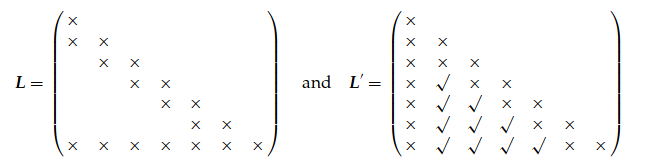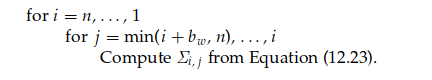【摘 要】在空间统计学中,面元数据的空间统计建模通常是采用马尔可夫随机场实施的。本文针对单随机变量(随机过程)情况,介绍了其定义、性质、推断方法、分布的计算等内容,尤其突出了高斯马尔可夫随机场(GMRF)。内容摘自 Gelfand 的 《空间统计手册》第十二章。
【原 文】 Gelfand, A.E. et al. (2010), Handbook of spatial statistics (chapter 12). CRC press.
空间随机变量的有限集合的统计建模,通常通过马尔可夫随机场 (MRF) 完成。 MRF 是通过一组条件分布来指定的,其中每一个条件对应于某个分量在给定其他分量时的条件分布。这使人们能够每次只专注于单个随机变量,并导致了基于模拟的简单 MRF 计算程序,特别是利用马尔可夫链蒙特卡罗 (MCMC) 进行贝叶斯推断。
本章的主要目的是全面介绍高斯马尔可夫随机场( GMRF )的情况,重点是通用性质和高效计算方法。示例和应用将会出现在 第 13 章 和 第 14 章。我们将在本章最后讨论联合分布不是高斯的一般情况,特别是著名的 Hammersley-Clifford 定理。
涉及本章的主要参考文献:
Rue 和 Held (2005) 的专著对 GMRF 给出了现代和一般性的参考;
对于更一般的马尔可夫随机场,大家可以参考 Guyon (1995) 和 Lauritzen (1996) 的方法背景和 Li (2001) 的图像空间应用分析;当然,J. Besag (1974, 1975) 的开创性论文仍然值得一读。
12.1 符号
x = ( x 1 , … , x n ) ⊤ \mathbf{x} = (x_1,\ldots ,x_n)^{\top} x = ( x 1 , … , x n ) ⊤ n n n x i x_i x i i i i x A = { x i : i ∈ A } \mathbf{x}_A = \{ x_i : i \in A\} x A = { x i : i ∈ A } x − A = { x i : i ∉ A } \mathbf{x}_{-A} =\{x_i : i \notin A\} x − A = { x i : i ∈ / A } x i : j = ( x i , … , x j ) ⊤ , j ≥ i \mathbf{x}_{i : j} = (x_i ,\ldots ,x_j )^{\top},\quad j \geq i x i : j = ( x i , … , x j ) ⊤ , j ≥ i 用 π ( ⋅ ) \pi(\cdot) π ( ⋅ ) π ( ⋅ ∣ ⋅ ) \pi(\cdot | \cdot) π ( ⋅ ∣ ⋅ ) π ( x ) \pi(\mathbf{x}) π ( x ) π ( x i ∣ x − i ) \pi(x_i |\mathbf{x}_{-i}) π ( x i ∣ x − i )
高斯分布用 N ( μ , Σ ) \mathcal{N}(\boldsymbol{\mu,\Sigma}) N ( μ , Σ ) x \mathbf{x} x N ( x ; μ , Σ ) \mathcal{N}(\mathbf{x};\boldsymbol{\mu,\Sigma}) N ( x ; μ , Σ ) μ \boldsymbol{\mu} μ Σ \boldsymbol{\Sigma} Σ
缩写 SPD 表示 对称正定矩阵
矩阵 ∣ A ∣ |\mathbf{A}| ∣ A ∣ i i i j j j A i , j ≠ 0 A_{i,j} \neq 0 A i , j = 0 max ∣ i − j ∣ \max |i − j| max ∣ i − j ∣
12.2 高斯马尔可夫随机场( GMRF )
12.2.1 定义
我们将首先一般性地讨论 GMRF,然后稍后讨论其条件分布的定义。 GMRF 是一个高斯分布的随机向量 x \mathbf{x} x i ≠ j i \neq j i = j
x i ⊥ x j ∣ x − ( i , j ) (12.1) x_i \perp x_j | \mathbf{x}_{-(i,j)} \tag{12.1}
x i ⊥ x j ∣ x − ( i , j ) ( 12.1 )
上式意味着:如果以 x − ( i , j ) \mathbf{x}_{-(i,j)} x − ( i , j ) x i x_i x i x j x_j x j
这种条件独立性可以使用(无向)有标签图 G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G = ( V , E ) V = { 1 , … , n } \mathcal{V} =\{1,\ldots ,n\} V = { 1 , … , n } E = { { i , j } : i , j ∈ V } \mathcal{E} =\left \{\{i, j\} : i, j \in \mathcal{V} \right \} E = { { i , j } : i , j ∈ V } i , j ∈ V i, j \in \mathcal{V} i , j ∈ V 式(12.1) 成立,则边 { i , j } \{i, j\} { i , j } E \mathcal{E} E
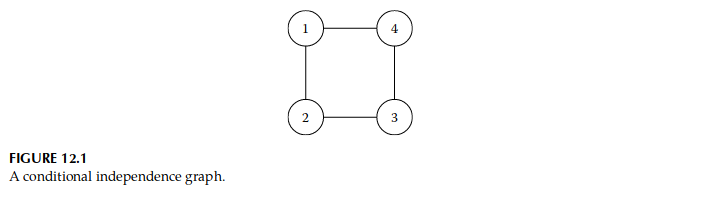
图 12.1 显示了这样一个图,其中 n = 4 n = 4 n = 4 E = { { 1 , 2 } , { 2 , 3 } , { 3 , 4 } , { 4 , 1 } } \mathcal{E} = \left \{\{1, 2\}, \{2, 3\}, \{3, 4\}, \{4, 1\} \right \} E = { { 1 , 2 } , { 2 , 3 } , { 3 , 4 } , { 4 , 1 } } x 2 ⊥ x 4 ∣ x 1 , 3 x_2 \perp x_4|\mathbf{x}_{1,3} x 2 ⊥ x 4 ∣ x 1 , 3 x 1 ⊥ x 3 ∣ x 2 , 3 x_1 \perp x_3|\mathbf{x}_{2,3} x 1 ⊥ x 3 ∣ x 2 , 3 G \mathcal{G} G x \mathbf{x} x x \mathbf{x} x Q = Σ − 1 \mathbf{\mathbf{Q}} = \boldsymbol{\Sigma}^{-1} Q = Σ − 1
【定理 12.1】
设 x \mathbf{x} x Q \mathbf{Q} Q i ≠ j i \neq j i = j
x i ⊥ x j ∣ x − ( i , j ) ⇔ Q i , j = 0 x_i \perp x_j | \mathbf{x}_{-(i,j)} \Leftrightarrow \mathbf{Q}_{i,j} = 0
x i ⊥ x j ∣ x − ( i , j ) ⇔ Q i , j = 0
因此,任何具有 Q 2 , 4 = Q 4 , 2 = Q 1 , 3 = Q 3 , 1 = 0 \mathbf{Q}_{2,4} = \mathbf{Q}_{4,2} = \mathbf{Q}_{1,3} = \mathbf{Q}_{3,1} = 0 Q 2 , 4 = Q 4 , 2 = Q 1 , 3 = Q 3 , 1 = 0 Q \mathbf{Q} Q 图 12.1 所示的条件独立性质。我们通常称 x \mathbf{x} x G \mathcal{G} G
【定义 12.1 (GMRF)】
随机向量 x = ( x 1 , … , x n ) ⊤ ∈ R n \mathbf{x} = (x_1,\ldots ,x_n)^{\top} \in \mathbb{R}^n x = ( x 1 , … , x n ) ⊤ ∈ R n G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G = ( V , E ) μ \boldsymbol{\mu} μ Q \mathbf{Q} Q
π ( x ) = ( 2 π ) − n / 2 ∣ Q ∣ 1 / 2 exp ( − 1 2 ( x − μ ) ⊤ Q ( x − μ ) ) (12.2) \pi(\mathbf{x}) = (2\pi)^{−n/2} |\mathbf{Q}|^{1/2} \exp \left(-\frac{1}{2} (\mathbf{x} − \boldsymbol{\mu})^{\top} \mathbf{Q}(\mathbf{x} − \boldsymbol{\mu}) \right ) \tag{12.2}
π ( x ) = ( 2 π ) − n /2 ∣ Q ∣ 1/2 exp ( − 2 1 ( x − μ ) ⊤ Q ( x − μ ) ) ( 12.2 )
其中对于所有 i ≠ j i \neq j i = j Q i , j ≠ 0 ⇔ { i , j } ∈ E \mathbf{Q}_{i,j} \neq 0 \Leftrightarrow \{ i , j\} \in \mathcal{E} Q i , j = 0 ⇔ { i , j } ∈ E
当精度矩阵 Q \mathbf{Q} Q 第 13 章 和 第 14 章 中将讨论的本征自回归。
下面是一个(正确的)GMRF 示例。
【示例 12.1】
令 { x t } \{x_t\} { x t } t = 2 , … , n t = 2,\ldots ,n t = 2 , … , n x t ∣ x t − 1 = ϕ x t − 1 + ϵ t x_t|x_{t-1} = \phi x_{t-1} + \epsilon_t x t ∣ x t − 1 = ϕ x t − 1 + ϵ t ∣ ϕ ∣ < 1 |\phi| < 1 ∣ ϕ ∣ < 1 ϵ t \epsilon_t ϵ t x 1 x_1 x 1 1 / ( 1 − ϕ 2 ) 1/(1−\phi^2) 1/ ( 1 − ϕ 2 ) x \mathbf{x} x G \mathcal{G} G E = { { 1 , 2 } , { 2 , 3 } , … , { n − 1 , n } } \mathcal{E} =\left \{\{1, 2\}, \{2, 3\},\ldots , \{n − 1,n\} \right \} E = { { 1 , 2 } , { 2 , 3 } , … , { n − 1 , n } } ∣ i − j ∣ = 1 |i − j |=1 ∣ i − j ∣ = 1 Q i , j = − ϕ \mathbf{Q}_{i,j} = −\phi Q i , j = − ϕ Q 1 , 1 = Q n , n = 1 \mathbf{Q}_{1,1} = \mathbf{Q}_{n,n} = 1 Q 1 , 1 = Q n , n = 1 i = 2 , … , n − 1 i = 2,\ldots ,n− 1 i = 2 , … , n − 1 Q i i = 1 + ϕ 2 \mathbf{Q}_{ii} = 1 + \phi^2 Q ii = 1 + ϕ 2
这个例子很好地说明了为什么 GMRF 非常有用:
首先,对于滞后为 k k k ϕ ∣ k ∣ \phi^{|k|} ϕ ∣ k ∣ x \mathbf{x} x
其次,精度矩阵足够稀疏,在 Q \mathbf{Q} Q n 2 n^2 n 2 n + 2 ( n − 1 ) = 3 n − 2 n + 2(n − 1) = 3n − 2 n + 2 ( n − 1 ) = 3 n − 2
需要注意的是:稀疏精度矩阵使得用于模拟自回归过程的快速 O ( n ) \mathcal{O}(n) O ( n )
12.3 基本性质
12.3.1 条件性质
虽然 GMRF 可以看作是一般的多元高斯随机变量,但某些性质会被简化,某些特征会更容易计算。最直观的一点就是:由于精度矩阵的稀疏性,使得条件分布更容易计算了。为了看到这一点,我们先将结点集 V \mathcal{V} V A \mathbf{A} A B = − A B = −A B = − A x \mathbf{x} x μ \boldsymbol{\mu} μ Q \mathbf{Q} Q
x = ( x A x B ) , μ = ( μ A μ B ) , Q = ( Q A A Q A B Q B A Q B B ) \mathbf{x}= \binom{ \mathbf{x}_A}{ \mathbf{x}_B}, \boldsymbol{\mu} = \binom{\boldsymbol{\mu}_A}{\boldsymbol{\mu}_B} , \mathbf{Q} = \begin{pmatrix} \mathbf{Q}_{AA} & \mathbf{Q}_{AB}\\ \mathbf{Q}_{BA} & \mathbf{Q}_{BB} \end{pmatrix}
x = ( x B x A ) , μ = ( μ B μ A ) , Q = ( Q AA Q B A Q A B Q BB )
此外,我们还需要具有子图的概念。子图 G A \mathcal{G}^A G A A A A A A A A A A
有了上述概念,下面的定理成立。
【定理 12.2】
令 x \mathbf{x} x G \mathcal{G} G μ \boldsymbol{\mu} μ Q \mathbf{Q} Q A ⊂ V A \subset \mathcal{V} A ⊂ V B = V ∖ A B = \mathcal{V} \setminus A B = V ∖ A A , B ≠ ∅ A,B \neq \emptyset A , B = ∅ x A ∣ x B \mathbf{x}_A|\mathbf{x}_B x A ∣ x B G A \mathcal{G}^A G A μ A ∣ B \boldsymbol{\mu}_{A|B} μ A ∣ B Q A ∣ B \mathbf{Q}_{A|B} Q A ∣ B
μ A ∣ B = μ A − Q A A − 1 Q A B ( x B − μ B ) 和 Q A ∣ B = Q A A \boldsymbol{\mu}_{A|B} = \boldsymbol{\mu}_A − \mathbf{Q}^{-1}_{AA} \mathbf{Q}_{AB} (\mathbf{x}_B − \boldsymbol{\mu}_B) \quad \text{和} \quad \mathbf{Q}_{A|B} = \mathbf{Q}_{AA}
μ A ∣ B = μ A − Q AA − 1 Q A B ( x B − μ B ) 和 Q A ∣ B = Q AA
【备注 12.1】 请注意,此结果只是采用了高斯条件分布的另一种视角。事实上,我们通常也会使用协方差矩阵 Σ \boldsymbol{\Sigma} Σ
Σ = ( Σ A A Σ A B Σ B A Σ B B ) \boldsymbol{\Sigma} = \begin{pmatrix} \boldsymbol{\Sigma}_{AA} & \boldsymbol{\Sigma}_{AB}\\ \boldsymbol{\Sigma}_{BA} & \boldsymbol{\Sigma}_{BB} \end{pmatrix}
Σ = ( Σ AA Σ B A Σ A B Σ BB )
根据上述表示,条件分布的协方差矩阵为 Cov ( x A ∣ x B ) = Σ A A − Σ A B Σ B B − 1 Σ B A \operatorname{Cov}(\mathbf{x}_A|\mathbf{x}_B) = \boldsymbol{\Sigma}_{AA} − \boldsymbol{\Sigma}_{AB} \boldsymbol{\Sigma}^{-1}_{BB} \boldsymbol{\Sigma}_{BA} Cov ( x A ∣ x B ) = Σ AA − Σ A B Σ BB − 1 Σ B A Q A A − 1 \mathbf{Q}^{-1}_{AA} Q AA − 1
精度矩阵表示方法 “引人注目” 的特征是:
条件精度矩阵 Q A ∣ B \mathbf{Q}_{A|B} Q A ∣ B Q \mathbf{Q} Q 。因此,条件精度矩阵也是显式可用的,只需删除掉 Q \mathbf{Q} Q B B B Q \mathbf{Q} Q Q A ∣ B \mathbf{Q}_{A|B} Q A ∣ B 条件均值 μ A ∣ B \boldsymbol{\mu}_{A|B} μ A ∣ B Q A A − 1 \mathbf{Q}^{-1}_{AA} Q AA − 1 μ A ∣ B = μ A − b \boldsymbol{\mu}_{A|B} = \boldsymbol{\mu}_A − \mathbf{b} μ A ∣ B = μ A − b ,其中 b \mathbf{b} b Q A A b = Q A B ( x B − μ B ) \mathbf{Q}_{AA} \mathbf{b} = \mathbf{Q}_{AB} (\mathbf{x}_B − \boldsymbol{\mu}_B) Q AA b = Q A B ( x B − μ B ) A A A B B B Q A B \mathbf{Q}_{AB} Q A B 单结点的条件预测形式非常简单 。在只有一个结点的特殊情况 A = { i } A =\{i\} A = { i }
μ i ∣ − i = μ i − ∑ j : j ∼ i Q i , j Q i i ( x j − μ j ) 且 Q i ∣ − i = Q i i (12.3) \mu_{i|−i} = \mu_i − \sum\limits_{j: j \sim i} \frac{ \mathbf{Q}_{i,j}}{\mathbf{Q}_{ii}} (x_j − \mu_j ) \quad \text{且} \quad \mathbf{Q}_{i|−i} = \mathbf{Q}_{ii} \tag{12.3}
μ i ∣ − i = μ i − j : j ∼ i ∑ Q ii Q i , j ( x j − μ j ) 且 Q i ∣ − i = Q ii ( 12.3 )
上式中,符号 j : j ∼ i j : j \sim i j : j ∼ i i i i j j j { i , j } ∈ E \{i, j\} \in \mathcal{E} { i , j } ∈ E x i x_i x i Q i i \mathbf{Q}_{ii} Q ii x i x_i x i x j x_j x j − Q i , j / Q i i −\mathbf{Q}_{i,j}/\mathbf{Q}_{ii} − Q i , j / Q ii
【例 12.2】
重新回顾 例 12.1。此时根据 式(12.3),我们可以得到 x i ∣ x − i x_i |\mathbf{x}_{-i} x i ∣ x − i
μ i ∣ − i = ϕ 1 + ϕ 2 ( x i − 1 + x i + 1 ) 和 Q i ∣ − i = 1 + ϕ 2 , 1 < i < n \mu_{i|-i} = \frac{\phi}{1 + \phi^2} (x_{i−1} + x_{i+1}) \quad \text{和} \quad \mathbf{Q}_{i|-i} = 1 + \phi^2, 1 < i < n
μ i ∣ − i = 1 + ϕ 2 ϕ ( x i − 1 + x i + 1 ) 和 Q i ∣ − i = 1 + ϕ 2 , 1 < i < n
12.3.2 马尔可夫性质
一个 GMRF 的图 G \mathcal{G} G x i x_i x i x j x_j x j 成对马尔可夫性质(pairwise Markov property) 。
但初此之外,我们还可以从图 G \mathcal{G} G
路径(path) :从结点 i 1 i_1 i 1 i m i_m i m V \mathcal{V} V i 1 , i 2 , … , i m i_1,i_2,\ldots ,i_m i 1 , i 2 , … , i m j = 1 , … , m − 1 j = 1,\ldots ,m−1 j = 1 , … , m − 1 ( i j , i j + 1 ) ∈ E (i_j,i_{j+1}) \in \mathcal{E} ( i j , i j + 1 ) ∈ E
分隔 (separate): 对于某个结点子集 C ⊂ V C \subset \mathcal{V} C ⊂ V i ∉ C i \notin C i ∈ / C j ∉ C j \notin C j ∈ / C 路径 中都包含至少一个来自 C C C i i i j j j C C C A ⊂ V ∖ C A \subset \mathcal{V} \setminus C A ⊂ V ∖ C B ⊂ V ∖ C B \subset \mathcal{V} \setminus C B ⊂ V ∖ C i ∈ A i \in A i ∈ A j ∈ B j \in B j ∈ B C C C A A A B B B C C C C C C A A A B B B
基于上述概念,可以定义如下 :
全局马尔可夫性质 :对于互不相交的集合 A A A B B B C C C A A A B B B C C C A A A B B B
x A ⊥ x B ∣ x C (12.4) \mathbf{x}_A \perp \mathbf{x}_B | \mathbf{x}_C \tag{12.4}
x A ⊥ x B ∣ x C ( 12.4 )
【定理 12.3】 如果 x \mathbf{x} x G \mathcal{G} G x \mathbf{x} x
注意: A ∪ B ∪ C A \cup B \cup C A ∪ B ∪ C V \mathcal{V} V x A ∪ B ∪ C \mathbf{x}_{A\cup B\cup C} x A ∪ B ∪ C
【例 12.3】
继续回顾 例 12.1。利用 成对条件独立性 ,我们知道 x 1 ⊥ x n ∣ x − 1 , n x_1 \perp x_n | \mathbf{x}_{-{1,n}} x 1 ⊥ x n ∣ x − 1 , n 全局马尔可夫性质 ,我们也可以知道:对于所有 1 < j < n 1 < j < n 1 < j < n x 1 ⊥ x n ∣ x j x_1 \perp x_n|x_j x 1 ⊥ x n ∣ x j
12.4 条件指定
依据 J. Besag (1974, 1975) 的开创性工作,通常会通过 完全条件分布 { π ( x i ∣ x − i ) } \{\pi(x_i |\mathbf{x}_{-i})\} { π ( x i ∣ x − i )} 完全条件分布 中推导出相应 联合分布 的均值和精度矩阵。但 完全条件分布 不能完全随意指定,因为还要确保其对应的联合分布是正确的( 我们将在 第 12.8 节 中讨论此问题)。
一种条件指定方法是将 完全条件分布 { π ( x i ∣ x − i ) } \{\pi(x_i |\mathbf{x}_{-i} )\} { π ( x i ∣ x − i )}
E ( x i ∣ x − i ) = μ i + ∑ j ≠ i β i , j ( x j − μ j ) 和 Precision ( x i ∣ x − i ) = κ i > 0 (12.5) \mathbb{E}(x_i |\mathbf{x}_{-i} ) = \mu_i + \sum_{j \neq i} \beta_{i,j} (x_j − \mu_j) \quad \text{和} \quad \operatorname{ Precision}(x_i | \mathbf{x}_{-i}) = \kappa_i > 0 \tag{12.5}
E ( x i ∣ x − i ) = μ i + j = i ∑ β i , j ( x j − μ j ) 和 Precision ( x i ∣ x − i ) = κ i > 0 ( 12.5 )
这种方法的合理性在于:指定完全条件分布比指定联合分布更容易。
比较 式(12.5) 和 式(12.2) ,如果我们选择 μ \boldsymbol{\mu} μ Q i i = κ i Q_{ii} = \kappa_i Q ii = κ i β i , j = − Q i , j / Q i i \beta_{i,j} = −\mathbf{Q}_{i,j}/\mathbf{Q}_{ii} β i , j = − Q i , j / Q ii 完全条件分布 ;请参阅下面的正式证明。
不过,由于 Q \mathbf{Q} Q i ≠ j i \neq j i = j
κ i β i , j = κ j β j , i (12.6) \kappa_i \beta_{i,j} = \kappa_j \beta_{j,i} \tag{12.6}
κ i β i , j = κ j β j , i ( 12.6 )
特别是,如果 β i , j \beta_{i, j} β i , j β j , i \beta_{j,i} β j , i G \mathcal{G} G { { i , j } : β i , j ≠ 0 } \left \{\{i, j\} : \beta_{i,j} \neq 0 \right \} { { i , j } : β i , j = 0 }
除了 式(12.6) 的对称约束之外,还有一个联合分布要求是 Q \mathbf{Q} Q Q \mathbf{Q} Q i i i Q i , i > ∑ j ∣ Q i , j ∣ Q_{i,i} > \sum\limits_{j} |Q_{i, j}| Q i , i > j ∑ ∣ Q i , j ∣
∑ j ∣ β i , j ∣ < 1 , ∀ i \sum\limits_{j} |\beta _{i,j} | <1 , \forall i
j ∑ ∣ β i , j ∣ < 1 , ∀ i
但这种假设可能具有局限性(Rue 和 Held,2005 年,第 2.7 节和第 5.1 节)。
尽管我们能够识别具有相同完全条件分布的高斯,但我们仍然需要知道联合分布的唯一性。 Brook 引理(Brook,1964)回答了这个问题。
【引理 12.1(Brook 引理)】
令 π ( x ) \pi(\mathbf{x}) π ( x ) x ∈ R n \mathbf{x} \in \mathbb{R}^n x ∈ R n Ω = { x ∈ R n : π ( x ) > 0 } \Omega =\{\mathbf{x} \in \mathbb{R}^n: \pi(\mathbf{x}) > 0 \} Ω = { x ∈ R n : π ( x ) > 0 } x , x ′ ∈ Ω \mathbf{x}, \mathbf{x'} \in \Omega x , x ′ ∈ Ω
π ( x ) π ( x ′ ) = ∏ i = 1 n π ( x i ∣ x 1 , … , x i − 1 , x i + 1 ′ , … , x n ′ ) π ( x i ′ ∣ x 1 , … , x i − 1 , x i + 1 ′ , … , x n ′ ) = ∏ i = 1 n π ( x i ∣ x 1 ′ , … , x i − 1 ′ , x i + 1 , … , x n ) π ( x i ′ ∣ x 1 ′ , … , x i − 1 ′ , x i + 1 , … , x n ) \begin{align*}
\frac{\pi(\mathbf{x})}{\pi(\mathbf{x'})} &= \prod^{n}_{i=1} \frac{ \pi(x_i |x_1,\ldots,x_{i−1},x'_{i+1},\ldots ,x'_n)}{\pi(x'_i |x_1,\ldots ,x_{i−1},x'_{i+1},\ldots ,x'_n)} \tag{12.7}\\
&= \prod^{n}_{i=1} \frac{ \pi(x_i |x'_1,\ldots ,x'_{i−1},x_{i+1},\ldots ,x_n)}{\pi(x'_i |x'_1,\ldots ,x'_{i−1},x_{i+1},\ldots ,x_n)} \tag{12.8}
\end{align*}
π ( x ′ ) π ( x ) = i = 1 ∏ n π ( x i ′ ∣ x 1 , … , x i − 1 , x i + 1 ′ , … , x n ′ ) π ( x i ∣ x 1 , … , x i − 1 , x i + 1 ′ , … , x n ′ ) = i = 1 ∏ n π ( x i ′ ∣ x 1 ′ , … , x i − 1 ′ , x i + 1 , … , x n ) π ( x i ∣ x 1 ′ , … , x i − 1 ′ , x i + 1 , … , x n ) ( 12.7 ) ( 12.8 )
唯一性论证遵循固定 x ′ \mathbf{x}' x ′ π ( x ) \pi(\mathbf{x}) π ( x ) 式(12.7) 右侧的完全条件分布成正比。比例常数是利用 π ( x ) \pi(\mathbf{x}) π ( x ) μ = 0 \boldsymbol{\mu} = 0 μ = 0 x ′ = 0 \mathbf{x'} = 0 x ′ = 0 式(12.5) 中的完全条件分布,然后 式(12.7) 简化为
log π ( x ) π ( 0 ) = − 1 2 ∑ i = 1 n κ i x i 2 − ∑ i = 2 n ∑ j = 1 i − 1 κ i β i j x i x j (12.9) \log \frac{ \pi(\mathbf{x})}{\pi(\mathbf{0})} = − \frac{1}{2} \sum^n_{i=1} \kappa_i x^2_i − \sum^n_{i=2} \sum\limits^{i-1}_{j=1} \kappa_i \beta_{ij} x_i x_j \tag{12.9}
log π ( 0 ) π ( x ) = − 2 1 i = 1 ∑ n κ i x i 2 − i = 2 ∑ n j = 1 ∑ i − 1 κ i β ij x i x j ( 12.9 )
并且 式(12.8) 简化为
log π ( x ) π ( 0 ) = − 1 2 ∑ i = 1 n κ i x i 2 − ∑ i = 1 n − 1 ∑ j = i + 1 n κ i β i j x i x j (12.10) \log \frac{ \pi(\mathbf{x})}{\pi(\mathbf{0})} = −\frac{1}{2} \sum^n_{i=1} \kappa_i x^2_i − \sum\limits^{n-1}_{i=1} \sum\limits^{n}_{j=i+1} \kappa_i \beta_{ij} x_i x_j \tag{12.10}
log π ( 0 ) π ( x ) = − 2 1 i = 1 ∑ n κ i x i 2 − i = 1 ∑ n − 1 j = i + 1 ∑ n κ i β ij x i x j ( 12.10 )
由于 式(12.9) 和 式(12.6) 必须相同,因此 对于 i ≠ j i \neq j i = j κ i β i j = κ j β j i \kappa_i \beta_{ij} = \kappa_j \beta_{ji} κ i β ij = κ j β ji x \mathbf{x} x
log π ( x ) = const − 1 2 ∑ i = 1 n κ i x i 2 − 1 2 ∑ i ≠ j κ i β i j x i x j \log \pi(\mathbf{x}) = \quad \text{const} − \frac{1}{2} \sum^n_{i=1} \kappa_i x^2_i - \frac{1}{2} \sum\limits_{i \neq j} \kappa_i \beta_{ij} x_i x_j
log π ( x ) = const − 2 1 i = 1 ∑ n κ i x i 2 − 2 1 i = j ∑ κ i β ij x i x j
因此,如果 Q \mathbf{Q} Q x \mathbf{x} x
我们现在将在一个简单的例子中说明条件指定的实际使用。
【例 12.4】
图 12.2(a) 中的图像是 256 × 256 256 × 256 256 × 256 I \mathcal{I} I i i i y i y_i y i η i \eta_i η i y i ∼ Poisson ( η i ) y_i \sim \operatorname{ Poisson}(\eta_i) y i ∼ Poisson ( η i )
y i ∣ η i ∼ N ( η i , 1 4 ) , i ∈ I \sqrt{y_i} | \eta_i \sim \mathcal{N} \left (\sqrt{ \eta_i} , \frac{1}{4} \right ) ,i \in \mathcal{I}
y i ∣ η i ∼ N ( η i , 4 1 ) , i ∈ I
平方根变换后的图像如 图 12.2(b) 所示。采用贝叶斯方法,我们需要为(平方根变换的)图像 x = ( x 1 , … , x n ) ⊤ \mathbf{x} = (x_1,\ldots ,x_n)^{\top} x = ( x 1 , … , x n ) ⊤ x i = η i x_i = \sqrt{ \eta_i} x i = η i η i \eta_i η i 式(12.5) 的完全条件分布指定先验。使用完全条件分布,我们只需要回答这样的问题: 如果不知道像素 i i i x i x_i x i 一种选择是将 β i , j \beta_{i,j} β i , j j j j i i i N 4 ( i ) N_4(i) N 4 ( i ) i i i
β i , j = δ 4 , j ∈ N 4 ( i ) \beta_{i,j} = \frac{\delta}{4}, \quad j \in N_4(i)
β i , j = 4 δ , j ∈ N 4 ( i )
其中 δ \delta δ κ i \kappa_i κ i i i i δ \delta δ ∣ δ ∣ < 1 |\delta| < 1 ∣ δ ∣ < 1 μ = 0 \boldsymbol{\mu} = \mathbf{0} μ = 0 κ \kappa κ Γ ( a , b ) \Gamma(a, b) Γ ( a , b ) κ a − 1 exp ( − b κ ) ) \kappa^{a-1} \exp(−b\kappa)) κ a − 1 exp ( − bκ )) ( x , κ ) (x, \kappa) ( x , κ )
π ( x , κ ∣ y ) ∝ π ( x ∣ κ ) π ( κ ) ∏ i ∈ I π ( y i ∣ x i ) ∝ κ a − 1 exp ( − b κ ) ∣ Q p r i o r ( κ ) ∣ 1 / 2 exp ( − 1 2 x ⊤ Q p o s t ( κ ) x + b ⊤ x ) \begin{align*}
\pi(\mathbf{x}, \kappa | \mathbf{y}) &\propto \pi( \mathbf{x} | \kappa) \pi(\kappa) \prod\limits_{i \in \mathcal{I}} \pi( y_i | x_i ) \\
& \propto \kappa^{a-1} \exp(−b_{\kappa}) | \mathbf{Q}_{prior}(\kappa) |^{1/2} \exp \left( − \frac{1}{2} \mathbf{x}^{\top} \mathbf{Q}_{post}(\kappa) \mathbf{x} + \mathbf{b}^{\top} \mathbf{x} \right) \tag{12.11}
\end{align*}
π ( x , κ ∣ y ) ∝ π ( x ∣ κ ) π ( κ ) i ∈ I ∏ π ( y i ∣ x i ) ∝ κ a − 1 exp ( − b κ ) ∣ Q p r i or ( κ ) ∣ 1/2 exp ( − 2 1 x ⊤ Q p os t ( κ ) x + b ⊤ x ) ( 12.11 )
这里,对于 i ∈ I i \in \mathcal{I} i ∈ I b i = 4 y i b_i = 4\sqrt{ y_i} b i = 4 y i Q p o s t ( κ ) = Q p r i o r ( κ ) + D \mathbf{Q}_{post}(\kappa) = \mathbf{Q}_{prior}(\kappa) + \mathbf{D} Q p os t ( κ ) = Q p r i or ( κ ) + D D \mathbf{D} D i ∈ I i \in \mathcal{I} i ∈ I D i , i = 4 D_{i,i} = 4 D i , i = 4
Q p r i o r ( κ ) i , j = κ { 1 , i = j δ / 4 , j ∈ N 4 ( i ) 0 , otherwise \mathbf{Q}_{prior}(\kappa)_{i, j} = \kappa \begin{cases}
1, & i=j\\ \delta/4, &j \in N_4(i)\\
0, & \text{otherwise}
\end{cases}
Q p r i or ( κ ) i , j = κ ⎩ ⎨ ⎧ 1 , δ /4 , 0 , i = j j ∈ N 4 ( i ) otherwise
以 κ \kappa κ x \mathbf{x} x Q p o s t \mathbf{Q}_{post} Q p os t μ p o s t \boldsymbol{\mu}_{post} μ p os t
Q p o s t μ p o s t = b (12.12) \mathbf{Q}_{post} \boldsymbol{\mu}_{post} = \mathbf{b} \tag{12.12}
Q p os t μ p os t = b ( 12.12 )
12.5 GMRF 的 MCMC 推断
GMRF 的一个吸引人的特性是可以很好地与 MCMC 方法结合起来进行贝叶斯推断(参见 Gilks、Richardson 和 Spiegelhalter,1996 年;Robert 和 Casella,1999 年关于 MCMC 的一般背景)。 GMRF 中使用的完全条件分解(即相应的条件指定)与 MCMC 算法之间的良好对应关系,是 GMRF 被广泛使用的主要原因之一。
事实证明,GMRF 与稀疏矩阵的数值方法之间存在很好的联系,这导致了 GMRF 的精确算法;我们将在 第 12.7 节 讨论此问题。
为了描述方便,设 π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) E ( θ 1 ) \mathcal{E}(\theta_1) E ( θ 1 ) Var ( θ 1 ) \operatorname{Var}(\theta_1) Var ( θ 1 )
π ( θ 1 ) , … , π ( θ n ) \pi(\theta_1),\ldots , \pi(\theta_n)
π ( θ 1 ) , … , π ( θ n )
对于 例 12.4,相应的 θ = ( x , κ ) \boldsymbol{\theta} = (\mathbf{x}, \kappa) θ = ( x , κ ) i ∈ I i \in \mathcal{I} i ∈ I E ( x i ∣ y ) \mathbb{E}(x_i |\mathbf{y}) E ( x i ∣ y ) η i \sqrt{ \eta_i} η i Var ( x i ∣ y ) \operatorname{Var}(x_i |\mathbf{y}) Var ( x i ∣ y ) π ( x i ∣ y ) \pi(x_i |\mathbf{y}) π ( x i ∣ y )
12.5.1 MCMC背后的基本思想
MCMC 的基本思想很简单。我们将简要介绍两个基本思想,马尔可夫链和蒙特卡罗,它们共同构成了马尔可夫链蒙特卡罗。用于(也称为贝叶斯)推断的蒙特卡罗方法主要是关于蒙特卡罗积分,它用经验方法代替积分;对于一些合适的函数 f ( ⋅ ) f (·) f ( ⋅ )
E ( f ( θ ) ) = ∫ f ( θ ) π ( θ ) d θ ≈ 1 N ∑ i = 1 N f ( θ ( i ) ) (12.13) \mathbb{E}( f (\boldsymbol{\theta})) = \int f (\boldsymbol{\theta})\pi(\boldsymbol{\theta}) d\boldsymbol{\theta} \approx \frac{1}{N} \sum^{N}_{i=1} f (\boldsymbol{\theta}^{(i)}) \tag{12.13}
E ( f ( θ )) = ∫ f ( θ ) π ( θ ) d θ ≈ N 1 i = 1 ∑ N f ( θ ( i ) ) ( 12.13 )
其中:
θ ( 1 ) , θ ( 2 ) , … , θ ( N ) \boldsymbol{\theta}^{(1)}, \boldsymbol{\theta}^{(2)},\ldots , \boldsymbol{\theta}^{(N)}
θ ( 1 ) , θ ( 2 ) , … , θ ( N )
是来自 π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) N N N π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) N N N
1 N ∑ i = 1 N f ( θ ( i ) ) ≈ N ( E ( f ( θ ) ) , Var ( f ( θ ) ) ) \frac{1}{\sqrt{N}} \sum^{N}_{i=1} f(\boldsymbol{\theta}^{(i)}) \approx \mathcal{N}(\mathbb{E}( f(\boldsymbol{\theta})), \operatorname{Var}( f (\boldsymbol{\theta})))
N 1 i = 1 ∑ N f ( θ ( i ) ) ≈ N ( E ( f ( θ )) , Var ( f ( θ )))
在相当一般的假设下。我们的估计可以尽可能精确,选择足够大的 N N N O ( 1 / N ) \mathcal{O}(1/\sqrt{N}) O ( 1/ N ) 100 × N 100 × N 100 × N
即使对于低维,从分布 π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) E ( f ( θ ) ) \mathbb{E}( f (\boldsymbol{\theta})) E ( f ( θ ))
第二个主要思想是绕过直接从 π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) π ( θ ) \pi(\boldsymbol{\theta}) π ( θ )
我们现在将介绍 Gibbs 采样器,它是两种最流行的 MCMC 算法之一。我们将推迟到 第 12.9 节 讨论第二个算法,即 Metropolis-Hastings 算法。吉布斯采样器由 Geman 和 Geman (1984) 引入主流 IEEE 文献,由 Gelfand 和 Smith (1990) 引入统计。后来,很明显,一般思想(及其含义)已经围绕 Hastings(1970 年)展开;参见(Robert and Casella,1999,第 7 章)的历史记录。
12.5.2 吉布斯采样器
最直观的 MCMC 算法称为 Gibbs 采样器。吉布斯采样器通过从完全条件分布中重复采样来模拟马尔可夫链。马尔可夫链中的状态向量 θ \boldsymbol{\theta} θ
该算法定义了一个具有平衡分布 π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) θ \boldsymbol{\theta} θ π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) π ( θ i ∣ θ − i ) \pi(\theta_i |\boldsymbol{\theta}_{-i}) π ( θ i ∣ θ − i ) i i i θ i \theta_i θ i θ \boldsymbol{\theta} θ π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) t = 1 、 2 、 … t = 1、2、\ldots t = 1 、 2 、 … θ \boldsymbol{\theta} θ θ ( 1 ) , θ ( 2 ) , … \boldsymbol{\theta}^{(1)}, \boldsymbol{\theta}^{(2)},\ldots θ ( 1 ) , θ ( 2 ) , …
在相当一般的条件下,θ ( k ) \boldsymbol{\theta}^{(k)} θ ( k ) k → ∞ k \rightarrow \infty k → ∞ π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) k k k k 0 k_0 k 0 θ ( k 0 ) \boldsymbol{\theta}^{(k_0)} θ ( k 0 ) π ( θ ) \pi(\boldsymbol{\theta}) π ( θ ) θ ( k 0 ) \boldsymbol{\theta}^{(k_0)} θ ( k 0 ) 式(12.13) 中的蒙特卡洛估计将修改为
E ( f ( θ ) ) = 1 N − k 0 + 1 ∑ i = k 0 N f ( θ ( i ) ) 。 ‘ 式( 12.14 ) ‘ \mathbb{E}( f (\boldsymbol{\theta})) = \frac{1}{N − k_0 + 1} \sum^{N}_{i=k_0} f (\boldsymbol{\theta}^{(i)})。 `式(12.14)`
E ( f ( θ )) = N − k 0 + 1 1 i = k 0 ∑ N f ( θ ( i ) ) 。 ‘ 式( 12.14 ) ‘
请注意,{ θ ( i ) } \{\boldsymbol{\theta}^{(i)}\} { θ ( i ) } i = k 0 , … i = k_0,\ldots i = k 0 , … 式(12.14) 的方差估计必须考虑这种依赖性。我们已经从马尔可夫链中释放了前 k 0 − 1 k_0 − 1 k 0 − 1 k 0 k_0 k 0 θ i \theta_i θ i { θ i ( k ) } \{\boldsymbol{\theta}^{(k)}_i \} { θ i ( k ) } k = 1 , 2 , … k = 1, 2,\ldots k = 1 , 2 , … k 0 k_0 k 0 k 0 k_0 k 0 k 0 k_0 k 0
【例 12.5】
我们现在将说明如何使用 Gibbs 采样器从 GMRF 生成样本。如果我们通过完全条件分布 式(12.5) 指定 GMRF,我们将立即拥有 Gibbs 采样器。该算法如下:
GMRF 的 Gibbs 采样器的吸引力在于简单性和速度。它很简单,因为我们不需要计算 x \mathbf{x} x π ( x ) \pi(\mathbf{x}) π ( x ) i i i n n n x \mathbf{x} x n n n O ( n ) \mathcal{O}(n) O ( n )
【例 12.6】
让我们回到 例 12.4,它比 例 12.5 复杂一些,原因有二。首先,我们需要处理未知精度 κ \kappa κ κ \kappa κ 式(12.12) 的解给出。事实证明,我们不需要求解 式(12.12) 即可构建 Gibbs 采样器。
在此示例中,θ = ( κ , x ) \boldsymbol{\theta} = (\kappa, \mathbf{x}) θ = ( κ , x ) 式(12.11) 计算所有完全条件分布。使用 Q p o s t ( κ ) = κ Q p r i o r ( 1 ) + D \mathbf{Q}_{post}(\kappa) = \kappa \mathbf{Q}_{prior}(1) + D Q p os t ( κ ) = κ Q p r i or ( 1 ) + D κ \kappa κ
κ ∣ x , y ∼ Γ ( n / 2 + a , b + 1 2 x ⊤ Q p r i o r ( 1 ) x ) \kappa | \mathbf{x, y} \sim \Gamma ( n/2 + a, b + \frac{1}{2} \mathbf{x}^{\top} \mathbf{Q}_{prior}(1) \mathbf{x} )
κ ∣ x , y ∼ Γ ( n /2 + a , b + 2 1 x ⊤ Q p r i or ( 1 ) x )
x i x_i x i
π ( x i ∣ x − i , κ , y ) ∝ π ( x , κ ∣ y ) ∝ exp ( − 1 2 x i 2 Q p o s t , i , i ( κ ) − x i ∑ j ∈ N 4 ( i ) Q p r i o r , i , j ( κ ) x j + b i x i ) = exp ( − 1 2 c i x i 2 + d i x i ) \begin{align*}
\pi(x_i | \mathbf{x}_{-i} , \kappa, \mathbf{y}) &\propto \pi(\mathbf{x}, \kappa | \mathbf{y})\\
&\propto \exp \left ( − \frac{1}{2} x^2_i \mathbf{Q}_{post,i,i} (\kappa) − x_i \sum\limits_{ j \in N_4(i)} \mathbf{Q}_{prior,i , j} (\kappa)x_j + b_i x_i \right ) \\
&= \exp \left (- \frac{1}{2}c_i x^2_i + d_i x_i \right)
\end{align*}
π ( x i ∣ x − i , κ , y ) ∝ π ( x , κ ∣ y ) ∝ exp − 2 1 x i 2 Q p os t , i , i ( κ ) − x i j ∈ N 4 ( i ) ∑ Q p r i or , i , j ( κ ) x j + b i x i = exp ( − 2 1 c i x i 2 + d i x i )
其中 c i c_i c i κ \kappa κ d i d_i d i κ \kappa κ { x j } \{x_j\} { x j } j ∈ N 4 ( i ) j \in N_4(i) j ∈ N 4 ( i ) x i x_i x i N ( d i / c i , 1 / c i ) \mathcal{N}(d_i /c_i , 1/c_i ) N ( d i / c i , 1/ c i )
x \mathbf{x} x 图 12.2(c) 中,使用 a = 1 a = 1 a = 1 b = 0.01 b = 0.01 b = 0.01 β = 1 / 4 \beta = 1/4 β = 1/4 ( κ , x ) (\kappa, \mathbf{x}) ( κ , x ) y \mathbf{y} y x i x_i x i N 4 ( i ) N_4(i) N 4 ( i ) O ( n ) \mathcal{O}(n) O ( n ) κ \kappa κ x ⊤ Q p r i o r ( 1 ) x \mathbf{x}^{\top} \mathbf{Q}_{prior}(1) \mathbf{x} x ⊤ Q p r i or ( 1 ) x O ( n ) \mathcal{O}(n) O ( n )
12.6 多变量 GMRF
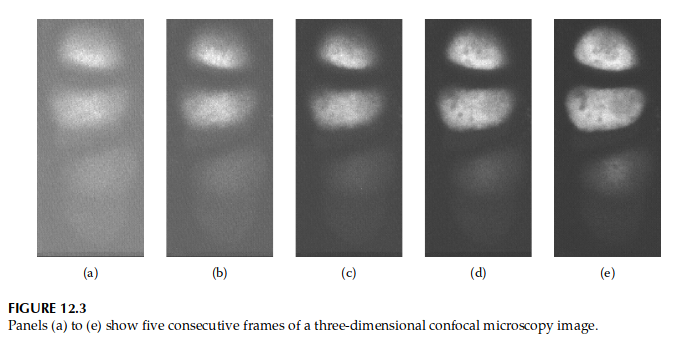
为了修正想法,我们将考虑 示例 12.4 的一般化,其中观察现在是图像序列。该序列可以是电影,其中序列中的每一帧都按时间索引,也可以是将三维对象记录为一组二维图像的高度。其他示例包括一个国家每个行政区域疾病计数空间模型的时间版本。图 12.3 显示了共聚焦显微镜拍摄的三个连续的三维细胞帧。第一帧有很多噪音,但信号在图像堆栈中越往上越强。我们考虑与示例 12.4 相同的问题;我们想在存在噪声的情况下估计真实信号。五帧代表相同的三维对象,但在不同的高度。
当我们指定完全条件分布时,我们可以使用这些信息。然后指定完全条件分布 式(12.5) 的多变量版本更容易也更自然,我们现在将对其进行描述。设 x i x_i x i i i i p = 5 p = 5 p = 5
x i = ( x i , 1 , x i , 2 , x i , 3 , x i , 4 , x i , 5 ) ⊤ x_i = (x_{i,1},x_{i,2},x_{i,3},x_{i,4},x_{i,5})^{\top}
x i = ( x i , 1 , x i , 2 , x i , 3 , x i , 4 , x i , 5 ) ⊤
这里,x i , 2 x_{i,2} x i , 2 i i i 式(12.5) 自然延伸至
E ( x i ∣ x − i ) = μ i − ∑ j : j ∼ i β i , j ( x j − μ j ) and P r e c i s i o n ( x i ∣ x − i ) = κ i > 0 (12.15) \mathbb{E}(\mathbf{x}_i | \mathbf{x}_{-i} ) = \boldsymbol{\mu}_i − \sum\limits_{j: j \sim i} \beta_{i,j}(\mathbf{x}_j − \boldsymbol{\mu}_j) \quad \text{and} \quad Precision(\mathbf{x}_i | \mathbf{x}_{-i} ) = \boldsymbol{ \kappa}_i > 0 \tag{12.15}
E ( x i ∣ x − i ) = μ i − j : j ∼ i ∑ β i , j ( x j − μ j ) and P rec i s i o n ( x i ∣ x − i ) = κ i > 0 ( 12.15 )
对于某些 p × p p × p p × p { β i , j } \{\beta_{i,j}\} { β i , j } { κ i } \{\kappa_i\} { κ i } x i , 3 x_{i,3} x i , 3 x i , 2 x_{i,2} x i , 2 x i , 4 x_{i,4} x i , 4 x i x_i x i i i i { x j , 3 , j ∈ N 4 ( i ) } \{x_{j,3},j\in N_4(i)\} { x j , 3 , j ∈ N 4 ( i )} x i \mathbf{x}_i x i { x j } , j ≠ i \{\mathbf{x}_j \},j \neq i { x j } , j = i p p p
此示例中的条件指定激发了多元 GMRF 的引入,我们将其表示为 MGMRFp _p p 式(12.1) 的直接扩展。设 x = ( x 1 ⊤ , … , x n ⊤ ) ⊤ \mathbf{x} = (\mathbf{x}^{\top}_1 ,\ldots , \mathbf{x}^{\top}_n )^{\top} x = ( x 1 ⊤ , … , x n ⊤ ) ⊤ x i \mathbf{x}_i x i p p p μ = ( μ 1 ⊤ , … , μ ⊤ ) ⊤ \boldsymbol{\mu} = (\boldsymbol{\mu} ^{\top}_1 ,\ldots , \boldsymbol{\mu}^{\top})^{\top} μ = ( μ 1 ⊤ , … , μ ⊤ ) ⊤ Q ~ = ( Q ~ i , j ) \tilde{\mathbf{Q}} = (\tilde{\mathbf{Q}}_{i,j}) Q ~ = ( Q ~ i , j ) p × p p × p p × p Q ~ i , j \tilde{\mathbf{Q}}_{i,j} Q ~ i , j
【定义 12.2 (MGMRFp _p p
随机向量 x = ( x 1 ⊤ , … , x n ⊤ ) ⊤ \mathbf{x} = (\mathbf{x}^{\top}_1 ,\ldots , \mathbf{x}^{\top}_n )^{\top} x = ( x 1 ⊤ , … , x n ⊤ ) ⊤ dim ( x i ) = p \text{dim}(x_i ) = p dim ( x i ) = p G = ( V = { 1 , … , n } , E ) \mathcal{G} = (\mathcal{V} = \{1,\ldots,n\}, \mathcal{E}) G = ( V = { 1 , … , n } , E ) p _p p μ \boldsymbol{\mu} μ Q ~ \tilde{\mathbf{Q}} Q ~
π ( x ) = ( 1 2 π ) n p / 2 ∣ Q ~ ∣ 1 / 2 exp ( 1 2 ( x − μ ) ⊤ Q ~ ( x − μ ) ) = ( 1 2 π ) n p / 2 ∣ Q ~ ∣ 1 / 2 exp ( − 1 2 ∑ i j ( x i − μ i ) ⊤ Q ~ i , j ( x j − μ j ) Q ~ i , j ≠ 0 ⇔ { i , j } ∈ E for all i ≠ j \begin{align*}
\pi(\mathbf{x}) &= (\frac{1}{2 \pi})^{np/2} |\tilde{\mathbf{Q}}|^{1/2} \exp \left (\frac{1}{2} (\boldsymbol{x} − \boldsymbol{\mu} )^{\top} \tilde{\mathbf{Q}}(\mathbf{x} − \boldsymbol{\mu} ) \right ) \\
&= (\frac{1}{2\pi})^{np/2} |\tilde{\mathbf{Q}}|^{1/2} \exp \left (− \frac{1}{2} \sum\limits_{ij} (\mathbf{x}_i − \boldsymbol{\mu}_i )^{\top} \tilde{\mathbf{Q}}_{i,j} (\mathbf{x}_j − \boldsymbol{\mu}_j \right)\\
\tilde{\mathbf{Q}}_{i,j} \neq 0 &\Leftrightarrow \{ i, j\} \in \mathcal{E} \quad \text{for all} \quad i \neq j
\end{align*}
π ( x ) Q ~ i , j = 0 = ( 2 π 1 ) n p /2 ∣ Q ~ ∣ 1/2 exp ( 2 1 ( x − μ ) ⊤ Q ~ ( x − μ ) ) = ( 2 π 1 ) n p /2 ∣ Q ~ ∣ 1/2 exp ( − 2 1 ij ∑ ( x i − μ i ) ⊤ Q ~ i , j ( x j − μ j ) ⇔ { i , j } ∈ E for all i = j
重要的是要注意大小为 n n n p _p p n p np n p p _p p
x i ⊥ x j ∣ x − { i , j } ⇔ Q ~ i , j = 0 \mathbf{x}_i \perp \mathbf{x}_j | \mathbf{x}_{−\{i, j\}} \Leftrightarrow \tilde{\mathbf{Q}}_{i,j} = \mathbf{0}
x i ⊥ x j ∣ x − { i , j } ⇔ Q ~ i , j = 0
并且
E ( x i ∣ x − i ) = μ i − Q ~ i , i − 1 ∑ j : j ∼ i Q ~ i , j ( x j − μ j ) 和 P r e c i s i o n ( x i ∣ x − i ) = Q ~ i i (12.16) \mathbb{E}(\mathbf{x}_i | \mathbf{x}_{-i} ) = \boldsymbol{\mu}_i − \tilde{ \mathbf{Q}}^{-1}_{ i,i} \sum\limits_{ j: j \sim i} \tilde{ \mathbf{Q}}_{i,j}(\mathbf{x}_j − \boldsymbol{\mu}_j) \quad \text{和} \quad Precision(\mathbf{x}_i | \mathbf{x}_{-i}) = \tilde{\mathbf{Q}}_{ii} \tag{12.16}
E ( x i ∣ x − i ) = μ i − Q ~ i , i − 1 j : j ∼ i ∑ Q ~ i , j ( x j − μ j ) 和 P rec i s i o n ( x i ∣ x − i ) = Q ~ ii ( 12.16 )
从 式(12.16) ,我们可以通过选择条件指定 式(12.15) 获得一致性要求
Q i , j = { κ i β i , j i ≠ j κ i i ≠ j \mathbf{Q}_{i,j} =
\begin{cases}
\boldsymbol{ \kappa_i \beta}_{i,j} & i \neq j\\
\boldsymbol{ \kappa}_i & i \neq j
\end{cases}
Q i , j = { κ i β i , j κ i i = j i = j
因为 Q ~ i , j = Q ~ j , i ⊤ \tilde{ \mathbf{Q}}_{i,j} = \tilde{ \mathbf{Q}}^{\top}_{j,i} Q ~ i , j = Q ~ j , i ⊤ i ≠ j i \neq j i = j κ i β i , j = β j , i ⊤ κ j \boldsymbol{ \kappa_i \beta}_{i,j} = \boldsymbol{ \beta}^{\top}_{j,i} \boldsymbol{ \kappa}_j κ i β i , j = β j , i ⊤ κ j i i i κ i > 0 \boldsymbol{ \kappa}_i > 0 κ i > 0 Q ~ \tilde{\mathbf{Q}} Q ~ ( I + ( β i , j ) ) (\mathbf{I} + ( \boldsymbol{ \beta}_{i,j}) ) ( I + ( β i , j ))
12.7 GMRF 的精确推断算法
GMRF 与稀疏矩阵的高效数值算法之间也有着良好联系,并产生了 GMRF 的精确算法。本节将讨论这种联系,并首先从各种精确算法开始,然后讨论如何有效地从 GMRF 中采样。这其中包括无条件采样、有条件采样、线性硬约束采样、线性软约束采样、特定 GMRF 对数密度的计算、GMRF 边缘方差的计算等任务。
尽管所有这些任务在形式上都是 “矩阵代数”,但我们需要确保在所有步骤中都利用了稀疏精度矩阵 Q \mathbf{Q} Q Q \mathbf{Q} Q Q = L L ⊤ \mathbf{Q} = \mathbf{LL}^{\top} Q = LL ⊤ L \mathbf{L} L L \mathbf{L} L
我们将始终假设 x \mathbf{x} x G \mathcal{G} G μ \boldsymbol{\mu} μ Q \mathbf{Q} Q
12.7.1 为什么精确算法很重要?
在存在精确有效算法时,通常会选择精确方法,即使它需要比简单迭代算法更复杂的算法。即使对于统计建模,计算可行性也很重要,因为如果不能足够有效地进行推断,那么统计模型就没有多大用处。
使用精度矩阵的 Cholesky 分解可以精确完成 GMRF 的采样,这在算法上比简单 Gibbs 采样器复杂得多。不过,精确算法是精确和自动的,而 Gibbs 采样算法是近似的,并且在大多数情况下,Gibbs 采样需要人工干预来判断样本的正确性和收敛性。事实证明,在空间场景中,我们能够以 O ( n 3 / 2 ) \mathcal{O}(n^{3/2}) O ( n 3/2 ) O ( n ) \mathcal{O}(\sqrt{n}) O ( n ) O ( n log n ) \mathcal{O}(n \log n) O ( n log n )
让我们再次回到 例 12.4 。现在稍微修改此示例以证明 Gibbs 采样算法并不总是那么简单。之前的举例中,我们假设参数 δ \delta δ δ \delta δ δ \delta δ
π ( δ ∣ x , κ , y ) ∝ π ( δ ) ∣ Q p r i o r ( κ , δ ) ∣ 1 / 2 exp ( − 1 2 x ⊤ Q p r i o r ( κ , δ ) x ) (12.17) \pi(\delta | \mathbf{x}, \kappa, \mathbf{y}) \propto \pi(\delta) |\mathbf{Q}_{prior}(\kappa, \delta)|^{1/2} \exp ( - \frac{1}{2} \mathbf{x}^{\top} \mathbf{Q}_{prior}(\kappa, \delta) \mathbf{x}) \tag{12.17}
π ( δ ∣ x , κ , y ) ∝ π ( δ ) ∣ Q p r i or ( κ , δ ) ∣ 1/2 exp ( − 2 1 x ⊤ Q p r i or ( κ , δ ) x ) ( 12.17 )
其中 π ( δ ) \pi(\delta) π ( δ ) κ \kappa κ δ \delta δ Q p r i o r ( κ , δ ) \mathbf{Q}_{prior}(\kappa,\delta) Q p r i or ( κ , δ ) Q p r i o r ( κ , δ ) \mathbf{Q}_{prior}(\kappa, \delta) Q p r i or ( κ , δ )
当任务是推断 GMRF 的未知参数时,也有类似的结论。
精确算法也可用于改进(单点) Gibbs 采样算法。此想法是一次只更新 θ \boldsymbol{\theta} θ π ( θ a ∣ θ − a ) \pi(\boldsymbol{\theta}_{a} |\boldsymbol{\theta}_{-a} ) π ( θ a ∣ θ − a ) θ a \boldsymbol{\theta}_{a} θ a θ a \boldsymbol{\theta}_{a} θ a 例 12.4 ,我们可以将 Gibbs 采样算法改进为在两个块中更新 ( κ , x ) (\kappa, \mathbf{x}) ( κ , x )
κ ∼ π ( κ ∣ x , y ) and x ∼ π ( x ∣ κ , y ) \kappa \sim \pi(\kappa|\mathbf{x, y}) \quad \text{and} \quad \mathbf{x} \sim \pi(\mathbf{x}|\kappa, \mathbf{y})
κ ∼ π ( κ ∣ x , y ) and x ∼ π ( x ∣ κ , y )
这是可能的,因为 π ( x ∣ κ , y ) \pi(\mathbf{x}|\kappa, \mathbf{y}) π ( x ∣ κ , y )
在许多情况下(包括 GMRF),因为精确(直至数值积分)或近似解的存在,是可以避免使用 MCMC 的;有关详细信息、应用和扩展,请参见 Rue、Martino 和 Chopin (2009)。这种方法的好处在于没有蒙特卡洛误差,并且提高了计算速度。再次回到 例 12.4,对于任意 x \mathbf{x} x
π ( κ ∣ y ) ∝ π ( x , κ ∣ y ) π ( x ∣ κ , y ) \pi(\kappa | \mathbf{y}) \propto \frac{\pi(\mathbf{x}, \kappa|\mathbf{y})}{\pi(\mathbf{x}|\kappa, \mathbf{y})}
π ( κ ∣ y ) ∝ π ( x ∣ κ , y ) π ( x , κ ∣ y )
要计算右侧(对于给定的 κ \kappa κ 式 (12.12) 。在得到 κ \kappa κ x i x_i x i
π ( x i ∣ y ) = ∫ π ( κ ∣ y ) π ( x i ∣ κ , y ) d κ , \pi(x_i | \mathbf{y}) = \int \pi(\kappa | \mathbf{y}) \pi(x_i | \kappa,\mathbf{y}) d \kappa,
π ( x i ∣ y ) = ∫ π ( κ ∣ y ) π ( x i ∣ κ , y ) d κ ,
上式可以用有限求和来近似。在这个例子中,x i ∣ κ , y x_i |\kappa, \mathbf{y} x i ∣ κ , y π ( x i ∣ y ) \pi(x_i |\mathbf{y}) π ( x i ∣ y )
这里的额外任务是计算 x i x_i x i δ \delta δ
π ( κ , δ ∣ y ) ∝ π ( x , κ , δ ∣ y ) π ( x ∣ κ , δ , y ) (12.18) \pi(\kappa, \delta | \mathbf{y}) \propto \pi(\mathbf{x}, \kappa, \delta|\mathbf{y}) \pi(\mathbf{x} |\kappa, \delta,\mathbf{y}) \tag{12.18}
π ( κ , δ ∣ y ) ∝ π ( x , κ , δ ∣ y ) π ( x ∣ κ , δ , y ) ( 12.18 )
和
π ( x i ∣ y ) = ∫ ∫ π ( κ , δ ∣ y ) π ( x i ∣ κ , δ , y ) d κ d δ \pi(x_i | \mathbf{y}) = \int\int \pi(\kappa, \delta | \mathbf{y}) \pi(x_i | \kappa, \delta,\mathbf{y}) d \kappa d \delta
π ( x i ∣ y ) = ∫∫ π ( κ , δ ∣ y ) π ( x i ∣ κ , δ , y ) d κ d δ
我们还需要计算 Q p r i o r ( κ , δ ) \mathbf{Q}_{prior}(\kappa, \delta) Q p r i or ( κ , δ ) π ( x i ∣ y ) \pi(x_i |\mathbf{y}) π ( x i ∣ y ) π ( κ ∣ y ) \pi(\kappa|\mathbf{y}) π ( κ ∣ y ) π ( δ , y ) \pi(\delta,\mathbf{y}) π ( δ , y ) 式 (12.18) 计算得出。
12.7.2 一些基本的线性代数
令 A \mathbf{A} A A = L L ⊤ \mathbf{A} = \mathbf{LL}^{\top} A = LL ⊤ L \mathbf{L} L
Cholesky 分解是求解 A y = b \mathbf{Ay = b} Ay = b A − 1 b \mathbf{A^{-1}b} A − 1 b
首先求解 L v = b \mathbf{Lv = b} Lv = b v = L − 1 b \mathbf{v=L^{-1}b} v = L − 1 b
然后求解 L ⊤ y = v \mathbf{L^{\top} y = v} L ⊤ y = v y = L − ⊤ v \mathbf{y=L^{-\top}v} y = L − ⊤ v
在具体算法实现上,第一个线性方程 L v = b \mathbf{Lv = b} Lv = b
v i = 1 L i , i ( b i − ∑ j = 1 i − 1 L i , j v j ) , i = 1 , … , n , v_i = \frac{1}{\mathbf{L}_{i,i}}\left (b_i − \sum^{i-1}_{j=1} L_{i,j} v_j \right ) ,i= 1,\ldots ,n,
v i = L i , i 1 ( b i − j = 1 ∑ i − 1 L i , j v j ) , i = 1 , … , n ,
而对于第二个线性方程 L ⊤ y = v \mathbf{L^{\top} y = v} L ⊤ y = v
y i = 1 L i , i ( v i − ∑ j = i + 1 n L j , i y j ) , i = n , … , 1 y_i = \frac{1}{\mathbf{L}_{i,i}} \left (v_i − \sum^{n}_{j=i+1} \mathbf{L}_{j,i}y_j \right ) ,i= n, \ldots , 1
y i = L i , i 1 ( v i − j = i + 1 ∑ n L j , i y j ) , i = n , … , 1
当 b \mathbf{b} b Υ \boldsymbol{\Upsilon} Υ A − 1 Υ \mathbf{A^{-1}\boldsymbol{\Upsilon}} A − 1 Υ Υ \mathbf{\boldsymbol{\Upsilon}} Υ n × k n × k n × k Υ j \mathbf{\boldsymbol{\Upsilon}}_j Υ j A − 1 Υ j \mathbf{A^{-1}\boldsymbol{\Upsilon}_j} A − 1 Υ j A \mathbf{A} A
显然,当 Υ = I \mathbf{\boldsymbol{\Upsilon}} = \mathbf{I} Υ = I k = n k = n k = n b = 1 \mathbf{b=1} b = 1 A \mathbf{A} A solve(A) 正是采用了此方法。
12.7.3 GMRF 的采样
(1)采样方法
可以使用以下步骤从 GMRF 进行采样: 采样 z ∼ N ( 0 , I ) \mathbf{z} \sim \mathcal{N}(\mathbf{0, I}) z ∼ N ( 0 , I ) n n n L ⊤ v = z \mathbf{L^{\top} v = z} L ⊤ v = z x = μ + v \mathbf{x} = \boldsymbol{\mu} + \mathbf{v} x = μ + v x \mathbf{x} x E ( v ) = 0 \mathbb{E}(\mathbf{v}) = \mathbf{0} E ( v ) = 0 Cov ( v ) = L − ⊤ I L − 1 = ( L L ⊤ ) − 1 = Q − 1 \operatorname{Cov}(\mathbf{v}) = \mathbf{L}^{-\top} \mathbf{I} \mathbf{L}^{-1} = (\mathbf{LL}^{\top})^{-1} = \mathbf{Q}^{-1} Cov ( v ) = L − ⊤ I L − 1 = ( LL ⊤ ) − 1 = Q − 1
(2)计算对数密度
样本 x \mathbf{x} x
log π ( x ) = − n 2 log 2 π + 1 2 log ∣ Q ∣ − 1 2 ( x − μ ) ⊤ Q ( x − μ ) ⏟ q \log \pi(\mathbf{x}) =−\frac{n}{2} \log 2\pi + \frac{1}{2} \log |\mathbf{Q}| − \frac{1}{2} \underbrace{(\mathbf{x}-\boldsymbol{\mu})^{\top} \mathbf{Q} (\mathbf{x}-\boldsymbol{\mu})}_{q}
log π ( x ) = − 2 n log 2 π + 2 1 log ∣ Q ∣ − 2 1 q ( x − μ ) ⊤ Q ( x − μ )
其主要计算步骤如下:
计算 q q q :如果使用上述算法对 x \mathbf{x} x q = z ⊤ z q = \mathbf{z^{\top}z} q = z ⊤ z w = x − μ \boldsymbol{w} = \mathbf{x} − \boldsymbol{\mu} w = x − μ u = Q w \boldsymbol{u} = \mathbf{Q} \boldsymbol{w} u = Q w q = w ⊤ u q = \boldsymbol{w^{\top}u} q = w ⊤ u u = Q w \boldsymbol{u} = \mathbf{Q} \boldsymbol{w} u = Q w
u i = Q i , i w i + ∑ j : j ∼ i Q i , j w j u_i = \mathbf{Q}_{i,i} w_i + \sum\limits_{ j: j \sim i} \mathbf{Q}_{i,j} w_j
u i = Q i , i w i + j : j ∼ i ∑ Q i , j w j
由于 i i i i i i
计算 Q \mathbf{Q} Q : 可以从 Cholesky 分解中得到 ∣ Q ∣ = ∣ L L ⊤ ∣ = ∣ L ∣ 2 |\mathbf{Q}| = |\mathbf{LL}^{\top}| = |L|^2 ∣ Q ∣ = ∣ LL ⊤ ∣ = ∣ L ∣ 2 L \mathbf{L} L
1 2 log ∣ Q ∣ = ∑ i log L i , i \frac{1}{2} \log |\mathbf{Q}| = \sum\limits_{i} \log L_{i,i}
2 1 log ∣ Q ∣ = i ∑ log L i , i
(3)条件分布的采样
如 定理 12.2 中所述,对以 x B \mathbf{x}_B x B x A \mathbf{x}_A x A Q A A \mathbf{Q}_{AA} Q AA μ A ∣ B \mu_{A|B} μ A ∣ B
Q A A ( μ A ∣ B − μ A ) = − Q A B ( x B − μ B ) \mathbf{Q}_{AA}(\mu_{A|B} − \mu_{A}) = − \mathbf{Q}_{AB} (\mathbf{x}_B − \mu_{B})
Q AA ( μ A ∣ B − μ A ) = − Q A B ( x B − μ B )
依然可以使用正向和反向替换方法。右侧的(稀疏)矩阵向量乘积使用 Q A B \mathbf{Q}_{AB} Q A B
12.7.4 在线性约束条件下实施 GMRF 采样
(1)采样方法
在实际应用中,我们经常希望在线性约束下从 GMRF 中采样,
A x = e \mathbf{Ax = e}
Ax = e
对于秩为 k k k k × n k × n k × n A \mathbf{A} A k ≪ n k \ll n k ≪ n π ( x ∣ A x = e ) \pi(\mathbf{x |Ax = e}) π ( x∣Ax = e ) x i ⊥ x j ∣ x − { i , j } x_i \perp x_j | \mathbf{x}_{−\{i, j\}} x i ⊥ x j ∣ x − { i , j } ∑ x i = 0 \sum x_i = 0 ∑ x i = 0 x i x_i x i x j x_j x j x \mathbf{x} x x c \mathbf{x}^c x c
x c = x − Q − 1 A ⊤ ( A Q − 1 A ⊤ ) − 1 ( A x − e ) (12.19) \mathbf{x}^c = \mathbf{x} − \mathbf{Q}^{-1}\mathbf{A}^{\top} (A\mathbf{Q}^{-1}\mathbf{A}^{\top} )^{-1}(\mathbf{Ax-e}) \tag{12.19}
x c = x − Q − 1 A ⊤ ( A Q − 1 A ⊤ ) − 1 ( Ax − e ) ( 12.19 )
直接计算表明 x c \mathbf{x}^c x c 式 (12.19) 可以清楚地看到所有的矩阵项都很容易计算:
Q − 1 A ⊤ \mathbf{Q}^{-1}\mathbf{A}^{\top} Q − 1 A ⊤ Q v j = ( A ⊤ ) j \mathbf{Q} \mathbf{v}_j = (\mathbf{A}^{\top})_j Q v j = ( A ⊤ ) j k k k j = 1 , … , k j = 1,\ldots ,k j = 1 , … , k A Q − 1 A ⊤ \mathbf{A}\mathbf{Q}^{-1}\mathbf{A}^{\top} A Q − 1 A ⊤ k × k k × k k × k k k k
请注意,具有约束 k k k O ( n k 2 ) \mathcal{O}(nk^2) O ( n k 2 ) k k k
(2)计算对数密度
计算受约束的对数密度可能需要更多关注,因为 x ∣ A x \mathbf{x|Ax} x∣Ax n − k n − k n − k
π ( x ∣ A x ) = π ( A x ∣ x ) π ( x ) π ( A x ) \pi(\mathbf{x |Ax}) = \frac{\pi(\mathbf{Ax|x}) \pi(\mathbf{x})}{\pi(\mathbf{Ax})}
π ( x∣Ax ) = π ( Ax ) π ( Ax∣x ) π ( x )
现在请注意,右侧的所有项都很容易计算:
π ( x ) \pi(\mathbf{x}) π ( x ) μ \boldsymbol{\mu} μ Q \mathbf{Q} Q π ( A x ) \pi(\mathbf{Ax}) π ( Ax ) k k k A μ \mathbf{A}\boldsymbol{\mu} A μ A Q − 1 A ⊤ \mathbf{A}\mathbf{Q}^{-1}\mathbf{A}^{\top} A Q − 1 A ⊤ π ( A x ∣ x ) \pi(\mathbf{Ax|x}) π ( Ax∣x ) 0 0 0 x \mathbf{x} x A x \mathbf{Ax} Ax ∣ A A ⊤ ∣ − 1 / 2 |\mathbf{A}\mathbf{A}^{\top}|^{-1/2} ∣ A A ⊤ ∣ − 1/2
【例 12.7】
令 x \mathbf{x} x n n n { σ i 2 } \{\sigma^2_i \} { σ i 2 } x \mathbf{x} x x ∗ \mathbf{x}^* x ∗
x i ∗ = x i − c σ i 2 , 其中 c = ∑ x j / ∑ σ j 2 , i = 1 , … , n x^*_i = x_i − c\sigma^2_i ,\quad \text{其中} \quad c = \sum x_j / \sum \sigma^2_j \quad \text{,} \quad i= 1,\ldots ,n
x i ∗ = x i − c σ i 2 , 其中 c = ∑ x j / ∑ σ j 2 , i = 1 , … , n
上面的构造可以泛化至以 软约束 为条件,即以 k k k y = ( y 1 , … , y k ) ⊤ \mathbf{y} = ( y_1,\ldots ,y_k)^{\top} y = ( y 1 , … , y k ) ⊤
y ∣ x ∼ N ( A x , Υ ) \mathbf{y | x} \sim \mathcal{N}(\mathbf{Ax},\mathcal{\boldsymbol{\Upsilon}})
y∣x ∼ N ( Ax , Υ )
这里,A \mathbf{A} A k × n k × n k × n k k k Υ > 0 \mathbf{\boldsymbol{\Upsilon}} > 0 Υ > 0 x ∣ y \mathbf{x|y} x∣y Q + A ⊤ Υ − 1 A \mathbf{Q} + \mathbf{A}^{\top} \mathbf{\boldsymbol{\Upsilon}}^{-1} \mathbf{A} Q + A ⊤ Υ − 1 A 式 (12.19) 中相同的方法,现在将其概括为
x c = x − Q − 1 A ⊤ ( A Q − 1 A ⊤ + Υ ) − 1 ( A x − ϵ ) (12.21) \mathbf{x}^c = \mathbf{x} − \mathbf{Q}^{-1}\mathbf{A}^{\top} (\mathbf{AQ}^{-1}\mathbf{A}^{\top} + \boldsymbol{\Upsilon} )^{-1}(\mathbf{Ax} − \boldsymbol{\epsilon} ) \tag{12.21}
x c = x − Q − 1 A ⊤ ( AQ − 1 A ⊤ + Υ ) − 1 ( Ax − ϵ ) ( 12.21 )
其中 ϵ ∼ N ( y , Υ ) \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{y},\boldsymbol{\Upsilon}) ϵ ∼ N ( y , Υ )
(3)条件分布的采样
类似地,如果 x \mathbf{x} x π ( x ) \pi(\mathbf{x}) π ( x ) 式 (12.21) 计算的 x c \mathbf{x}^c x c π ( x ∣ y ) \pi(\mathbf{x} |\mathbf{y}) π ( x ∣ y ) 式 (12.20) 中相同的方法,有
π ( x ∣ y ) = π ( y ∣ x ) π ( x ) π ( y ) \pi(\mathbf{x} |\mathbf{y}) = \frac{ \pi(\mathbf{y|x}) \pi(\mathbf{x}) }{\pi(\mathbf{y})}
π ( x ∣ y ) = π ( y ) π ( y∣x ) π ( x )
此处,π ( x ) \pi(\mathbf{x}) π ( x ) π ( y ∣ x ) \pi(\mathbf{y|x}) π ( y∣x ) A x \mathbf{Ax} Ax Υ \boldsymbol{\Upsilon} Υ k k k π ( y ) \pi(\mathbf{y}) π ( y ) A μ \mathbf{A} \boldsymbol{\mu} A μ A Q − 1 A ⊤ + Υ \mathbf{A} \mathbf{Q}^{-1}\mathbf{A}^{\top} + \boldsymbol{\Upsilon} A Q − 1 A ⊤ + Υ k k k
12.7.5 Cholesky 分解的优化
上述所有精确模拟算法都基于 Cholesky 三角矩阵 L \mathbf{L} L Q \mathbf{Q} Q L L ⊤ \mathbf{LL}^{\top} LL ⊤
12.7.6 Cholesky 三角矩阵的解释
Q \mathbf{Q} Q
Q i , j = ∑ k = 1 j L i , k L j , k , i ≥ j Q_{i,j} = \sum^{j}_{k=1} L_{i,k} L_{j,k} \quad \text{,} \quad i \geq j
Q i , j = k = 1 ∑ j L i , k L j , k , i ≥ j
其中 L \mathbf{L} L k > i k > i k > i L i , k = 0 L_{i,k} = 0 L i , k = 0 n = 2 n = 2 n = 2 Q 1 , 1 = L 1 , 1 2 Q_{1,1} = L^2_{1,1} Q 1 , 1 = L 1 , 1 2 Q 2 , 1 = L 2 , 1 L 1 , 1 Q_{2,1} = L_{2,1} L_{1,1} Q 2 , 1 = L 2 , 1 L 1 , 1 Q 2 , 2 = L 2 , 1 L 2 , 1 + L 2 , 2 2 Q_{2,2} = L_{2,1} L_{2,1} + L^2_{2,2} Q 2 , 2 = L 2 , 1 L 2 , 1 + L 2 , 2 2 L 1 , 1 L_{1,1} L 1 , 1 L 2 , 1 L_{2,1} L 2 , 1 L 2 , 2 L_{2,2} L 2 , 2
这 n > 2 n > 2 n > 2 i = 1 , … , n i = 1,\ldots ,n i = 1 , … , n L i , 1 L_{i,1} L i , 1 i = 2 , … , n i = 2,\ldots ,n i = 2 , … , n L i , 2 L_{i,2} L i , 2 O ( n 3 ) \mathcal{O}(n^3) O ( n 3 )
利用精度矩阵或 Cholesky 三角矩阵中的特定结构可以加速 Cholesky 分解。对于 GMRF,Q \mathbf{Q} Q L \mathbf{L} L L j , i = 0 L_{j,i} = 0 L j , i = 0 L \mathbf{L} L
为了理解此问题,我们需要理解 L \mathbf{L} L L ⊤ x = z \mathbf{L}^{\top} \mathbf{x} = \mathbf{z} L ⊤ x = z z ∼ N ( 0 , I ) \mathbf{z} \sim \mathcal{N}(\mathbf{0, I}) z ∼ N ( 0 , I )
【定理 12.4】
设 x \mathbf{x} x G \mathcal{G} G μ \boldsymbol{\mu} μ Q \mathbf{Q} Q L \mathbf{L} L Q \mathbf{Q} Q i ∈ V i \in \mathcal{V} i ∈ V
E ( x i ∣ x ( i + 1 ) : n ) = μ i − 1 L i , i ∑ j = i + 1 n L j , i ( x j − μ j ) \mathbb{E}(x_i | \mathbf{x}_{(i+1):n}) = \mu_i − \frac{1}{L_{i,i}} \sum^{n}_{j=i+1} L_{j,i}(x_j − \mu_j )
E ( x i ∣ x ( i + 1 ) : n ) = μ i − L i , i 1 j = i + 1 ∑ n L j , i ( x j − μ j )
和
P r e c i s i o n ( x i ∣ x ( i + 1 ) : n ) = L i , i 2 Precision (x_i | \mathbf{x}_{(i+1):n} ) = L^2_{i,i}
P rec i s i o n ( x i ∣ x ( i + 1 ) : n ) = L i , i 2
也就是说,L L L x i x_i x i x j x_j x j j > i j > i j > i Q \mathbf{Q} Q x j x_j x j i i i Q i , i ≥ L i , i 2 \mathbf{Q}_{i,i} \geq L^2_{i,i} Q i , i ≥ L i , i 2
如果我们将 式 (12.2) 与 定理 12.4 合并,将得到以下结果。
【定理 12.5】
设 x \mathbf{x} x G \mathcal{G} G μ \boldsymbol{\mu} μ Q \mathbf{Q} Q L \mathbf{L} L Q \mathbf{Q} Q i i i j j j 1 ≤ i < j ≤ n 1 \leq i < j \leq n 1 ≤ i < j ≤ n
F ( i , j ) = { i + 1 , … , j − 1 , j + 1 , … , n } F (i, j) =\{i + 1, \ldots ,j− 1,j+ 1, \ldots ,n\}
F ( i , j ) = { i + 1 , … , j − 1 , j + 1 , … , n }
那么
x i ⊥ x j ∣ x F ( i , j ) ⇔ L j , i = 0 x_i \perp x_j | \mathbf{x}_{F (i, j)} \Leftrightarrow L_{ j,i} = 0
x i ⊥ x j ∣ x F ( i , j ) ⇔ L j , i = 0
所以,如果我们考虑 x i : n \mathbf{x}_{i:n} x i : n L j , i = 0 L_{j,i} = 0 L j , i = 0 x i x_i x i x j x_j x j { x i : n } \{\mathbf{x}_{i:n}\} { x i : n } L \mathbf{L} L { x i : n } \{x_{i:n}\} { x i : n } x i ⊥ x j ∣ x F ( i , j ) x_i \perp x_j | \mathbf{x}_{F(i,j)} x i ⊥ x j ∣ x F ( i , j ) 定理 12.3 中的全局马尔可夫性质。
【推论 12.1】
如果 F ( i , j ) F (i, j) F ( i , j ) i < j ∈ G i < j \in \mathcal{G} i < j ∈ G L j , i = 0 L_{j,i} = 0 L j , i = 0
这是一个主要的结果。如果我们可以仅仅通过图结构来验证 i < j i < j i < j F ( i , j ) F (i, j) F ( i , j ) Q \mathbf{Q} Q Q \mathbf{Q} Q L j , i = 0 L_{j,i} = 0 L j , i = 0 i < j i < j i < j F ( i , j ) F (i, j) F ( i , j ) L j , i L_{j,i} L j , i i ∼ j i \sim j i ∼ j L j , i L_{j,i} L j , i
【例 12.8】
考虑一个带有 图 12.1 中的图的 GMRF。然后我们知道 L 1 , 1 L_{1,1} L 1 , 1 L 2 , 2 L_{2,2} L 2 , 2 L 3 , 3 L_{3,3} L 3 , 3 L 4 , 4 L_{4,4} L 4 , 4 L 2 , 1 L_{2,1} L 2 , 1 L 3 , 2 L_{3,2} L 3 , 2 L 4 , 3 L_{4,3} L 4 , 3 L 4 , 1 L_{4,1} L 4 , 1 L 3 , 1 L_{3,1} L 3 , 1 L 4 , 2 L_{4,2} L 4 , 2 推论 12.1 检查它们;结点 1 和 3 由 F ( 1 , 3 ) = { 2 , 4 } F(1, 3) =\{2, 4\} F ( 1 , 3 ) = { 2 , 4 } L 3 , 1 L_{3,1} L 3 , 1 F ( 4 , 2 ) = { 3 } F (4, 2) =\{3\} F ( 4 , 2 ) = { 3 } L 4 , 2 L_{4,2} L 4 , 2
12.7.7 带状矩阵的 Cholesky 分解
尽管 例 12.8 中 Cholesky 三角矩阵中只有一个元素是必然为零的,但自回归模型通常会为我们带来大量的零元素。
设 x \mathbf{x} x p p p p p p
x t ∣ x t − 1 , … , x 1 ∼ N ( ϕ 1 x t − 1 + … + ϕ p x t − p , σ 2 ) , t = 1 , … , n x_{t} | x_{t-1}, \ldots ,x_1 \sim \mathcal{N}(\phi_1 x_{t-1} + \ldots +\phi_p x_{t−p}, \sigma^2),t= 1, \ldots ,n
x t ∣ x t − 1 , … , x 1 ∼ N ( ϕ 1 x t − 1 + … + ϕ p x t − p , σ 2 ) , t = 1 , … , n
为简单起见,我们设置 x 0 = x − 1 = … = x − p + 1 = 0 \mathbf{x}_0 = \mathbf{x}_{−1} = \ldots = \mathbf{x}_{−p+1} = 0 x 0 = x − 1 = … = x − p + 1 = 0
AR(p p p b w = p b_w = p b w = p 推论 12.1,可以得出对于所有 j − i > p , j > i j − i > p, \quad j > i j − i > p , j > i L j , i = 0 L_{j,i} = 0 L j , i = 0 L \mathbf{L} L
【定理 12.6】
如果 Q \mathbf{Q} Q b w b_w b w L \mathbf{L} L
在这个例子中,L \mathbf{L} L O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) O ( n ( b w + 1 ) ) \mathcal{O}(n(b_w + 1)) O ( n ( b w + 1 )) O ( n 3 ) \mathcal{O}(n^3) O ( n 3 ) O ( n b w 2 ) \mathcal{O}(nb_w^2) O ( n b w 2 ) n n n
12.7.8 重新排序技术:带状矩阵
带状矩阵的计算效率优势自然会引发这样一个问题:是否可以将此方法用于 “非带状” 但稀疏的矩阵? 一种合理的方法是:如果图中的索引是任意排列的,那么或许我们可以通过索引的重新排列获得更小的带宽,用其完成计算后,再将结果逆排列至原始索引顺序。
在形式上,可以令 P \mathbf{P} P n ! n! n ! n × n n × n n × n P \mathbf{P} P 1 1 1 P ⊤ P = I \mathbf{P^{\top} P} = \mathbf{I} P ⊤ P = I Q μ = b \mathbf{Q} \boldsymbol{\mu} = \mathbf{b} Q μ = b P \mathbf{P} P
( P Q P ⊤ ) ⏟ Q ~ P μ ⏟ μ ~ = P b ⏟ b ~ \underbrace{(\mathbf{P\mathbf{Q}P^{\top}})}_{\widetilde{\mathbf{Q}}} \underbrace{\mathbf{P} \boldsymbol{\mu}}_{\widetilde{\boldsymbol{\mu}}} = \underbrace{\mathbf{Pb}}_{\widetilde{\mathbf{b}}}
Q ( PQ P ⊤ ) μ P μ = b Pb
原问题被转换为求解 Q ~ μ ~ = b ~ \widetilde{ \mathbf{Q}} \widetilde{\mu} = \widetilde{\mathbf{b}} Q μ = b μ = P ⊤ μ ~ \boldsymbol{\mu} = \mathbf{P}^{\top} \widetilde{\boldsymbol{\mu} } μ = P ⊤ μ
下一个问题是如何置换稀疏矩阵以获得小带宽。这个问题有点技术性,但在计算机科学领域有大量文献(Duff、Erisman 和 Reid,1989 年;George 和 Liu,1981 年)和算法。因此,任何运行速度快并给出合理结果的算法都可以采纳。
图 12.4 显示了一个示例,其中 图 12.4a 显示了从空间应用中找到的精度矩阵(Rue 和 Held,2005 年,第 4.2.2 节),图 12.4b 是使用 Gibbs–Poole–Stockmeyer 重排序算法得到的结果 (Lewis, 1982),图 12.4c 是重排序精度矩阵的 Cholesky 三角矩阵。其中重新排序后的带宽为 38 38 38
12.7.9 重新排序技术:一般稀疏矩阵
虽然带状矩阵方法为某些图提供了非常有效的算法,但我们经常会遇到需要更通用方法的情况。一个典型例子是图中存在一些 “全局结点”,即某些结点与所有其他结点都相邻。在统计应用中,这种情况经常发生,如下例所示。
【例 12.9】
设 μ ∼ N ( 0 , 1 ) \boldsymbol{\mu} \sim \mathcal{N}(0, 1) μ ∼ N ( 0 , 1 ) { z t } \{z_t\} { z t } T T T μ \mu μ 1 1 1 x = ( z ⊤ , μ ) ⊤ \mathbf{x} = (\mathbf{z}^{\top} , \mu)^{\top} x = ( z ⊤ , μ ) ⊤ G \mathcal{G} G μ \mu μ n − 1 n − 1 n − 1 n = T + 1 n = T + 1 n = T + 1 n ! n! n !
带状矩阵方法在这个例子中并不成功,但我们可以通过使用一般(和复杂的)因式分解方案来推导有效的因式分解。一般方案仅计算 L \mathbf{L} L L \mathbf{L} L 推论 12.1 找到的 L \mathbf{L} L
然后通常使用填充数来比较任何重新排序的效率
fill-ins ( G ) = M ( G ) − ( ∣ V ∣ + ∣ E ∣ / 2 ) \operatorname{fill-ins}(\mathcal{G}) = M(\mathcal{G}) − (|\mathcal{V}|+|\mathcal{E}|/2)
fill-ins ( G ) = M ( G ) − ( ∣ V ∣ + ∣ E ∣/2 )
由于 L i , i > 0 L_{i,i} > 0 L i , i > 0 i i i i ∼ j i \sim j i ∼ j j > i j > i j > i fill-ins ( G ) ≥ 0 \operatorname{fill-ins}(\mathcal{G}) \geq 0 fill-ins ( G ) ≥ 0
p p p p p p 定理 12.6 )。对于其他 GMRF,填充数(在大多数情况下)是非零的,并且可以比较不同的重新排序方案以找到合理的重新排序。请注意,无需找到最佳重新排序,但任何合理的重新排序就足够了。
让我们重新考虑 例 12.9 ,我们比较了两个重新排序,其中全局结点 μ \boldsymbol{\mu} μ x = ( z ⊤ , μ ) ⊤ \mathbf{x} = (\mathbf{z}^{\top} , \mu)^{\top} x = ( z ⊤ , μ ) ⊤ x ′ = ( μ , z ⊤ ) ⊤ \mathbf{x}' = (\mu, \mathbf{z}^{\top})^{\top} x ′ = ( μ , z ⊤ ) ⊤
此处,× × × 推论 12.1,我们获得 Cholesky 三角矩阵的(一般)非零结构
其中 √ √ √ μ \mu μ
选择一组(小的)结点,移除这些结点会将图分成两个大小几乎相等的不连通子图
在对两个子图中的所有结点进行排序后对所选结点进行排序
将此过程递归地应用于每个子图中的结点
形式上,这可以描述如下:
【引理 12.2】
令 x \mathbf{x} x G \mathcal{G} G Q \mathbf{Q} Q x \mathbf{x} x ( x ⊤ A , x ⊤ B , x ⊤ C ) ⊤ (\mathbf{x}^{\top} \mathbf{A}, \mathbf{x}^{\top} \mathbf{B}, \mathbf{x}^{\top} \mathbf{C} )^{\top} ( x ⊤ A , x ⊤ B , x ⊤ C ) ⊤ Q \mathbf{Q} Q
L = ( L A A L B A L B B L C A L C B L C C ) \mathbf{L}= \begin{pmatrix} \mathbf{L}_{AA} & &\\ \mathbf{L}_{BA} & \mathbf{L}_{BB}& \\ \mathbf{L}_{CA} & \mathbf{L}_{CB}& \mathbf{L}_{CC} \end{pmatrix}
L = L AA L B A L C A L BB L CB L CC
如果 C C C G \mathcal{G} G A A A B B B L B A = 0 \mathbf{L}_{BA} = \mathbf{0} L B A = 0
递归方法通过类似地划分 A A A B B B n n n C C C A A A B B B O ( n 3 / 2 ) \mathcal{O}(n^{3/2}) O ( n 3/2 ) n \sqrt{n} n O ( n log n ) \mathcal{O}(n \log n) O ( n log n ) O ( n 3 / 2 ) \mathcal{O}(n^{3/2}) O ( n 3/2 ) n n n O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) O ( n 4 / 3 ) \mathcal{O}(n^{4/3}) O ( n 4/3 )
在长图和细图的带重新排序和格状图的嵌套剖面重新排序之间,还有其他几种重新排序方案可以根据具体情况提供更好的重新排序。尝试哪一个取决于哪个实现可用;但是,任何合理的重新排序选择都足够了。请注意,可以(通过稀疏矩阵库)计算特定图的填充数,而无需进行实际的因式分解,因为它仅取决于图;因此,如果应该对同一个图执行多个因式分解,比较(一些)重新排序并选择填充次数最少的一个可能会有好处。
我们通过重新访问 图 12.4a 中显示的 380 × 380 380 × 380 380 × 380 11 , 112 11,112 11 , 112 2 , 460 2,460 2 , 460 2 , 182 2,182 2 , 182 图 12.5 中。
12.7.10 批量边缘方差的精确计算
我们现在将转向一个更 “统计” 的问题;如何计算 GMRF 的所有(或几乎所有)边缘方差。这是一项不同于仅计算一个方差(比如 x i x_i x i Q v = 1 i \mathbf{Qv = 1_i} Qv = 1 i 1 i \mathbf{1}_i 1 i i i i 1 1 1 Var ( x i ) = v i \operatorname{Var}(x_i ) = v_i Var ( x i ) = v i Q \mathbf{Q} Q
12.7.11 一般递归
出发点再次是 L ⊤ x = z \mathbf{L}^{\top} \mathbf{x = z} L ⊤ x = z Q \mathbf{Q} Q x \mathbf{x} x
x i = z i / L i , i − 1 L i , i ∑ k = i + 1 n L k , i x k , i = n , … , 1 x_i = z_i /L_{i,i} − \frac{1}{L_{i,i}} \sum^{n}_{k=i+1} L_{k,i} x_k ,\qquad i = n, \ldots , 1
x i = z i / L i , i − L i , i 1 k = i + 1 ∑ n L k , i x k , i = n , … , 1
对于 j ≥ i j \geq i j ≥ i x j x_j x j
Σ i , j = δ i , j / L i , i 2 − 1 L i , i ∑ k = i + 1 n L k , i Σ k , j , j ≥ i , i = n , … , 1 (12.22) \Sigma_{i,j} = \delta_{i,j} / L^2_{i,i} − \frac{1}{L_{i,i}} \sum^{n}_{k=i+1} L_{k,i} \Sigma_{k, j}, \qquad j \geq i, i = n,\ldots , 1 \tag{12.22}
Σ i , j = δ i , j / L i , i 2 − L i , i 1 k = i + 1 ∑ n L k , i Σ k , j , j ≥ i , i = n , … , 1 ( 12.22 )
其中,如果 i = j i = j i = j δ i , j \delta_{i,j} δ i , j 1 1 1 0 0 0 式 (12.22) 中的和只需要在所有非零 L j , i L_{j,i} L j , i k k k i i i k > i k > i k > i F ( i , k ) F (i, k) F ( i , k ) 推论 12.1。为了简化符号,将此索引集定义为
I ( i ) = { k > i : i 和 k 不被 F ( i , k ) 分隔 } \mathcal{I}(i) = \{k > i : i \quad \text{和} \quad k \quad \text{不被} \quad F (i, k) \quad \text{分隔} \quad \}
I ( i ) = { k > i : i 和 k 不被 F ( i , k ) 分隔 }
和他们的 “联合”,
I = { { i , k } : k > i , i 和 k 不被 F ( i , k ) 分隔 } \mathcal{I} =\left \{\{i, k\} : k > i, i \quad \text{和} \quad k \quad \text{不被} \quad F (i, k) \quad \text{分隔} \quad \right \}
I = { { i , k } : k > i , i 和 k 不被 F ( i , k ) 分隔 }
对于 k , i = 1 , … , n k,i = 1,\ldots ,n k , i = 1 , … , n I \mathcal{I} I { i , j } ∈ I \{i, j\}\in \mathcal{I} { i , j } ∈ I { j , i } \{j, i\} { j , i } I \mathcal{I} I L \mathbf{L} L 式 (12.22) 变为
Σ i , j = δ i , j / L i , i 2 − 1 L i , i ∑ k ∈ I ( i ) L k , i Σ k , j , j ≥ i , i = n , … , 1 (12.23) \Sigma_{i,j} = \delta_{i,j} / L^2_{i,i} − \frac{1}{L_{i,i}} \sum\limits_{ k \in \mathcal{I} (i)} L_{k,i} \Sigma_{k, j},\qquad j \geq i, i = n,\ldots, 1 \tag{12.23}
Σ i , j = δ i , j / L i , i 2 − L i , i 1 k ∈ I ( i ) ∑ L k , i Σ k , j , j ≥ i , i = n , … , 1 ( 12.23 )
更仔细地研究这些方程,结果表明,如果以正确的顺序应用 式 (12.23),我们可以显式计算所有 Σ i , j \Sigma_{i,j} Σ i , j
尽管这个直接过程计算了所有边缘方差 Σ n , n , … , Σ 1 , 1 \Sigma_{n,n},\ldots , \Sigma_{1,1} Σ n , n , … , Σ 1 , 1 Σ i , j \Sigma_{i,j} Σ i , j J \mathcal{J} J { i , j } \{i, j\} { i , j } 式 (12.23) 计算 Σ i , j \Sigma_{i,j} Σ i , j
【需求 1】 J \mathcal{J} J { 1 , 1 } , … , { n , n } \{1, 1\},\ldots , \{n, n\} { 1 , 1 } , … , { n , n }
【要求 2】 在从 式 (12.23) 计算 Σ i , j \Sigma_{i,j} Σ i , j Σ k , j \Sigma_{k,j} Σ k , j
{ i , j } ∈ J 且 k ∈ I ( i ) ⇒ { k , j } ∈ J (12.24) \{i, j\}\in \mathcal{J} \quad \text{且} \quad k \in \mathcal{I}(i) \Rightarrow \{ k, j\} \in \mathcal{J} \tag{12.24}
{ i , j } ∈ J 且 k ∈ I ( i ) ⇒ { k , j } ∈ J ( 12.24 )
相当令人惊讶的结果是 J = I \mathcal{J = I} J = I G \mathcal{G} G Q \mathbf{Q} Q
对于 i = n , … , 1 i = n,\ldots , 1 i = n , … , 1 I ( i ) \mathcal{I}(i) I ( i ) j j j 式 (12.23) 计算 Σ i , j \Sigma_{i,j} Σ i , j
其中 j j j I ( i ) \mathcal{I}(i) I ( i ) 需求 1 平凡为真,需求 2 通过验证方程 式 (12.24) 得到验证: { i , j } ∈ J , j ≥ i \{i, j\}\in \mathcal{J} , j \geq i { i , j } ∈ J , j ≥ i i i i j j j i i i k ∈ I ( i ) k \in \mathcal{I}(i) k ∈ I ( i ) i i i k k k i i i k ≤ j k \leq j k ≤ j k k k i i i j j j k k k k > i k > i k > i k > j k > j k > j k k k i i i j j j j j j j ≥ i j \geq i j ≥ i
解决这些递归的计算成本比分解精度矩阵要小。考虑使用嵌套剖面重新排序的 2D 方格重新排序,然后 ∣ I ∣ = O ( n log n ) |\mathcal{I}|=\mathcal{O}(n \log n) ∣ I ∣ = O ( n log n ) Σ i , j \Sigma_{i,j} Σ i , j O ( log n ) \mathcal{O}(\log n) O ( log n ) O ( n ( log n ) 2 ) \mathcal{O}(n(\log n)^2) O ( n ( log n ) 2 ) O ( n 5 / 3 ) \mathcal{O}(n^{5/3}) O ( n 5/3 )
12.7.12 带状矩阵的递归
当 Q \mathbf{Q} Q b w b_w b w I ( i ) = { i + 1 , … , min ( n , i + b w ) } \mathcal{I}(i) =\{i + 1,\ldots , \min(n, i + b_w)\} I ( i ) = { i + 1 , … , min ( n , i + b w )} 定理 12.6 。在这种情况下,需求 2 需求 2 需求 2 j ≥ i j \geq i j ≥ i
0 ≤ j − i ≤ b w 和 0 < k − i ≤ b w ⇒ − b w ≤ k − j ≤ b w 0 \leq j − i \leq b_w \quad \text{和} \quad 0 < k − i \leq b_w \Rightarrow − b_w \leq k − j \leq b_w
0 ≤ j − i ≤ b w 和 0 < k − i ≤ b w ⇒ − b w ≤ k − j ≤ b w
这是千真万确的。然后算法变成
请注意,此算法在形式上等同于用于平滑的卡尔曼递归。自回归模型的计算成本为 O ( n ) \mathcal{O}(n) O ( n )
12.7.13 校正线性约束
使用额外的线性约束,受约束的精度矩阵将不那么稀疏,因此我们需要一种方法来校正额外线性约束的边缘方差。这类似于方程 式 (12.19) 。设 Σ ~ \widetilde{\Sigma} Σ k k k A x = e \mathbf{Ax = e} Ax = e Σ \Sigma Σ
Σ ~ = Σ − Q − 1 A ⊤ ( A Q − 1 A ⊤ ) − 1 A Q − 1 (12.25) \tilde{\boldsymbol{\Sigma}} = \boldsymbol{\Sigma} − \mathbf{Q}^{-1}\mathbf{A}^{\top} (A\mathbf{Q}^{-1}\mathbf{A}^{\top} )^{-1} A\mathbf{Q}^{-1} \tag{12.25}
Σ ~ = Σ − Q − 1 A ⊤ ( A Q − 1 A ⊤ ) − 1 A Q − 1 ( 12.25 )
令 W \mathbf{W} W Q W = A ⊤ \mathbf{QW} = \mathbf{A}^{\top} QW = A ⊤ n × k n×k n × k V \mathbf{V} V A W \mathbf{AW} AW k × k k×k k × k Υ \boldsymbol{\Upsilon} Υ V Υ = W ⊤ \mathbf{V}\boldsymbol{\Upsilon} = \mathbf{W}^{\top} V Υ = W ⊤ k × n k×n k × n 式(12.25) 的第 i i i j j j
Σ ~ i , j = Σ i , j − ∑ t = 1 k Υ t , i Υ t , j (12.26) \tilde{\Sigma}_{i,j} = \Sigma_{i,j} − \sum^{k}_{t=1} \Upsilon_{t,i} \Upsilon_{t, j} \tag{12.26}
Σ ~ i , j = Σ i , j − t = 1 ∑ k Υ t , i Υ t , j ( 12.26 )
我们通过求解方程 式 (12.23) 计算的所有 Σ \boldsymbol{\Sigma} Σ 式 (12.26) 进行校正。此校正的计算成本主要是计算 Υ \boldsymbol{\Upsilon} Υ O ( n k 2 ) \mathcal{O}(nk^2) O ( n k 2 )
12.7.14 一些实际问题
虽然可以使用稀疏矩阵的数值方法来进行 GMRF 计算,但它并非没有实际麻烦。
首先,相当多的库有免费的二进制版本但封闭源代码,这会造成复杂性。由于只有少数库具有解决 L ⊤ x = z \mathbf{L}^{\top} \mathbf{x = z} L ⊤ x = z
由于开源,提供求解 L ⊤ x = z \mathbf{L}^{\top} \mathbf{x = z} L ⊤ x = z 式 (12.23) 中使用计算的 L L L L j \mathbf{L}_j L j
12.8 马尔可夫随机场
我们现在将离开高斯案例并更一般地讨论马尔可夫随机场 (MRF)。我们将首先研究每个 x i x_i x i K K K x i ∈ S i = { 0 , 1 , … , K − 1 } x_i \in \mathcal{S}_i =\{0, 1,\ldots ,K− 1\} x i ∈ S i = { 0 , 1 , … , K − 1 } x ∈ S = S 1 × S 2 × ⋯ × S n \mathbf{x} \in \mathcal{S} = \mathcal{S}_1 × \mathcal{S}_2 ×\dots×\mathcal{ S}_n x ∈ S = S 1 × S 2 × ⋯ × S n K = 2 K = 2 K = 2 定理 12.7 推广到非有限 S \mathcal{S} S
12.8.1 背景
回想一下联合分布 π ( x ) \pi(\mathbf{x}) π ( x ) n n n π ( x i ∣ x − i ) \pi(x_i |\mathbf{x}_{-i} ) π ( x i ∣ x − i )
【定义 12.3(邻居)】
如果 x j x_j x j x i x_i x i j ≠ i j \neq i j = i i i i
用 ∂ i ∂i ∂ i i i i i i i
π ( x i ∣ x − i ) = π ( x i ∣ x ∂ i ) \pi(x_i | \mathbf{x}_{-i} ) = \pi(x_i | \mathbf{x}_{∂i})
π ( x i ∣ x − i ) = π ( x i ∣ x ∂ i )
在空间环境中,很容易将其可视化,例如,将 ∂ i ∂i ∂ i i i i
当我们想要使用自下而上的方法通过 n n n ∂ i ∂i ∂ i x \mathbf{x} x
π ( x i ∣ x − i ) ∝ π ( x ) \pi(x_i | \mathbf{x}_{-i} ) \propto \pi(\mathbf{x})
π ( x i ∣ x − i ) ∝ π ( x )
但是,如果我们只知道完全条件分布,我们如何导出联合分布呢?令 x ∗ \mathbf{x}^{*} x ∗ π ( x ∗ ) > 0 \pi(\mathbf{x}^{*}) > 0 π ( x ∗ ) > 0 引理 12.1)给出 n = 2 n = 2 n = 2
π ( x 1 , x 2 ) = π ( x 1 ∗ , x 2 ∗ ) π ( x 1 ∣ x 2 ) π ( x 1 ∗ ∣ x 2 ) ⋅ π ( x 2 ∣ x 1 ∗ ) π ( x 2 ∗ ∣ x 1 ∗ ) (12.27) \pi(x_1,x_2) = \pi(\mathbf{x}^{*}_1 ,\mathbf{x}^{*}_2) \frac{\pi(x_1|x_2)}{ \pi(\mathbf{x}^{*}_1 |x_2)} \cdot \frac{\pi ( x_2 |\mathbf{x}^{*}_1)}{ \pi(\mathbf{x}^{*}_2 |\mathbf{x}^{*}_1 )} \tag{12.27}
π ( x 1 , x 2 ) = π ( x 1 ∗ , x 2 ∗ ) π ( x 1 ∗ ∣ x 2 ) π ( x 1 ∣ x 2 ) ⋅ π ( x 2 ∗ ∣ x 1 ∗ ) π ( x 2 ∣ x 1 ∗ ) ( 12.27 )
前提是分母中没有零,这意味着(通常)
π ( x ) > 0 , ∀ x ∈ S \pi(\mathbf{x}) > 0, ∀ \mathbf{x} \in S
π ( x ) > 0 , ∀ x ∈ S
我们将这种条件称为积极性条件,它在下文中被证明是必不可少的。如果我们对所有 x ∈ S \mathbf{x} \in S x ∈ S x ∗ \mathbf{x}^{*} x ∗ 0 0 0 式(12.27) ,那么我们就知道 h ( x ) h(\mathbf{x}) h ( x ) π ( x ) ∝ h ( x ) \pi(\mathbf{x}) \propto h(\mathbf{x}) π ( x ) ∝ h ( x ) ∑ x ∈ S π ( x ) = 1 \sum_{\mathbf{x} \in S} \pi(\mathbf{x}) = 1 ∑ x ∈ S π ( x ) = 1
这个论点有一个小问题,即完全条件分布是(或可以)从联合分布中导出的隐含假设。然而,如果我们指定完全条件分布的候选者,那么我们必须确保我们获得相同的联合分布,而不管导致 式(12.27) 的排序选择如何,例如,
π ( x 1 , x 2 ) = π ( x 1 ∗ , x 2 ∗ ) π ( x 2 ∣ x 1 ) π ( x 1 ∣ x 2 ∗ ) π ( x 2 ∗ ∣ x 1 ) π ( x 1 ∗ ∣ x 2 ∗ ) \pi(x_1,x_2) = \pi(\mathbf{x}^{*}_1 ,\mathbf{x}^{*}_2) \frac{\pi(x_2|x_1)}{\pi (x_1 |\mathbf{x}^{*}_2)} \frac{ \pi(\mathbf{x}^{*}_2 |x_1)}{ \pi(\mathbf{x}^{*}_1 |\mathbf{x}^{*}_2)}
π ( x 1 , x 2 ) = π ( x 1 ∗ , x 2 ∗ ) π ( x 1 ∣ x 2 ∗ ) π ( x 2 ∣ x 1 ) π ( x 1 ∗ ∣ x 2 ∗ ) π ( x 2 ∗ ∣ x 1 )
当然,这两个指定必须一致。对于 n > 2 n > 2 n > 2
12.8.2 哈默斯利-克利福德( Hammersley–Clifford )定理
让 G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G = ( V , E ) V = { 1 , … , n } \mathcal{V} =\{1,\ldots ,n\} V = { 1 , … , n } j ∈ ∂ i j \in ∂i j ∈ ∂ i i ∉ ∂ j i \notin ∂j i ∈ / ∂ j j j j i i i i i i j j j i i i j j j j j j i i i
【定义 12.4(马尔可夫随机场)】 如果 π ( x ) , x ∈ S \pi(\mathbf{x}), \mathbf{x} \in \mathcal{S} π ( x ) , x ∈ S G \mathcal{G} G G \mathcal{G} G
对于主要结果,我们还需要 “团” 的概念。
【定义 12.5(团)】
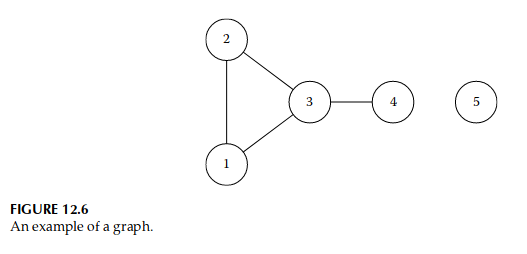
任何单一测点或内部不同测点之间相互都是邻居的一组测点,被称为 “团” 。
【示例 12.10】 图 12.6 中图中的 “团” 为: { 1 } \{1\} { 1 } { 2 } \{2\} { 2 } { 3 } \{3\} { 3 } { 4 } \{4\} { 4 } { 5 } \{5\} { 5 } { 1 , 2 } \{1, 2\} { 1 , 2 } { 1 , 3 } \{1, 3\} { 1 , 3 } { 2 , 3 } \{2, 3\} { 2 , 3 } { 1 , 2 , 3 } \{ 1, 2, 3\} { 1 , 2 , 3 } { 3 , 4 } \{3, 4\} { 3 , 4 }
主要结论是 Hammersley–Clifford 定理(参见 Clifford,1990 ),它说明联合分布必须采用什么形式才能符合给定的图 G \mathcal{G} G
【定理 12.7 (Hammersley–Clifford)】
令 π ( x ) > 0 , x ∈ S \pi(\mathbf{x}) > 0, \mathbf{x} \in \mathcal{S} π ( x ) > 0 , x ∈ S C \mathcal{C} C G \mathcal{G} G
π ( x ) ∝ ∏ C ∈ C Ψ C ( x C ) (12.28) \pi(\mathbf{x}) \propto \prod\limits_{ C \in \mathcal{C}} \Psi_C (\mathbf{x}_C) \tag{12.28}
π ( x ) ∝ C ∈ C ∏ Ψ C ( x C ) ( 12.28 )
其中函数 Ψ C \Psi_C Ψ C 0 < Ψ C ( x C ) < ∞ 0 < \Psi_C (\mathbf{x}_C ) < \infty 0 < Ψ C ( x C ) < ∞
这个结果有一个有趣的历史;参见 Besag (1974) 和 Clifford (1990) 的章节。这个结论的一个重要结果是:对于给定的图,完全条件分布应该要么通过 Ψ \Psi Ψ Ψ \Psi Ψ 式(12.28) 导出的所选完全条件分布验证。
【示例 12.11】
图 12.6 对应的一般分布形式是:
π ( x 1 , x 2 , x 3 , x 4 , x 5 ) ∝ Ψ 1 , 2 , 3 ( x 1 , x 2 , x 3 ) Ψ 3 , 4 ( x 3 , x 4 ) Ψ 5 ( x 5 ) \pi(x_1,x_2,x_3,x_4,x_5) \propto \Psi_{1,2,3}(x_1,x_2,x_3) \Psi_{3,4}(x_3,x_4) \Psi_5(x_5)
π ( x 1 , x 2 , x 3 , x 4 , x 5 ) ∝ Ψ 1 , 2 , 3 ( x 1 , x 2 , x 3 ) Ψ 3 , 4 ( x 3 , x 4 ) Ψ 5 ( x 5 )
我们现在将陈述 Hammersley-Clifford 定理的一些推论:
【推论 12.2】 图 G \mathcal{G} G i ∈ ∂ j i \in ∂j i ∈ ∂ j j ∈ ∂ i j \in ∂i j ∈ ∂ i
【推论 12.3】 式(12.28) 的MRF 也满足全局马尔可夫性质 式(12.4) 。
【推论 12.4】 如果定义 Q ( x ) = log ( π ( x ) / π ( 0 ) ) Q(\mathbf{x}) = \log(\pi(\mathbf{x})/\pi(\mathbf{0})) Q ( x ) = log ( π ( x ) / π ( 0 ))
Q ( x ) = ∑ i x i G i ( x i ) + ∑ i < j x i x j G i , j ( x i , x j ) + ∑ i < j < k x i x j x k G i , j , k ( x i , x j , x k ) + … j + x 1 x 2 … x n G 1 , 2 , … , n ( x 1 , x 2 , … , x n ) (12.29) Q(\mathbf{x}) = \sum\limits_{i} x_i G_i(x_i ) + \sum\limits_{i<j} x_i x_j G_{i, j} (x_i ,x_j ) + \sum\limits_{i< j<k} x_i x_j x_k G_{i, j,k}(x_i ,x_j ,x_k ) + \ldots \\j+ x_1 x_2 \ldots x_n G_{1,2,\ldots ,n}(x_1,x_2,\ldots ,x_n) \tag{12.29}
Q ( x ) = i ∑ x i G i ( x i ) + i < j ∑ x i x j G i , j ( x i , x j ) + i < j < k ∑ x i x j x k G i , j , k ( x i , x j , x k ) + … j + x 1 x 2 … x n G 1 , 2 , … , n ( x 1 , x 2 , … , x n ) ( 12.29 )
其中 G i , j , … , s ( x i , x j , … , x s ) ≡ 0 G_{i, j,\ldots,s}(x_i ,x_j ,\ldots ,x_s) \equiv 0 G i , j , … , s ( x i , x j , … , x s ) ≡ 0 i , j , … , s i, j,\ldots , s i , j , … , s G G G
【推论 12.5】 Hammersley–Clifford 定理可以扩展到多元 MRF,其中每个 x i \mathbf{x}_i x i p p p π ( x ) \pi(\mathbf{x}) π ( x ) S S S
式(12.28) 的联合分布也可以写成
π ( x ) = 1 Z exp ( − ∑ C ∈ C V C ( x C ) ) \pi(\mathbf{x}) = \frac{1}{Z} \exp \left( − \sum\limits_{ C \in \mathcal{C}} V_C (\mathbf{x}_C) \right)
π ( x ) = Z 1 exp ( − C ∈ C ∑ V C ( x C ) )
其中 V C ( ⋅ ) = − log Ψ C ( ⋅ ) V_C (·) =−\log \Psi_C (·) V C ( ⋅ ) = − log Ψ C ( ⋅ ) Z Z Z V C ( ⋅ ) V_C(·) V C ( ⋅ )
12.8.3 二值 MRF
我们现在将更详细地讨论 K = 2 K = 2 K = 2 ∂ i ∂i ∂ i i i i 式(12.29) 。对于某些 α i \alpha_i α i α i , j \alpha_{i,j} α i , j
Q ( x ) = ∑ i α i x i + ∑ i < j α i , j x i x j Q(\mathbf{x}) = \sum\limits_{i} \alpha_i x_i + \sum\limits_{i<j} \alpha_{i, j} x_i x_j
Q ( x ) = i ∑ α i x i + i < j ∑ α i , j x i x j
这是给定图的分布可以采用的通用形式。对于 β i , j = β j , i = α i , j , i < j \beta_{i,j} = \beta_{j,i} = \alpha_{i, j}, i < j β i , j = β j , i = α i , j , i < j x \mathbf{x} x
π ( x ) = 1 Z exp ( ∑ i α i x i + ∑ i ∼ j β i j x i x j ) \pi(\mathbf{x}) = \frac{1}{Z} \exp \left( \sum\limits_{i} \alpha_i x_i + \sum\limits_{ i \sim j} \beta_{ij}x_i x_j\right)
π ( x ) = Z 1 exp ( i ∑ α i x i + i ∼ j ∑ β ij x i x j )
参数 { α i } \{\alpha_i \} { α i } { β i , j \{\beta_{i,j} { β i , j
π ( x i ∣ x − i ) = exp ( x i ( α i + ∑ j ∈ ∂ i β i , j x j ) ) 1 + exp ( α i + ∑ j ∈ ∂ i β i , j x j ) \pi(x_i | \mathbf{x}_{-i} ) = \frac{ \exp \left( x_i (\alpha_i + \sum\limits_{ j\in ∂i} \beta_{i,j} x_j) \right)}{ 1 + \exp \left( \alpha_i + \sum\limits_{ j\in ∂i} \beta_{i,j} x_j \right)}
π ( x i ∣ x − i ) = 1 + exp ( α i + j ∈ ∂ i ∑ β i , j x j ) exp ( x i ( α i + j ∈ ∂ i ∑ β i , j x j ) )
x i x_i x i
式(12.31) 的一个有趣的特例是
π ( x ∣ β ) = 1 Z β exp ( β ∑ i ∼ j 1 [ x i = x j ] ) (12.32) \pi(\mathbf{x} | \beta) = \frac{1}{Z_{\beta}} \exp \left ( \beta \sum\limits_{ i \sim j} 1 [x_i = x_j ] \right) \tag{12.32}
π ( x ∣ β ) = Z β 1 exp ( β i ∼ j ∑ 1 [ x i = x j ] ) ( 12.32 )
其中 1 [ ⋅ ] 1[·] 1 [ ⋅ ] β \beta β Ising 模型,可追溯到 1925 年的 Ernst Ising。为了以后使用,我们写成 ∣ β |\beta ∣ β β \beta β 式(12.32) 重写为
π ( x ∣ β ) = 1 Z β exp ( β × 相等邻居的数量 ) \pi(\mathbf{x} | \beta) = \frac{1}{Z_{\beta}} \exp (\beta \times \text{相等邻居的数量} )
π ( x ∣ β ) = Z β 1 exp ( β × 相等邻居的数量 )
因此,实现将有利于邻居平等,但对于邻居应该处于哪个状态 0 0 0 1 1 1
π ( x i = 1 ∣ β , x ∂ i ) = exp ( β n 1 ) exp ( β n 0 ) + exp ( β n 1 ) ′ \pi(x_i = 1 | \beta, \mathbf{x}_{∂i} ) = \frac{\exp(\beta_{n1})}{\exp(\beta_{ n0 }) + \exp(\beta_{n1})'}
π ( x i = 1∣ β , x ∂ i ) = exp ( β n 0 ) + exp ( β n 1 ) ′ exp ( β n 1 )
其中 n 0 n_0 n 0 x i x_i x i n 1 n_1 n 1 x i x_i x i β ∗ \beta^* β ∗ log ( 1 + 2 ) = 0.88 … \log(1 + \sqrt{2} ) = 0.88 \ldots log ( 1 + 2 ) = 0.88 … β > β ∗ \beta > \beta^* β > β ∗ x i x_i x i x j x_j x j
12.9 面向 MRF 的 MCMC
12.9.1 固定 β \beta β
我们现在将讨论如何从固定 β \beta β π ( x ) \pi(\mathbf{x}) π ( x ) 式(12.30) 。 第 12.5.2 节 中的 Gibbs 采样器也适用于离散 MRF。
同样,要更新 x i x_i x i x ∂ i \mathbf{x}_{∂i} x ∂ i
直觉上,在 β \beta β x \mathbf{x} x 1 − x \mathbf{1 − x} 1 − x i i i Metropolis–Hastings 算法。
我们应该接受提议的新状态 p i p_i p i x ∂ i \mathbf{x}_{∂i} x ∂ i R i ≥ 1 R_i \geq 1 R i ≥ 1
图 12.7 显示了来自 64 × 64 64 × 64 64 × 64 β = 0.6 、 0.88 … \beta = 0.6、0.88\ldots β = 0.6 、 0.88 … 1.0 1.0 1.0 β ∗ \beta^* β ∗ β ∗ \beta^* β ∗
12.9.2 随机 β \beta β
我们在 例 12.4 中的 MCMC 算法中遇到了复杂情况,当时交互参数 δ \delta δ δ \delta δ 式(12.17) 。在离散 MRF 的情况下,由于同样的原因, β \beta β
回想一下 Z ( β ) Z(\beta) Z ( β )
Z ( β ) = ∑ x exp ( β S ( x ) ) (12.33) Z(\beta) = \sum\limits_{\mathbf{x}} \exp(\beta S(\mathbf{x})) \tag{12.33}
Z ( β ) = x ∑ exp ( βS ( x )) ( 12.33 )
其中 S ( x ) S(\mathbf{x}) S ( x ) ∑ i ∼ j 1 [ x i = x j ] \sum\limits_{ i \sim j} 1[x_i = x_j] i ∼ j ∑ 1 [ x i = x j ] Z ( β ) Z(\beta) Z ( β ) β \beta β Z ( β ) Z(\beta) Z ( β )
d Z ( β ) d β = ∑ x S ( x ) exp ( β S ( x ) ) = Z ( β ) ∑ x ( S ( x ) ) exp ( β S ( x ) ) / Z ( β ) = Z ( β ) E x ∣ β S ( x ) \begin{align*}
\frac{dZ(\beta)}{d\beta} &= \sum\limits_{\mathbf{x}} S(\mathbf{x}) \exp(\beta S(\mathbf{x})) \\
&= Z(\beta) \sum\limits_{\mathbf{x}} (S(\mathbf{x})) \exp(\beta S(\mathbf{x})) /Z(\beta)\\
&= Z(\beta )\mathbb{E}_{\mathbf{x}|\beta} S(\mathbf{x})
\end{align*}
d β d Z ( β ) = x ∑ S ( x ) exp ( βS ( x )) = Z ( β ) x ∑ ( S ( x )) exp ( βS ( x )) / Z ( β ) = Z ( β ) E x ∣ β S ( x )
通过解微分方程,我们得到
log ( Z ( β ′ ) / Z ( β ) ) = ∫ β β ′ E x ∣ β ~ S ( x ) d β ~ (12.34) \log (Z(\beta')/Z(\beta)) = \int^{\beta'}_{\beta} \mathbb{E} _{\mathbf{x}| \tilde{ \beta}} S(\mathbf{x}) d \tilde{\beta} \tag{12.34}
log ( Z ( β ′ ) / Z ( β )) = ∫ β β ′ E x ∣ β ~ S ( x ) d β ~ ( 12.34 )
正如我们所见,这一技巧已将问题的难度降低到可以使用以下过程解决的问题(有关应用,请参阅 Hurn、Husby 和 Rue,2003 年)。
使用基于一系列 MCMC 算法的输出的后验均值估计,估计一系列不同 β \beta β E x ∣ β S ( x ) \mathbb{E}_{\mathbf{x}|\beta} S(\mathbf{x}) E x ∣ β S ( x )
2.构造平滑样条 f ( β ) f(\beta) f ( β ) E x ∣ β S ( x ) \mathbb{E}_{\mathbf{x}|\beta} S(\mathbf{x}) E x ∣ β S ( x )
使用 f ( β ) f(\beta) f ( β ) 式(12.34) 的估计,
log ( Z ( β ′ ) ^ / Z ( β ) ) = ∫ β β ′ f ( β ~ ) d β ~ \log ( \widehat{ Z(\beta')}/Z(\beta)) = \int^{ \beta'}_{ \beta} f(\tilde{\beta}) d \tilde{\beta}
log ( Z ( β ′ ) / Z ( β )) = ∫ β β ′ f ( β ~ ) d β ~
式(12.34) 背后的思想在物理学文献中通常称为热力学积分,请参阅 Gelman 和 Meng (1998) 从统计角度进行很好的介绍。 Geyer 和 Thompson (1992) 也有类似的想法。伪似然法(Besag,J.E.,1974)是一种早期但仍然流行的方法,用于推断离散值 MRF(Frank 和 Strauss,1986;Strauss 和 Ikeda,1990),参见 Robins、Snijders、Wang、Handcock 等阿尔。 (2007) 更新概览。