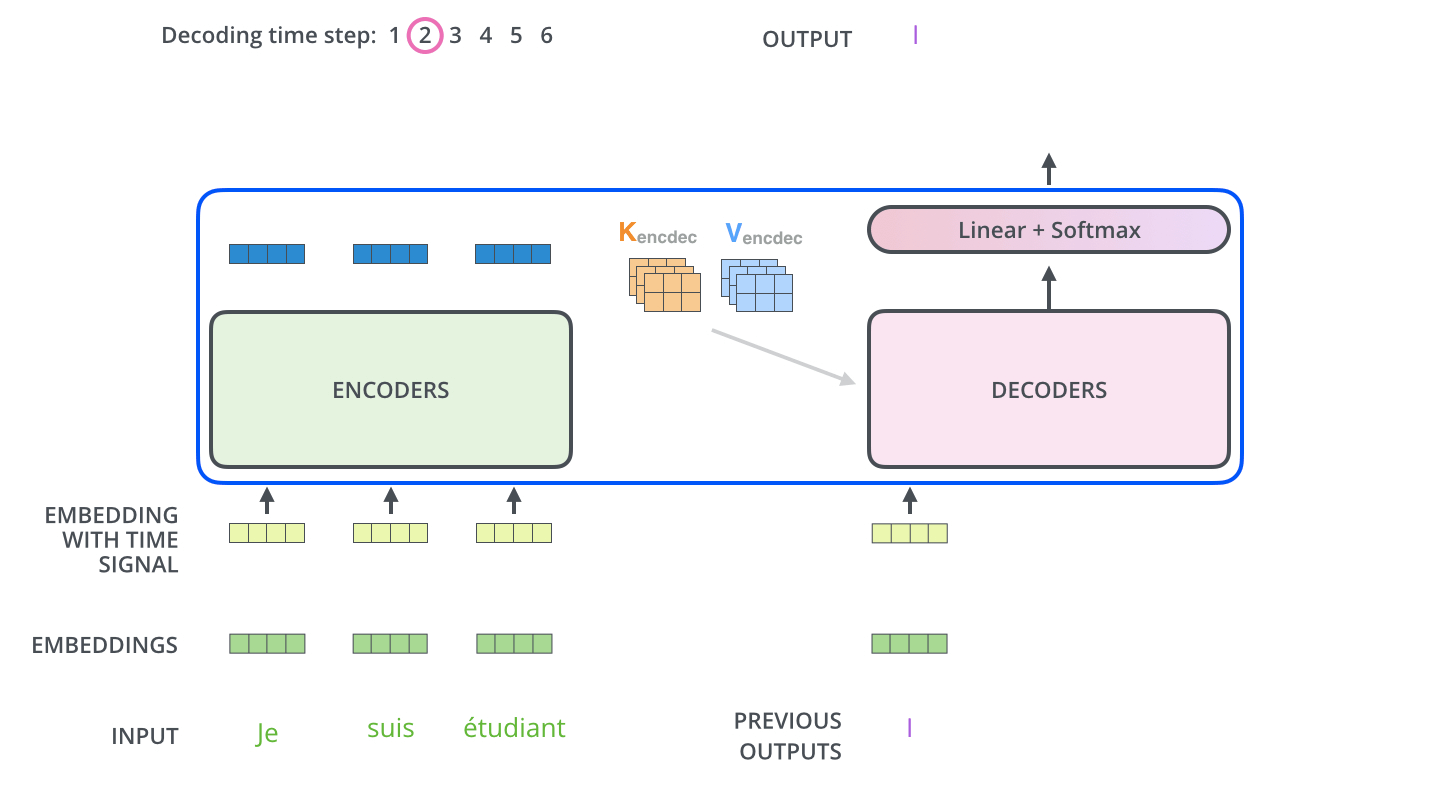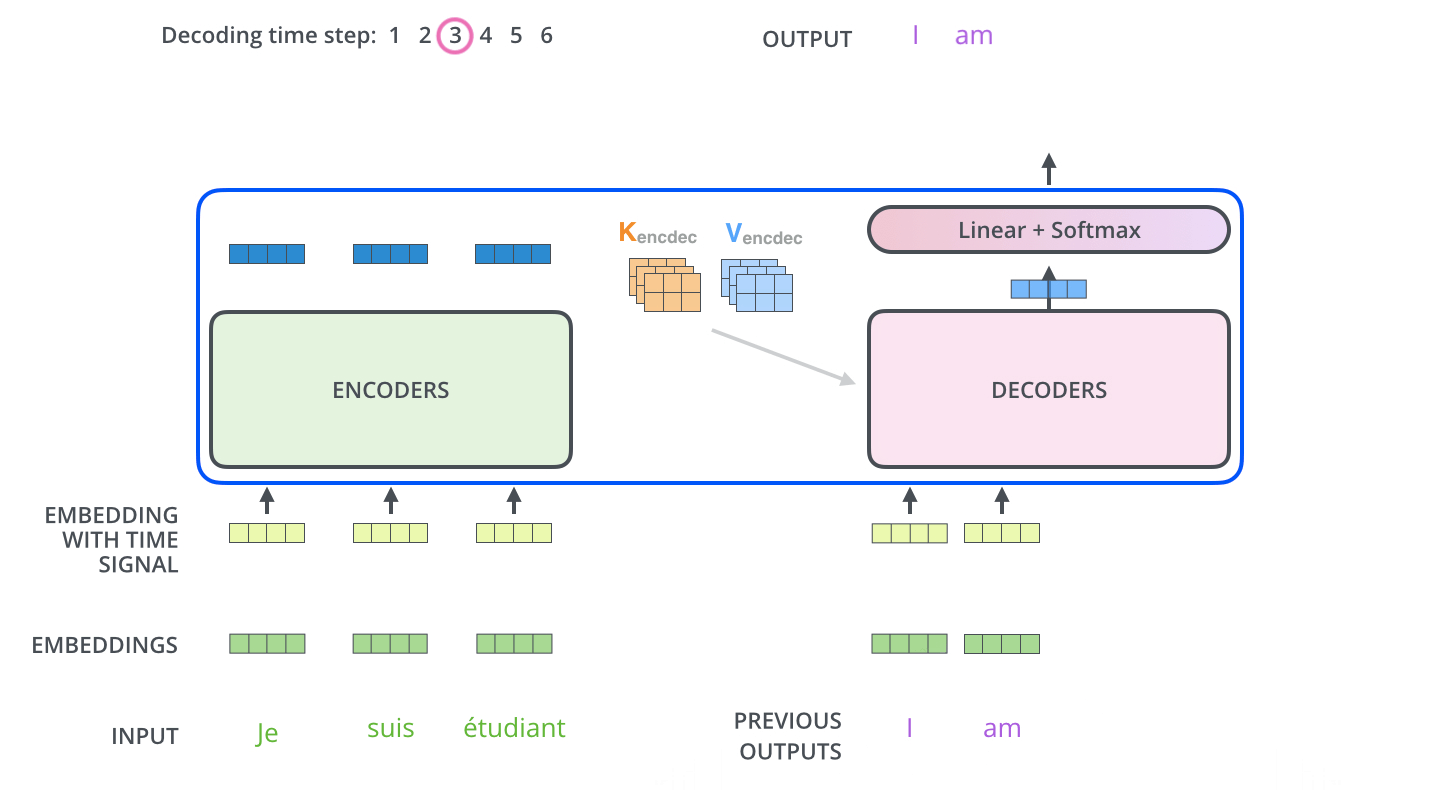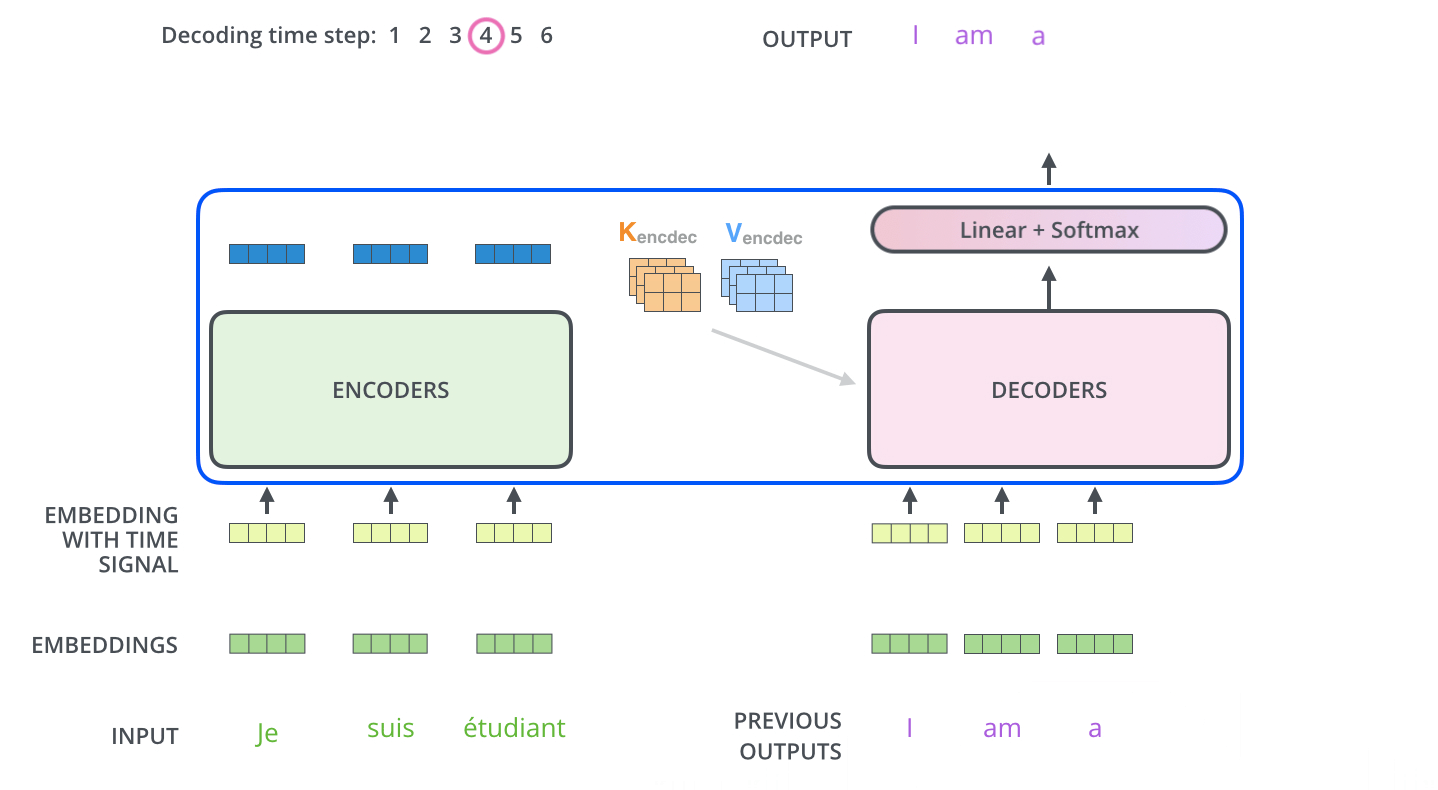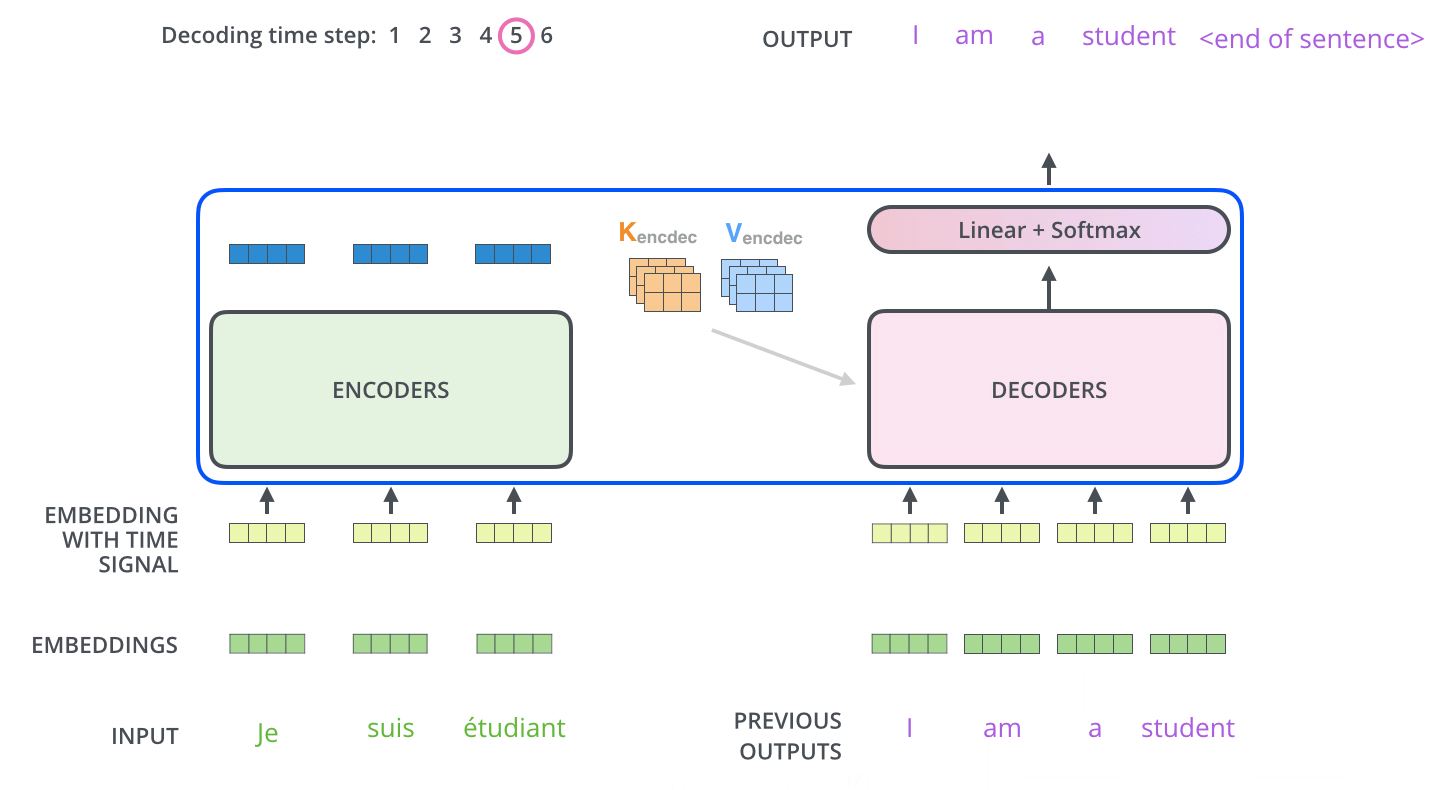
2.4 动态流程图
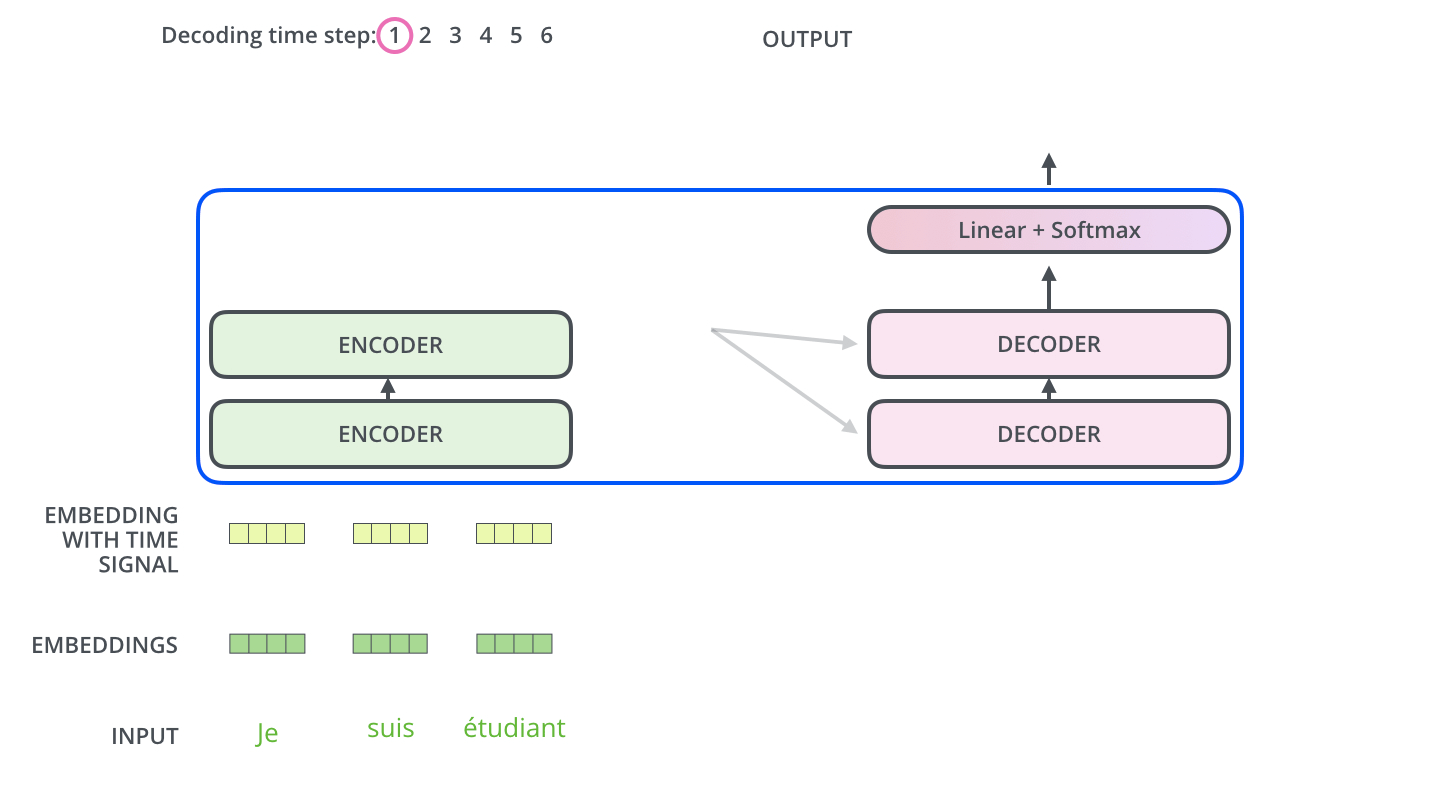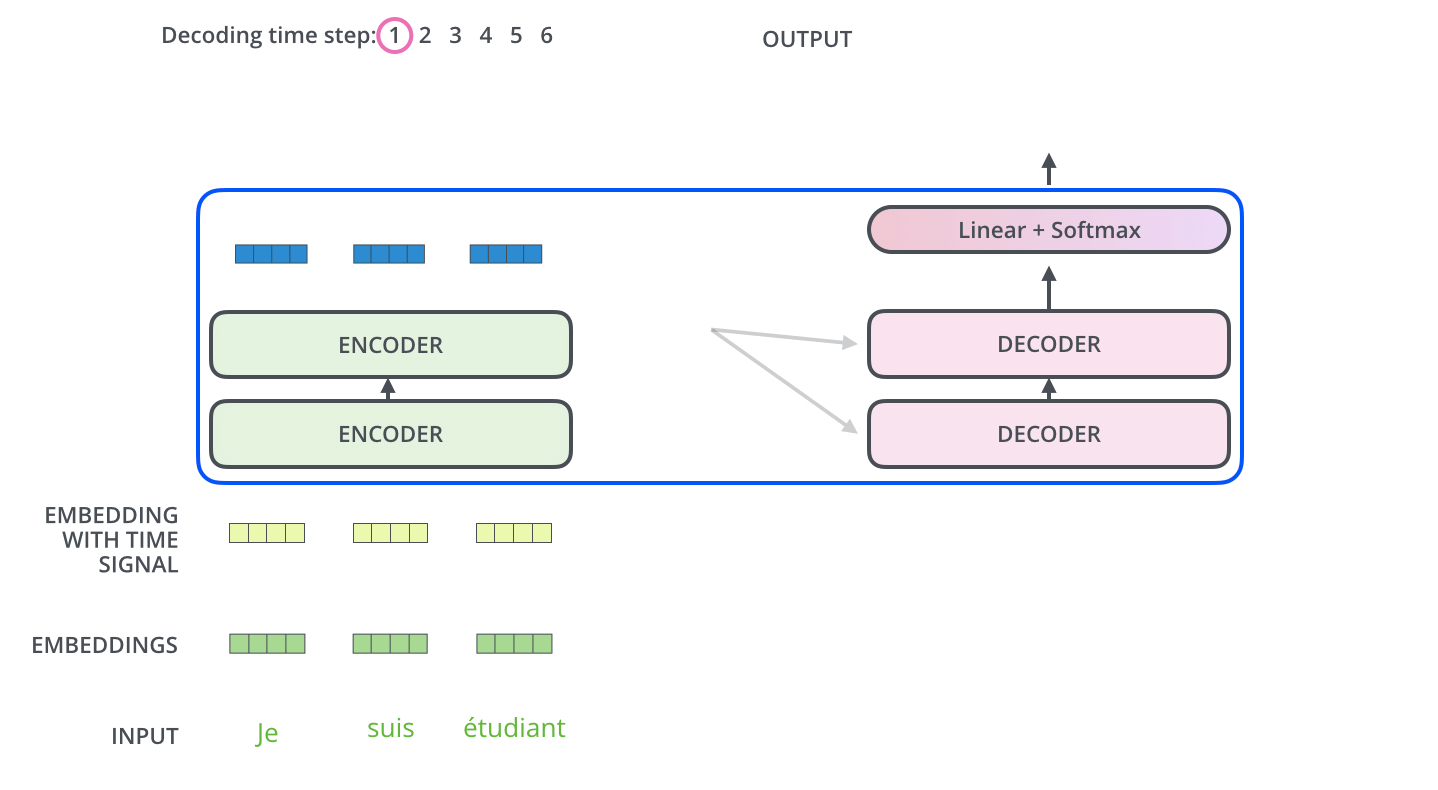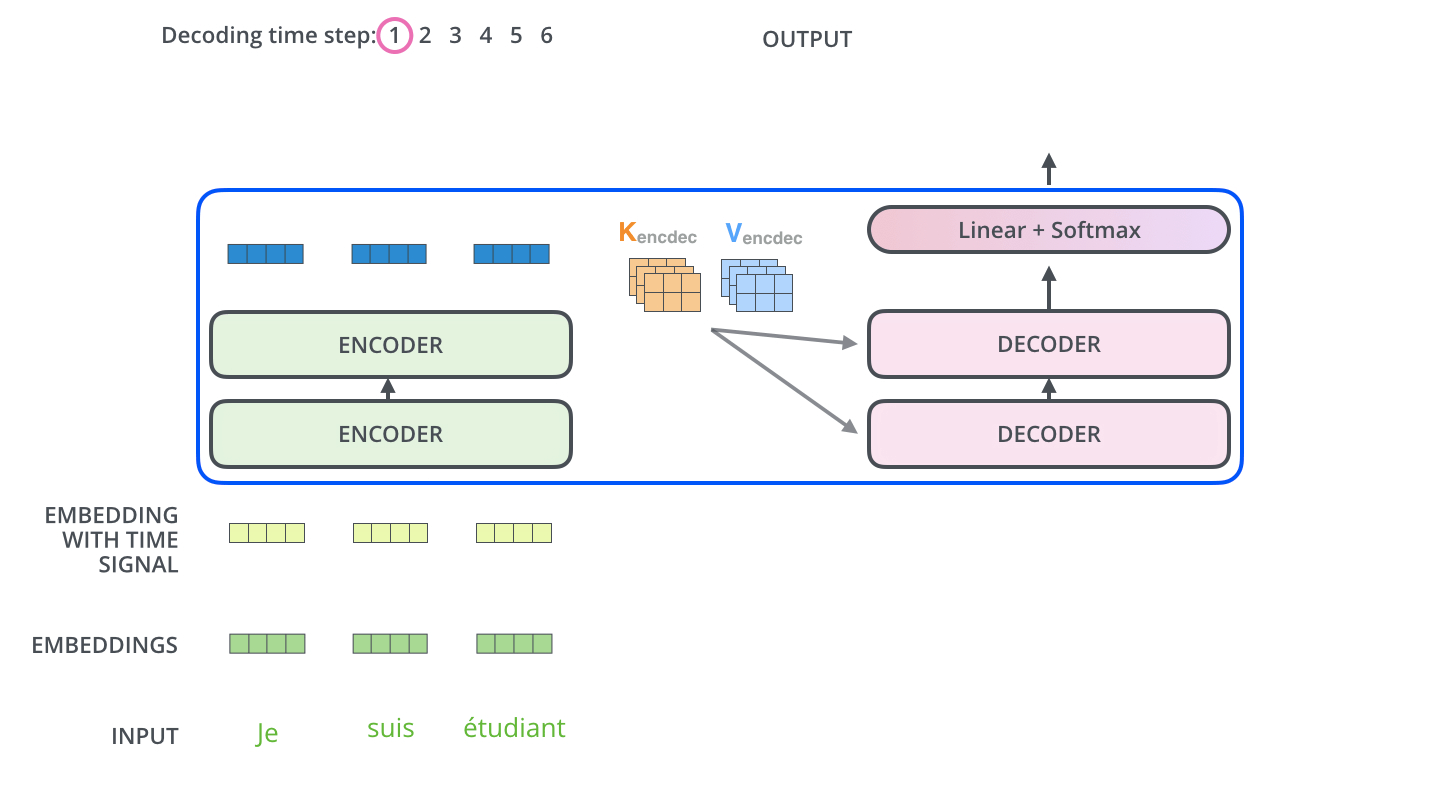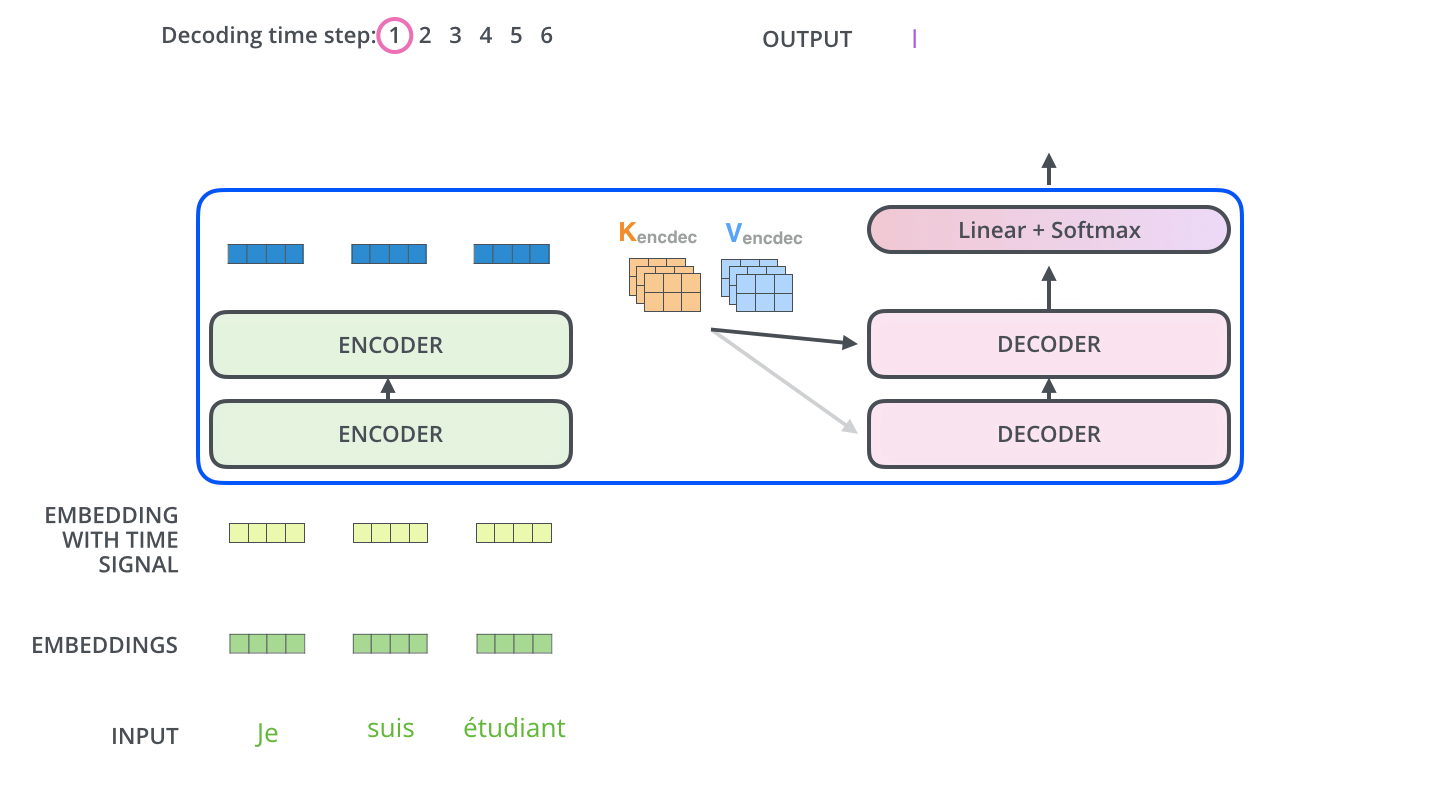
编码器通过处理输入序列开启工作。顶端编码器的输出之后会变转化为一个包含向量 K K K V V V 这是并行化操作 。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列哪些位置合适:
在完成编码阶段后,则开始解码阶段。解码阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素。
接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示 T r a n s f o r m e r Transformer T r an s f or m er
原论文中说到进行 M u l t i − h e a d A t t e n t i o n Multi-head \quad Attention M u lt i − h e a d A tt e n t i o n A t t e n t i o n Attention A tt e n t i o n A t t e n t i o n Attention A tt e n t i o n 多个卷积核 的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息 。
(1)R N N RNN RNN R N N RNN RNN T T T T − 1 T-1 T − 1 T − 1 T-1 T − 1 T − 2 T-2 T − 2
(2) T r a n s f o r m e r Transformer T r an s f or m er R N N RNN RNN
具体实验对比可以参考:放弃幻想,全面拥抱Transformer :自然语言处理三大特征抽取器(CNN/RNN/TF)比较
但是值得注意的是,并不是说 T r a n s f o r m e r Transformer T r an s f or m er R N N RNN RNN R N N RNN RNN
s e q 2 s e q seq2seq se q 2 se q s e q 2 s e q seq2seq se q 2 se q s e q 2 s e q seq2seq se q 2 se q 将 E n c o d e r Encoder E n co d er ,并将其作为 D e c o d e r Decoder Deco d er D e c o d e r Decoder Deco d er E n c o d e r Encoder E n co d er D e c o d e r Decoder Deco d er D e c o d e r Decoder Deco d er
T r a n s f o r m e r Transformer T r an s f or m er T r a n s f o r m e r Transformer T r an s f or m er s e q 2 s e q seq2seq se q 2 se q A t t e n t i o n Attention A tt e n t i o n s e l f − A t t e n t i o n self-Attention se l f − A tt e n t i o n E m b e d d i n g Embedding E mb e dd in g F F N FFN FFN T r a n s f o r m e r Transformer T r an s f or m er s e q 2 s e q seq2seq se q 2 se q T r a n s f o r m e r Transformer T r an s f or m er s e q 2 s e q seq2seq se q 2 se q
6. 代码实现
地址:https://github.com/Kyubyong/Transformer
代码解读: Transformer 解析与tensorflow代码解读
7. 参考文献
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP