
贝叶斯神经网络技术浅析
〖摘 要〗神经网络已经为许多机器学习任务提供了最先进的结果,例如计算机视觉、语音识别和自然语言处理领域的检测、回归和分类任务等。尽管取得了成功,但它们通常是在频率学派框架内实施的,这意味着其无法对预测中的不确定性进行推断。本文介绍了贝叶斯神经网络及一些开创性研究,对不同近似推断方法进行了比较,并提出未来改进的一些方向。
〖原 文〗Goan, E., & Fookes, C. (2020). Bayesian Neural Networks: An Introduction and Survey. https://arxiv.org/abs/2006.12024
〖阅后感〗获得神经网络预测不确定性的方法有很多种(参见《深度神经网络中的不确定性调研报告》),而本文主要介绍其中的贝叶斯神经网络方法。内容涉及浅层神经网络中的贝叶斯方法尝试、深层神经网络中面临的问题即推断方法等。
1 引言
长期以来,仿生学一直是技术发展的基础。科学家和工程师反复使用物理世界的知识来模仿自然界对经过数十亿年演变而来的复杂问题的优雅解决方案。生物仿生学在统计学和机器学习中的重要应用是发展了感知机 [1],它提出了一个基于神经元生理学的数学模型。机器学习领域已使用该概念开发了高度互连的神经元阵列统计模型,创建了神经网络。
虽然神经网络的概念早在几十年前就已为人所知,但其应用直到最近才显现出来。神经网络研究的停滞很大程度上由三个关键因素造成:
- 缺乏足够的算法来训练这些网络。
- 训练复杂网络所需的大量数据。
- 训练过程所需大量计算资源。
1986 年,[3] 引入了反向传播算法解决了网络的有效训练问题。虽然有了有效的训练手段,但网络规模不断扩大,仍然需要相当多计算资源。该问题在 [4] [5] [6] 中得到了解决,其表明通用 GPU 可有效执行训练所需的许多操作。随着硬件不断进步,能够捕获和存储真实世界数据的传感器数量不断增加。通过高效训练方法、改进的计算资源和庞大的数据集,复杂神经网络的训练已经变得真正可行。
在绝大多数情况下,神经网络都是在频率主义框架内使用的;通过使用有效的数据,用户可以定义网络结构和成本函数,然后对其进行优化,以获得模型参数的点估计。增加神经网络参数(权重)的数量或网络深度会增加神经网络的容量,使其能够表示强非线性函数,进而允许神经网络处理更复杂的任务。但频率主义框架也很容易由于参数过多而产生过拟合问题,但使用大型数据集和正则化方法(如寻找最大后验估计),可以限制网络所学习函数的复杂性,并有助于避免过拟合。
神经网络已经为许多机器学习和人工智能应用提供了最先进的结果,例如图像分类 [6] [7] [8] ,目标检测 [9] [10] [11] 和语音识别 [12] [13] [14] [15] 。其他网络(如 DeepMind [16] 开发的 AlphaGo 模型)更加突出了神经网络在开发人工智能系统方面的潜力,吸引了广泛受众。随着神经网络性能的不断提高,某些行业对神经网络的开发和应用越来越显著。神经网络目前已经大量用于制造 [17] 、资产管理 [18] 和人机交互技术 [19] [20]。
不过,自从神经网络在工业中部署以来,也发生了许多事故。这些系统的故障导致模型出现不道德或不安全的行为,包括一些对边缘化群体表现出较大(性别和种族)偏见的模型 [21] [22] [23],或者导致生命损失的极端案例 [24] [25]。神经网络是一种统计黑盒模型,这意味着决策过程并非基于定义良好而直观的协议。相反,决策以一种无法解释的方式做出。因此,在社会和安全关键环境中使用这些系统会引起相当大的伦理关注。鉴于此,欧盟发布了一项新规定,明确用户拥有对人工智能系统所做决定的“解释权” [26] [27]。由于不清楚系统操作或设计的原则方法,其他领域的专家仍然对采用神经网络技术感到担忧 [28] [29] [30]。这激发了对可解释人工智能的研究尝试 [31]。
神经网络的在工程上的充分设计需要合理地理解其能力和局限性;尽量在部署前就找出其不足,而避免在悲剧发生以后再调查其缺陷。由于神经网络是一个统计黑匣子,当前理论尚无法解释和说明其决策过程。普通神经网络的频率学派观点为决策提供了缺乏解释和过度自信的估计,使其不适用于诸如医疗诊断、自动驾驶汽车等高风险领域。而贝叶斯统计提供了一种自然方式来推断预测中存在的不确定性,并可以深入解释做出决策的原因。
图 1 比较了执行同一回归任务的简单神经网络方法和贝叶斯方法,说明了度量不确定性的重要性。虽然两种方法在训练数据范围内都执行得很好,但贝叶斯方法提供了预测输出的完全分布,而神经网络方法仅提供了的点估计。贝叶斯方法输出分布的特点,允许开发更多可靠的模型,因为它可以识别预测中的不确定性。考虑到神经网络是人工智能系统最有前途的技术,“如何让人们信任神经网络的预测结果” 也就随之变得越加重要了。

图 1:在紫色区域没有训练数据的回归任务中,神经网络与传统概率方法的比较。(a) 使用具有 2 个隐藏层的神经网络的回归输出;(b) 使用高斯过程框架的回归,灰色条表示从均值开始 ±2 标准差范围。
贝叶斯观点使我们能够解决神经网络目前面临的许多挑战。为此,在神经网络的参数上放置一个分布,由此得到的神经网络被称为贝叶斯神经网络(Bayesian Neural Networks,BNN)。
贝叶斯神经网络的目标是拥有一个高容量模型,该模型能够展示贝叶斯分析的重要理论优势。最近已经有不少研究致力于将贝叶斯近似应用于实际神经网络中,而由于贝叶斯方法的计算/空间复杂度问题,这些研究面临的主要挑战集中在:如何在合理计算资源约束下,部署能够提供准确预测能力的模型。
本文目的是向读者提供容易理解的贝叶斯神经网络介绍,同时伴随对该领域一些开创性工作和实验的调研,以激发对当前方法能力和局限性的讨论。涉及贝叶斯神经网络的资料太多,无法一一列举,因此本文仅列出了其中具有里程碑性质的关键项。同样,许多成果的推导也被省略了,仅列出了最后结果,并附有对原始来源的引用。
同时,我们鼓励受相关研究启发的读者参考之前的一些调研报告:[32] 调研了贝叶斯神经网络的早期发展,[33] 讨论了对神经网络进行全面贝叶斯处理的细节,以及 [34] 调研了近似贝叶斯推断在现代网络结构中的应用。
本文应该适合所有统计领域的读者,但更感兴趣的读者可能是那些熟悉机器学习概念的人。尽管机器学习和贝叶斯概率方法都很重要 [2] [35],但实践中许多现代机器学习方法和贝叶斯统计研究之间存在分歧。希望这项调研能够有助于突出贝叶斯神经网络的现代研究与统计学之间的相似之处,强调概率观点对机器学习的重要性,并促进机器学习和统计学领域未来的合作。
2 神经网络
在讨论贝叶斯神经网络之前,简要介绍神经计算的基本原理,并定义本文使用的符号。本调研将重点介绍感兴趣的主要网络结构 – 多层感知机 ( MLP ) 网络。 MLP 是神经网络的基础,现代体系结构如卷积网络具有等价的 MLP 表示。图 2 显示了一个简单的 MLP ,它有一个适合于回归或分类的隐藏层。

图 2:二分类任务或回归任务的单隐层神经网络体系结构示例。图中节点表示对输入状态执行求和和激活等操作的神经元或状态。箭头指示神经元之间连接的权重参数。
对于图 2 中具有 维输入 的网络 ,其输出可以被建模为:
参数 表示与后续层神经元之间的加权连接,上标表示层号。公式 1 表示 个隐藏层神经元的输出 。公式 2 表示网络的第 个输出来自前一个隐藏层 个神经元输出的加权总和。该模型方案可扩展为包括许多隐藏层,每一层的输入是前一层的输出。通常在每一层中都会添加一个偏差值,不过为简单起见,在本文中省略了。
公式 1 为隐藏层中每个神经元(或节点)的状态,被表示为仿射变换形式,然后是非线性变换 ,这通常被称为激活函数。早期的感知机使用的激活函数是符号函数 ,但由于其导数等于零,现在已很少使用。更常用的激活函数包括:sigmoid、Tanh、RELU 和 Leaky-RELU [36] [37] 。图 3 展示了这些激活函数及其导数。当使用 sigmoid 函数时,式 1 等价于 Logistic 回归,这意味着网络输出变成了多个 Logistic 回归模型的和。
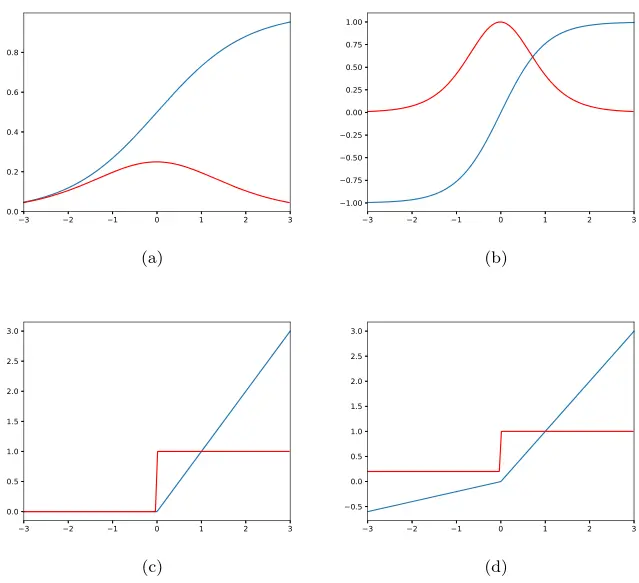
图 3:神经网络中常用的激活函数示例。激活函数的输出显示为蓝色,激活函数的导数显示为红色。函数有: (a) sigmoid;(b) Tanh;© Relu;(d) Leaky-relu。请注意 y 轴的比例变化。
对于回归模型,应用于输出单元的 函数通常为恒等函数,而对于二分类问题, 一般为 sigmoid 函数 ,对于多分类问题, 为 Softmax 函数。
通过堆叠数据集中的所有数据点(即将每个数据点对应的输入向量堆叠为矩阵 的一列),公式 1 和公式 2 可以使用矩阵表示法实现,其前向传播过程可以被表示为:
矩阵表示法更简洁,但此处选择求和表示法来描述网络还有其他考虑,主要是希望能够与本文后面讨论的核方法和统计理论的关系变得更加清晰。
在神经网络学习的频率主义框架内,最大似然估计或最大后验估计是通过最小化相对于权重的代价函数 来实现的。该代价函数的最小化可通过反向传播来执行,其基本步骤是:首先基于当前参数计算模型的输出损失,然后计算模型关于参数的偏导数,最后在给定学习率(作为超参数人工给出)下,更新每个参数的值,即:
公式 5 说明了反向传播法用于更新模型参数的迭代步骤,其中 (有时用 ) 表示学习率,下标表示训练过程中的第几次迭代。神经网络反向传播应用链式规则,逐层求出网络中参数的偏导数。这也意味着,当隐藏层数量增加时(即网络变深时),位于神经网络前部的层在反向传播过程中,比较容易出现梯度消失的问题,由此产生了对非线性类型激活函数的偏好,例如,由于 RELU 激活函数具有梯度大的特点,常被用于防止梯度消失现象( 图 3 )。
3 浅层贝叶斯神经网络及其推断
3.1 浅层贝叶斯网络
(1)为神经网络引入贝叶斯
频率主义框架将模型权重视为固定但未知的确切值,而非具有不确定性的随机变量,同时将数据视为变化量。这多少与直觉有些相悖,因为直觉上应该是根据手头已有的信息(数据),判断未知的模型权重(变量)是多少。
相对而言,贝叶斯统计建模是一种更符合直觉的方法,其视数据为可观测的已知信息,将未知的模型参数(即权重)视为随机变量。其基本逻辑是:将未知的模型参数视为随机变量,希望在可观测的训练数据支持下,掌握这些参数的概率分布。
在贝叶斯神经网络的学习过程中( 注:学习是机器学习领域的用语,而在贝叶斯统计语境下被称为推断( Inference ) ),未知的模型参数 可以在 先验信息 和 观测到的信息 基础上被推算出来。这是个逆概率问题,可用贝叶斯定理来阐述。
贝叶斯模型中模型参数 是隐变量,通常无法直接观测到其真实的分布,而贝叶斯定理使用 能够被观测到的概率 来表示 不可观测参数的分布,以观测数据为条件形成了模型参数的概率分布 ,即 后验分布(Posterior Distribution),简称后验(Posterior)。
在讨论学习过程前,让我们先观察和分析下模型参数和数据之间的联合分布 。根据联合概率公式,该分布可以由我们对模型参数的先验信念 和我们对 似然(Likelihood) 的选择 来定义:
在神经网络中,式 6 中的似然项 与神经网络中的最大似然法有着天然联系,由所假设的神经网络结构和所选择的损失函数定义。例如:对于损失函数为均方误差、且噪声方差已知的等方差的(单响应变量)回归问题,似然 是以神经网络的输出为均值的高斯分布:
在该回归模型中,一般假设 中的所有样本点是独立同分布的(i.i.d),从联合概率分布角度,这意味着可将似然分解成 个独立项的乘积:
在贝叶斯框架内,首先需要指定待求权重的先验分布,以包含人们关于权重理应如何分布的信念。由于神经网络具有黑箱性质,而且模型参数较多,为其指定有意义的先验非常具有挑战性。好在经验主义告诉我们,在许多频率主义的神经网络中,训练完成后得到的权重值通常较小,而且大致集中在 附近。因此可以考虑使用 小方差的零均值高斯分布 作为权重的先验,或使用 以零为中心的尖板分布(spike-slab) 作为权重的先验,既能满足最大熵先验要求,也能够促进模型的稀疏性。
注 1:贝叶斯神经网络中,将权重先验设置为零均值高斯先验较为常见。
注 2:尖板(Spike-slab)分布是两个高斯分布的叠加,其中一个峰值很高方差很小,而另外一个峰值很低方差很大。虽然是两个高斯分布的叠加,但尖板分布并不是高斯似然的共轭先验,无法得到后验的封闭解。
在指定先验和似然后,应用贝叶斯定理可计算得到模型权重的后验分布:
后验中的分母项为边缘似然(也称证据),其相对于模型权重而言是一个乘性常量,起到对后验进行归一化的作用,以确保后验是一个有效分布。因此也被称为 归一化因子。
注 3:边缘似然并非一定要计算出来,有时只需要知道后验的相对概率即可完成推断任务。特别是当问题规模较大时,计算边缘似然代价极高,此时常用的 MCMC 和变分等现代推断方法,都会巧妙地处理归一化因子问题,避免棘手的边缘似然计算问题。
(2)基于后验分布做预测
根据后验分布可以预测任何感兴趣的量。其基本的预测方法就是在后验分布上通过积分(或求和)求待预测对象的期望。由于求期望的过程通过积分消去了模型参数而仅剩下了待预测的量,因此也被称为边缘化过程。在有些文献当中,视 的每一个实例对应一个特定的模型,所以此积分过程也被称为贝叶斯模型平均( Bayesian Model Average,BMA )。
理论上,所有我们感兴趣的量(如:均值、方差、特殊的区间等)都可以写成上述期望的形式,或者说,所有预测量都是基于后验分布的某个期望值,不同预测量之间唯一的不同仅在于函数 的选择。通过公式可以很直观地看出,模型输出的预测值可被视为函数 经后验 加权后的均值 。
(3)基于后验分布做推断
除了利用后验分布做预测外,还可以基于后验分布 来推断出 中任一随机变量或随机变量子集的边缘分布或条件分布。此时,通常视后验分布为随机向量 的联合分布,而贝叶斯推断则是在此联合分布上,对 的某个子集计算边缘化概率或条件概率的过程。
注 4: 在已知多个随机变量的联合概率分布后,总有办法计算其中任一随机变量(或集合)的边缘概率和条件概率。
与频率主义框架中使用优化方法不同,贝叶斯推断这种边缘化的特点,让我们不仅能够了解模型的生成过程和生成结果,还能让我们获得参数的不确定性。例如:对于分类任务,可以将类别视为一个隐变量,并由类别与权重一起组成模型参数的随机变量集合,构建生成式模型。然后通过学习过程获得该随机变量集合的联合后验分布,最后通过边缘化方法对权重进行积分,从而计算得到类别的边缘概率分布,为贝叶斯决策提供依据。
上一节的案例中,假设了先验分布的参数 已知,但实践中较少出现此情况,通常需要将先验分布的参数(如:高斯分布的均值 和标准差 )视为随机变量进行更深一层的推断。贝叶斯框架支持此类推断,被称为分层贝叶斯模型(Hierarchical Bayesian Model)。其推断方式与模型参数(权重)的推断类似,即将先验分布的参数视为隐变量,并为之分配先验(即先验分布的参数的先验,被称为 超先验)。在完成整体的后验推断任务后,对这些超先验参数做边缘化处理,进而得到模型参数的后验分布。有关如何对贝叶斯神经网络执行此操作的更多说明,请参考 [33] [38]。
注 5:先验分布的某些参数未知时,可以假设该未知参数也是一个随机变量,且服从特定的先验分布,而其后验分布也同样需要从数据中学得,相关知识请参阅
分层贝叶斯模型。
(4) 后验分布的计算难题
对于许多模型,式 8 的后验计算仍然很困难,这主要由边缘似然(证据)的计算导致。对于非共轭模型或存在隐变量的非线性模型(如前馈神经网络),边缘似然几乎不可能有封闭解,而且高维模型的计算更为困难。但是,在贝叶斯框架内,后续很多预测和推断任务又都依赖于后验分布的计算。因此,大量研究集中在“采用什么方法来克服后验分布的计算难题”上。其中比较常见的思路是降低后验求解的要求,即不求后验分布的精确解,退而求其次,计算其近似解。这种后验的近似解法通常被称为 近似推断,而常用的方法包括 MCMC 方法 和 变分推断法 等。
注 6: 在贝叶斯推断方法中,由于问题规模的增大,传统的精确推断方法已经基本上不再使用了,但还是应当记住其中一些经典推断方法的名字,如:变量消除法、信念传播法等,参见 Dophne Koller 教授的 《概率图模型原理与技术》 一书。
3.2 早期的推断探索
根据本文和之前的调研报告 [39],基本可以认为贝叶斯神经网络的第一个实例是在 1989 年的 [40] 中发表的。该论文通过对神经网络损失函数的统计解释,强调了其统计学特性,并证明了均方误差最小化(MSE)等价于求高斯先验分布的最大似然估计(MLE)。重要的是:通过给神经网络权重指定先验,可用贝叶斯定理获得适当的后验。此工作虽然给出了对神经网络非常关键的贝叶斯见解,但并没有提供计算边缘似然的方法,也就意味着没有提出比较实用的推断方案。Denker 和 LeCun [41] 1991 年对该工作进行了扩展,提供了一种使用拉普拉斯分布进行近似推断的实用方法。
(1)早期讨论的主要问题
神经网络是一种通用的函数逼近器。已经有文献表明,当单隐层网络中的参数数量趋近于无穷大时,可以表示任意函数 [42] [43] [44] 。这意味着只要模型有足够参数,就可用单层神经网络来逼近任何训练数据。但与大家熟知的多项式回归模型类似,这种表达任意函数的能力增强了,意味着严重的过拟合问题。
在 1991 年 Gull 和 Skilling [45] 的工作基础上,MacKay 于 1992 年发表的文章 《Bayesian interpolation》 [46] 展示了如何使用贝叶斯框架处理模型设计和模型比较任务。该工作描述了两个层次的推断任务:一是用于拟合模型参数的推断、二是用于评估模型适用性的推断。
(2)用于参数推断的统计模型
第一类推断是贝叶斯规则用于模型参数更新的典型应用:
其中 是统计模型中的参数, 是训练数据, 是用于此类推断的第 个模型(在参数推断任务中,视模型为固定的)。上式可以描述为:
注意式 10 中的归一化常数也被称为模型 的边缘似然。对于大多数模型,后验的计算非常困难,只能采用近似的方法,该论文的一个主要贡献是提出了拉普拉斯近似推断方法。
(3)用于模型选择的统计推断模型
除了计算参数的后验,该论文还探讨了如何对模型 进行评估。其中模型的后验被设计为:
该公式可以解释为:
式 11 中的数据依赖项就是该模型的边缘似然 $P\left(\mathcal{D} \mid \mathcal{M}_{i}\right) $。之前我们对其做出 归一化常数 的解释是为了方便理解,而式 11 则要求必须计算边缘似然。这对于大多数贝叶斯神经网络来说,是非常困难甚至不可能的。
注 7:计算边缘似然的本质是求后验分布的积分。
注 8:此处总体理解是将贝叶斯定理用于了模型比较和选择,但必须以计算边缘似然为前提条件。模型比较和选择本身是贝叶斯统计框架中非常重要的一个部分,其潜在的研究动向是模型的自动评估和选择,按照 Zoubin 报告中的说法,这可行是自动机器学习的下一个风口。
(4)直接求解边缘似然的早期尝试
很多现代方法(如:MCMC 和变分法)通常都巧妙地规避了边缘似然的计算问题,但在该早期论文中,却实实在在提出了一种近似计算边缘似然的解决方案,虽然该方案基本已经无人使用。该论文假设边缘似然呈高斯分布,并提出了边缘似然的拉普拉斯近似:
上式可解释为对模型边缘似然的一种黎曼近似,通过两个因子来实现:
- 一是用于表示边缘似然高斯分布峰值(或众数)的
最佳似然拟合(Best Likelihood Fit)。 - 二是表示高斯分布峰值附近曲线特征宽度的
奥卡姆因子(Occam Factor)。
奥卡姆因子可理解为给定模型 的后验分布宽度 与先验范围 之比,计算公式为:
这意味着奥卡姆因子是参数空间中从先验到后验的变化率。图 4 展示了此概念:在先验一致的情况下,一个能够表示大范围数据的复杂模型( )将拥有更宽的边缘似然,因此具有更大的奥卡姆因子。而简单模型( )捕获复杂生成过程的能力较弱,但较小范围的数据能够更确定地建模,从而产生较小的奥卡姆因子。这导致模型复杂性的天然正规化:从模型复杂性方面,不必要的复杂模型通常会导致较宽的后验分布、较大的奥卡姆因子以及给定模型较低的边缘似然。
从先验角度考虑,一个弱信息先验(分布比较平坦, 较大)会导致较小的奥卡姆因子,而信息性先验(分布比较集中, 较小)会导致较大的奥卡姆因子。这直观地解释了贝叶斯设置中的正则化现象(即所谓 “贝叶斯方法内置奥卡姆剃刀”)。

图 4:边缘似然在模型评估中发挥的作用。简单模型 能以更大的强度预测较小范围的数据,而复杂模型 尽管预测强度较低,但能够预测更大范围的数据,改编自 [46] [47] 。
如前所述,使用该证据框架需要计算边缘似然,这是贝叶斯建模中最关键的挑战。考虑到近似计算边缘似然所需的大量成本,利用该证据框架比较许多不同的模型似乎不可行。尽管如此,它仍然是一个可以用来评估贝叶斯神经网络的解决方案。
对于大多数感兴趣的神经网络结构,目标函数是非凸的,具有许多局部极小值。每一个局部极小都可以看作是推断问题的一个可能解。MacKay 以此为动机,使用所有局部最小值对应的 证据函数(Evidence·Function) 来进行模型比较 [48] 。 这允许在不需要大量计算的情况下评估模型方案的复杂性。
3.3 变分推断方法
机器学习领域在优化问题上表现一直比较出色。其中许多最大似然模型(如支持向量机和线性高斯模型)的目标函数都是凸函数,但神经网络的目标函数往往是高度非凸的,具有许多局部极小值。针对该问题,机器学习社区开发出了类似反向传播 [3]的基于梯度的优化方法。因此,很快就有人联想到,是否能够将这些优化方法用到后验推断任务上?答案是肯定的, 变分推断(Variational Inference ) 就是优化方法在贝叶斯统计中的推广。
(1)什么是变分推断?
变分推断是一种近似推断方法,它将贝叶斯推断过程中所需的边缘概率计算视为一个优化问题 [49] [50] [51] 。变分推断首先为后验假设一个可参数化的分布族,然后通过对该分布族参数的优化,找到分布族中最接近真实后验分布的解。这种假设简化了计算,并提供了可操作性。
具体而言就是:
(1)假设后验分布 可以用某个分布 来近似表示,通常 被称为变分分布;
(2)假设该分布被 参数化(或索引),则所有可能的 构成了一个分布族;
(3)通过优化参数 来调整变分分布 ,使变分分布 与真是后验 之间的差异最小化;
(4)依据最优化方法,该最小化是一个渐进、迭代的过程,会逐步得到与真实后验 非常相似的 ;
(5)将所有基于真实后验 做的后续任务(如后验预测分布计算等),迁移到 上做近似实现。
按照上述原理,变分推断在第四步中需要一种变分分布与真实分布之间相似程度(或差异程度)的度量作为目标函数,而 KL 散度(也称相对熵) 恰恰是测量两个分布之间差异性的统计指标:
分布 到分布 的 KL 散度越小,说明两者之间越相似。 KL 散度 永远大于等于 , 当 时等号成立。
注 9:根据定义, KL 散度不符合交换律,即 。
变分推断将式 16 用作优化参数 的目标函数,从而将推断问题转变成了 的最优化求解问题。式 16 可进一步扩展为:
其中:
式中包含 所在的负值项,负号是为强调 它是一个与目标分布不同但等价的派生分布 ,并与参考文献表示方法保持一致。
现在将式 19 作为目标函数,并利用反向传播和梯度下降来优化。由于当模型固定时,式中第二项(对数边缘似然)为一常数,其关于 的导数为零。因此,上式关于参数 的导数中,只剩下包含变分参数的项 ,它通常被称为边缘似然的下界(ELBO) [49] [52] 。
根据式 19 :
(1) KL 散度 严格 ≥ 0 且仅当两个分布相等时才等于零;
(2)对数边缘似然 等于 KL 散度与边缘似然下界(ELBO)之和;
(3)换一种解释为:变分分布到真实分布的 KL 散度 是对数边缘似然与边缘似然下界 ELBO 之差。
(4)原优化问题为 “最小化 KL 散度,以求取最近似后验的变分分布” ,经 式 19 后,转换成了新问题 “最大化 ELBO ,以求取最近似后验的变分分布” 。在新问题中消去了(对数)边缘似然的计算项,只需让 ELBO 最大化即可,进而使效率得到较大提升。
图 5 可视化地说明了三者之间的关系。

图 5:最小化 到 的 KL 散度等效于最大化边缘似然的下界 ELBO。当变分分布到真实后验分布的 KL 散度被最小化时,边缘似然下界 收紧到对数边缘似然。因此,最小化 KL 散度等效于最大化边缘似然下界
ELBO(改编自 [53] )。
变分推断的要点:
(1)它是一种近似推断,需要构造变分分布的形式;
(2)采用最优化方法求解变分分布的参数,进而获得后验分布的近似形式;
(3)将优化目标从最小化变分分布到真实后验分布的 KL 散度,转换为最大化边缘似然下界ELBO,从而消去了边缘似然的高复杂度计算,提升了计算效率。
(2)如何构造变分分布?-- 从随机变量的独立假设开始
Hinton 和 Van Camp [54] 首次将变分推断应用于贝叶斯神经网络,试图解决神经网络中的过拟合问题。他们认为,通过使用神经网络模型权重的概率视角,权重包含的信息量会减少,神经网络会得到简化。该表述从信息论(特别是最小描述性长度,Minimum Descriptive Length) 角度出发,但导致了相当于变分推断的框架。
Hinton 等人的研究使用了 平均场变分贝叶斯 (MFVB) 方法。 平均场变分贝叶斯方法假设 变分分布对参数实施了因子分解 ,而 Hinton 等人则进一步假设 变分分布对参数实施了由若干独立的高斯分布构成的因子分解:
Hinton 等人的方法本质上是假设所有的权重是相互独立的随机变量,并且每个随机变量都服从高斯分布。而根据概率公式,变分分布可分解为各权重因子分布的乘积。而参数 则是所有 构成的集合。
其中 是神经网络中权重的数量。对于只有一个隐层的回归神经网络,该变分分布因采用高斯分布而存在封闭解。在贝叶斯统计方法中能够获得封闭解是一种非常理想的特性,可以极大地减少执行推断所需的时间。
(3)变分分布构造的优化 – 捕获随机变量间的相关性
Hinton 等人的工作存在几个问题,其中最突出的问题是假设变分分布被因子分解为若干个独立网络权重的高斯分布。众所周知,神经网络中的权重之间并不独立,而是存在强相关性。因子分解方法实际上是通过牺牲权重之间的相关性来简化了计算。Mackay 在对贝叶斯神经网络的早期调研中强调了该问题 [32],并提出通过对隐层的输入做预处理,可以获得更全面的近似后验分布。
Barber 和 Bishop [53] 再次强调了该问题,并扩展了 [54] 中的工作,通过使用 满秩高斯 的协方差模型来捕获权重间的相关性, 并构造了变分分布。对于使用 Sigmoid 激活函数的单隐层回归神经网络,该工作使用适当缩放的误差函数替换了 Sigmoid 激活函数,并提供了评估 ELBO 的解析表达式。
注:该方法依然需要采用数值方法来计算
ELBO封闭解中的某些项,并非完全的封闭解。
此方案的问题是参数数量过多。完全协方差模型的参数数量是神经网络权重数量的二次函数。为此,Barber 和 Bishop 对因子分解中经常使用的协方差提出了一种限制形式,
其中, 运算符根据长度为 的向量 创建对角线矩阵, 为模型中权重的数量。该形式与网络中隐藏单元的数量呈线性关系。
上述 Hinton、Bishop 等两项工作为将反向传播方法应用于解决贝叶斯问题做出了贡献。使这两个研究领域的特性可以合并,发挥各自优势。这些工作使我们具备了使用神经网络在概率意义上处理大数据集复杂回归任务的能力。
(4)变分推断的局限性
上述变分推断方法也存在局限性。Hinton 、 Van Camp 、 Barber 和 Bishop 的工作都集中在发展一种封闭形式的网络表示,对神经网络施加了许多限制。如前面所讨论的,[54] 假设后验分布被因子分解为独立的权重分布,无法捕获权重之间的相关性。 [53] 虽然捕获了协方差结构,但作者将其分析限制在使用误差函数来近似 Sigmoid 激活函数上,而该函数的梯度幅度较低容易造成梯度消失,因此无法向深层网络扩展。此外两种方法都存在一个非常关键的局限性,即假设模型为单隐层神经网络。
如前所述,神经网络可通过添加额外的隐藏单元来任意地逼近任何函数。但现代神经网络实验表明,通过增加网络中隐层的数量,可以用更少的隐藏单元来表示相同的复杂函数,并由此产生了“深度学习”,其中深度指的就是隐藏层的数量。当试图近似各层之间的完全协方差结构(即捕获不同权重之间的相关性)时,减少权重的数量变得尤其重要。例如,可以捕获层内隐藏单元之间的相关性,同时假设层间参数相互独立。此类假设可以显著减少相关系数的数量,进而减少复杂度。现代出现了很多拥有很深层数、数以亿计权重的神经网络,但目前大多只能提供频率学派擅长的点估计,因此开发超出单层的实用概率解释需求越来越迫切。
提醒:
由于此处重点在贝叶斯神经网络的变分推断问题,所以一些传统概率模型中的变分推断方法(如 ADVI 等最新的进展)没有体现出来,需要补充。
3.4 蒙特卡洛推断方法
到目前为止,我们的重点一直放在寻找后验分布的良好近似上,但后验的精确表示通常不是最终目标,我们实际感兴趣的主要任务是预测点和预测区间。我们希望在信心充分的情况下做出良好预测。之所以强调后验的良好近似,是因为预测点和区间等任务都必须根据后验分布 来计算期望值。该期望值在式 9 中已经给出,在此为方便再次给出:
这就是强调后验计算方法的原因,因为准确的预测和推断依赖于棘手的后验分布(或其近似)。
(1)什么是蒙特卡洛方法?
前述近似和优化方法(如变分推断或拉普拉斯近似)对后验形式有强假设和限制,而这些限制常导致不准确的预测。根据式 9 的解释,统计模型关心的预测和推断问题需要后验分布,但似乎并不一定需要知道后验分布的具体数学形式。由此催生了一种基于随机数的推断方法,即蒙特卡洛推断方法。
其思路是:只要具备逐点计算先验值和似然值的条件,就能从真实后验分布中获得样本。这在贝叶斯框架内肯定能够得到满足,因为似然值可由用户模型和似然假设得出,而先验值可由先验分布得出。进一步,如果能够依据后验的取值概率从后验分布的不同区域采集不同数量的样本(基本原则是:取值概率值高的区域多采点,取值概率低的区域少采点),就能够通过样本构成对式 9 期望值的近似,从而实现预测和推断任务。随着抽取样本的数量增加,期望值可以无限趋近于真值。
换句话说,蒙特卡洛方法会根据权重空间中每个区域的相对概率来确定从该区域抽取样本的次数。例如:如果后验分布中区域 A 的概率是区域 B 的两倍,那么从 A 抽取的样本将是从 B 抽得样本的两倍。因此,即使不能解析计算出整个后验,也可以使用蒙特卡洛方法从后验中获得样本。
注 6:后验公式中分母的边缘似然项仍然很难计算,这导致很难计算后验分布的绝对概率值。而蒙特卡洛方法仅依据相对概率来确定不同区域的采样数量,很巧妙地规避了边缘似然计算问题,这是其一大优势。但蒙特卡洛方法需要一定时间的预热才能够达到收敛状态,这对于那些时效性要求较高,尤其是超大规模的问题可能不是一个好的选择。
(2)马尔可夫链蒙特卡洛( MCMC )
蒙特卡洛方法为预测量期望值的计算提供了一条技术途径,但如果完全随机采样的话,采样效率会非常低。因此,“如何能用较小的采样次数获得有效的采样方案” 成为蒙特卡洛方法的关键问题。马尔可夫链蒙特卡洛( MCMC )方法根据此需求应运而生。
MCMC 方法 出发点很朴素:如果随机采样效率低的话,能否将采样过程限制在一个合理的路径上,使得在该路径上所有采样点构成的集合(或子集),符合按照取值概率确定采样数量的原则要求。这样的话,只需要在路径上采样,而不是在权重空间里随机采样,采样效率会得到大大提升。
那么是否能够构造出这样的一条合理路径呢?答案是肯定的,那就是马尔可夫链。
首先理解什么是马尔科夫链。可以将我们想要的路径建模为一条链,该链由一系列状态(在 MC 中,每个状态可理解为一个采样点)以及状态之间的转移概率构成。当这条链上的每个状态转移到其他状态的概率只与当前状态相关时,这条链就称为马尔科夫链。有了马尔科夫链,我们就可以任取一个初始点,然后依据状态转移概率随机游走。可以设想,如果当前状态到其他所有可能状态之间的转移概率都相同时,意味着下一个状态和当前状态无关,其效果等价于在整个权重空间中做随机采样。但如果能够找到一条马尔科夫链,其状态转移概率正比于目标分布(如贝叶斯分析中的后验分布)的取值概率,那么采样过程就变成了在该状态链上移动的过程。而且随着链长度的增长,采样结果将无限趋近于真实分布。
上述思想表明, MCMC 方法 可以从任意分布中采样,而不用关心分布的具体形态。进而将公式 9 的预测公式转换为如下的蒙特卡洛积分求和形式:
其中 表示来自后验分布的一个独立样本。
MCMC 不需要像变分推断那样对后验分布做出假设,而且当样本数量趋于无穷大时,MCMC 会收敛到真实后验。由于避免了假设限制,只要有足够时间和计算资源,就可以得到一个更接近真实预测值的解。当然,这对贝叶斯神经网络来说是一个重要挑战,因为多维复杂后验分布的 MCMC 收敛过程有可能需要很长时间。
注:根据 MCMC 的原理,决定采样有效性和效率的关键是状态转移策略的设计。事实上,根据转移策略的不同,已经发展出了很多种 MCMC 采样方法,比较常见的有 Gibbs 采样、 Metropolis-Hasting 采样、HMC 汉密尔顿采样、NUTS 不掉头采样等,感兴趣的读者请参阅附录 A。
(3)汉密尔顿蒙特卡洛(HMC)
传统 MCMC 方法的马尔科夫链中随机产生新值,因此存在随机游走的特点。而贝叶斯神经网络的后验存在复杂性和高维性特点,随机游走特性使推断很难在合理时间内完成。为避免随机游走,可在马尔科夫链迭代过程中加入了梯度信息,以加速迭代过程。在诸如 Gibbs 采样、M-H 采样等众多方法中, 汉密尔顿采样(HMC) 是一种利用了梯度信息的高效方法。 HMC 最初被用于统计物理 [58],但 Neal 强调 HMC 具备解决贝叶斯推断的潜力,并专门研究了其在贝叶斯神经网络和更广泛统计领域中的应用 [38] 。
鉴于 HMC 最初为物理动力学而提出,因此通过物理类比来建立统计学直觉比较容易理解。首先我们将感兴趣的权重 视为位置变量,则可以想象 个权重参数形成了一个 维的权重空间,其中每一个点都有相应的概率值。然后,引入一个辅助变量 来模拟当前位置的动量,该辅助变量没有统计学意义,只是为帮助系统动力学研究而引入的。通过位置和动量,可以表示系统的势能 和动能 。
根据动力学原理,系统总能量为动能和势能的总和:
当系统与外界没有能量交换时,其总能量将保持不变,即 为常数。此时的系统被称为 汉密尔顿(Hamiltonian)系统 ,并可用微分方程组表示 [59]:
其中 表示时间, 表示 和 中的个体元素。
通过 正则分布(canonical distribution) 可以将系统动力学中的物理解释与概率解释联系起来:
其中 是归一化常数, 是公式 23 中定义的总能量。从该联合分布可看出,位置变量和动量变量相互独立。
预测的最终目标是获得点或区间,在贝叶斯框架内,关键量是后验分布。为此,可将势能设置为:
在 HMC 中,动能可以从一系列函数中自由选择。但通常选取 的边缘分布为以原点为中心的对角高斯:
为对角矩阵,在物理解释中,被视为是变量的 “质量” 。
但需注意,虽然该动能函数最为常用,但不一定是最合适的。[55] 综述了其他高斯动能的选择和设计,并着重做出了几何解释。同时必须强调,选择合适的动能函数仍然是一个开放的研究课题,尤其是非高斯函数的情况。
汉密尔顿动力学使总能量保持不变,当以无限精度实现时,所提出的动力学是可逆的。可逆性是满足详细平衡条件的充分条件,这是确保目标分布(试图从其采样的后验分布)保持不变所必需的。在实际应用中,变量离散化会产生数值误差。最常用的离散化方法是 跳步(LeapFrog)法 。跳步法指定步长 以及在接受更新前可能使用的步数 。跳步法首先执行动量 的一半更新,接着是位置 的完全更新,然后是动量的剩余一半更新 [59]:
如果步长 的取值能够使该动力系统保持稳定,则可以证明跳步法保持了汉密尔顿的总能量。
对于使用式 22 近似的期望值,采样要求各样本 独立于其他样本,HMC 中可通过使用多个跳步 来实现这种独立性要求。基本做法是,在 个 步长之后,推荐新的采样点,从而降低样本之间的相关性。Metropolis 步骤可以用来确定新值是否被接受为马尔可夫链中的最新状态 [59] 。
注:Metropolis 步骤在 MCMC 中用于判定新推荐值是否被接受。
(4)在贝叶斯神经网络中应用 HMC
有学者 [38] 建议的贝叶斯神经网络,引入超先验 对先验的参数和似然的参数(方差或精度)进行建模。该超先验采用高斯分布,似然也建模为高斯分布。为保证条件共轭, 的先验采用伽玛分布。这允许使用 Gibbs 采样 来执行对超参数的推断。进而后验分布 的采样转换为联合后验 的采样,其采样过程实际上是在超参数的 Gibbs 采样和模型参数的汉密尔顿动力学之间交替进行。[38] 展示了 HMC 在简单贝叶斯神经网络模型中的优越性能,并与随机游走 MCMC 和 Langevin 方法进行了比较 。
4 深层贝叶斯神经网络
4.1 早期停滞
在 Neal、MacKay 和 Bishop 于 90 年代提出早期工作之后,对贝叶斯神经网络的研究沉寂了一段时间,其实整个神经网络领域的研究几乎都停滞了,主要是因为训练神经网络的计算需求太高。神经网络能够以任意精度捕获任何函数,但准确捕获复杂函数需要具有许多参数的大型网络。即使从传统频率主义观点来看,训练如此庞大的网络很困难,而研究信息量更大的贝叶斯神经网络,计算需求会更高。
不过在证明了 GPU 可以加速训练大型网络后,人们对神经网络的研究热情又重新燃起。GPU 实现了在反向传播期间执行大规模线性代数并行,这种加速计算允许训练更深层次的网络。随着 GPU 在优化复杂网络方面的成熟以及此类模型取得的巨大成功,人们也对贝叶斯神经网络重新产生了兴趣。
4.2 变分推断方法与梯度估计
现代贝叶斯神经网络研究主要集中在变分推断方法上,因为这些问题可以使用反向传播方法来优化。考虑到大多成功的现代神经网络均为深层次网络,文献 [54] [53] 中的原始变分推断方法(侧重于利用单个隐层的回归神经网络的解析近似)变得不适用。现代神经网络呈现出不同的体系结构,具有不同维度、隐藏层、激活函数和应用。需要在概率意义上重新审视神经网络的更一般的方法。
考虑到现代神经网络的大规模性,稳健的推断能力通常需要建立在大数据集上。而对于大数据集,做全数据集的对数似然评估变得不可行。为解决该问题,产生了采用随机梯度下降(SGD)和小批量数据来近似似然的方法。这时变分的目标函数就变成:
其中小批量数据 , 为批量数,每个 的批大小均为 。这为训练期间利用大数据集提供了有效方法。每传入一个 之后,应用反向传播来更新一次模型参数。不过这种似然的子采样会在推断过程中引入随机噪声,因此得名随机梯度下降(SGD) 。该随机噪声在所有单独子集的评估过程中会被平均掉 [61] 。SGD 是利用变分推断方法训练神经网络和贝叶斯神经网络的最常用方法。
Graves 在 2011 年发表了一篇关于贝叶斯神经网络研究复兴的关键论文《Practical variational inference for neural networks》[62]。这项工作提出了一种以因子分解的高斯分布作为后验近似的 MFVB 处理方法。其关键贡献是梯度的计算。变分推断目标(即边缘似然下界 ELBO 最大化)可被视为两个期望的总和:
这两个期望是优化模型参数所需要的,因此需要计算期望的梯度。该论文显示了如何使用 [63] 提出的高斯梯度特性计算参数的梯度,并对参数进行更新:
蒙特卡洛积分可以应用于公式 34 和 35 以估计均值和方差的梯度。该框架允许对 ELBO 进行优化,以推广到任意对数损失参数模型。
虽然解决了将变分推断应用于具有更多隐层的复杂贝叶斯神经网络问题,但由于估计梯度时采用的蒙特卡洛方法具有巨大的方差,在实际使用中仍然显示出性能上的不足 [64] ,因此,开发减少蒙特卡洛估计方差的参数梯度估计方法成为变分推断中一个重要的研究课题 [65] 。 其中: 打分函数估计器(Score Function Estimators) 和 路径导数估计器(Pathwise Derivative Estimator) 是梯度的两种最常见的近似估计方法。
打分函数估计器依赖于对对数导数特性的使用:
利用该性质,可形成对期望导数的蒙特卡洛估计,这在变分推断中经常使用:
\begin{align}
\nabla_{\theta} \mathbb{E}{q}[f(\omega)] &=\int f(\omega) \nabla{\theta} q_{\theta}(\omega) \partial \omega \
&=\int f(\omega) q_{\theta}(\omega) \nabla_{\theta} \log \left(q_{\theta}(\omega)\right) \partial \omega \
& \approx \frac{1}{L} \sum_{i=1}^{L} f\left(\omega_{i}\right) \nabla_{\theta} \log \left(q_{\theta}\left(\omega_{i}\right)\right)
\end{align}
打分函数梯度估计的一个常见问题是表现出相当大的方差 [65]。减少蒙特卡洛估计方差的最常见方法之一是引入控制变量 [66]。
变分推断文献中常用的第二种梯度估计器是路径导数估计器 。这项工作建立在 重参数化技巧 [67] [68] [69] 基础上,其中随机变量被表示为确定性的和可微的表达式。例如,对于参数为 的高斯分布:
其中 和 表示 Hadamard 积。使用这种方法可以对期望的蒙特卡洛估计进行有效采样。正如文 [68] 所示,当 时,有 , 因此,可以证明:
由于式 39 相对于 θ 是可微的,因此可使用梯度下降法来优化该期望的近似。这是变分推断中的一个重要属性,因为变分推断的目标中包含通常难以处理的对数似然期望值。重参数化技巧 是路径梯度估计器的基础。路径估计因其比打分函数估计更低的方差而更受欢迎 [68] [65] 。
4.3 MC Dropout 近似推断方法
对神经网络进行贝叶斯处理的一个关键好处是能够从模型及其预测中提取不确定性。这是最近在神经网络背景下引起高度兴趣的研究课题。
新的研究通过将现有正则化技术(如 Dropout [70] )与近似推断联系起来,为神经网络的不确定性估计带来了有前途的发展。丢弃(Dropout)是一种随机正则化技术,它是为解决点估计网络中常见的过拟合问题而提出的。在训练过程中,Dropout 引入了一个独立的随机变量,该变量是伯努利分布的,并将每个单独的权重元素乘以该分布中的样本。例如,实现 Dropout 的简单 MLP 是这样的形式,
由式 40 可以看出,Dropout 的应用 以与重参数化技巧类似的方式 将随机性引入网络参数。一个关键区别是:在 Dropout 情况下,随机性被引入到输入空间,而不是贝叶斯推断所需的参数空间。Yarin Gal [39] 证明了这种相似性,并演示了如何将 Dropout 引入的噪声有效地传递到网络权重:
其中 是从伯努利分布采样的向量, 运算符从向量创建平方对角矩阵。如此可以看出,一个 Dropout 变量在权重矩阵的每一行之间被共享,从而允许维持行间的某些相关性。通过查看权重参数的随机分量,该公式适用于使用变分框架的近似推断。在这项工作中,近似后验是伯努利分布与权重乘积的形式。
应用重参数化技巧获得相对于网络参数的偏导数,然后形成 ELBO 并执行反向传播以最大化下界。蒙特卡洛积分被用来逼近解析上难以处理的对数似然。通过用两个小方差高斯分布的混合模型来近似伯努利后验,得到 ELBO 中近似后验与先验分布之间的 KL 散度。
在上述工作同时,Kingma 等人 [71] 也发现了 Dropout 和其在变分框架中的应用潜力。与 Dropout 引入的典型伯努利分布随机变量相比,[71] 将注意力集中在引入高斯随机变量 [72] 。文中表明在选择与参数无关的适当先验情况下,使用 Dropout 的神经网络可被视为近似推断。
Kingma 等人还希望使用改进的局部重参数化来降低随机梯度中的方差。这不是在应用仿射变换之前从权重分布进行采样,而是在之后执行采样。例如,考虑 MFVB 的情况,其中假设每个权重是独立的高斯 $$W_{ij}∼N(\mu {ij},σ^2{ij})$$ 。在仿射变换 $$\phi_j=\sum_{i=1}^{N_1}(x_iρ_i)w_{ij}$$ 之后, 的条件后验分布也将是因子分解的高斯形式:
相对于权重 本身的分布,从 的分布中采样更有利,因为这使得梯度估计器的方差与训练期间使用的小批次数量呈线性关系。
上述工作对于解决机器学习研究中缺乏严谨性的问题很重要。例如,最初的 Dropout 论文 [70] 缺乏任何重要的理论基础。相反,该方法引用了有性繁殖理论[73]作为方法动机,并在很大程度上依赖于所给出的实证结果。这些结果在许多高影响力的研究项目中得到了进一步的证明,但这些项目仅仅将其作为一种正规化方法来使用。[39] 和 [71] 中的工作表明,该方法有理论上的合理解释。在试图减少网络过拟合影响时,频率主义方法论依赖于弱合理性的成功经验,而贝叶斯分析提供了丰富的理论体系,导致对神经网络强大近似能力的有意义理解。
4.4 概率反向传播方法
虽然解决了将变分推断应用于具有更多隐层的复杂贝叶斯神经网络问题,但实际实现还是显示出性能不足,这归因于梯度计算的蒙特卡洛近似带来的巨大方差。Hernandez 等人 [64] 承认了这一局限性,并提出了一种新的贝叶斯神经网络实用推断方法,名为概率反向传播 (PBP)。PBP 偏离了典型的变分推断方法,取而代之的是采用 假设密度滤波(Assumed Density Filtering, ADF)方法 [74]。在该方法中,通过应用贝叶斯规则以迭代方式更新后验概率:
与以预测误差为目标函数的传统网络训练不同,PBP 使用前向传播来计算目标的对数边缘概率,并更新网络参数的后验分布。在 [75] 中定义的矩匹配方法使用了反向传播的变种来更新后验,同时在近似分布和变分分布之间保持等效均值和方差:
在多个小数据集上的实验结果表明,与简单回归问题的 HMC 方法相比,该方法在预测精度和不确定性估计方面具有合理的性能 [64] 。这种方法的关键问题是在线训练带来的计算瓶颈。该方法可能适用于某些应用,或者适用于在现有贝叶斯神经网络可用时用额外的附加数据更新现有贝叶斯神经网络,但是对于大数据集推断,该方法在计算性能上令人望而却步。
4.5 反向传播贝叶斯方法
Blundell 等人提出了一种很有前途的贝叶斯神经网络近似推断方法,名为 “Bayes by Backprop” [76]。该方法利用重参数化技巧来展示如何找到期望导数的无偏估计。对于可重参数化为确定性且可微函数 的随机变量 ,任意函数 的期望的导数可表示为:
在 Bayes by Backprop 算法中,函数 被设为:
这个 可被视为式 17 中执行的期望的自变量,它是下界的一部分。组合公式 51 和 52 :
是 ELBO 的相反数,意味着 Bayes By Backprop 旨在最小化近似后验和真实后验之间的 KL 散度,可以使用蒙特卡洛积分来近似公式 53 中的代价:
其中 是来自 的 第 个样本。通过公式 54 中的近似,可以使用公式 51 所示结果来找到无偏梯度。
对于 Bayes by Backprop 算法,假设一个完全因子分解的高斯后验,使得 ,其中 用于确保标准偏差参数为正。由此,网络中的权重分布 被重参数化为:
在该贝叶斯神经网络中,可训练参数为 和 。由于使用了全因子分解分布,根据公式 20,近似后验的对数可表示为:
算法 1 描述了完整的 Bayes by Backprop 算法。

5 BNN 的高斯过程特性与深度高斯过程
5.1 BNN 的高斯过程特性
Neal [38] 还给出了推导和实验结果,以说明对于只有一个隐层的网络,当隐藏单元的数量接近无穷大时,会出现网络输出的高斯过程先验,论文将高斯先验置于参数之上。图 6 说明了该结果。

图 6:当在参数上放置高斯先验时,随着网络规模的增加,在网络输出上导致高斯过程先验。实验复制自 [38]。图中的每个点对应于一个神经网络的输出(参数从其先验分布中采样),x 轴为 f(0.2),y 轴为 f(−0.4)。对于每个网络,隐藏单元的数量是图(a)对应着 1 个单元,图(b)对应着 3 个单元,图(c)对应着 10 个单元,图(d)对应着 100 个单元。
从公式 1 和公式 2 可以看出神经网络和高斯过程之间的这种重要联系:
具有单个隐藏层的神经网络是应用于输入数据的 N 个参数化基函数的总和。如果方程 1 中每个基函数的参数是随机变量,则方程 2 成为随机变量的和。在中心极限定理下,随着隐层数 ,输出变为高斯。由于输出被描述为无限个基函数的和,因此可以将输出视为高斯过程。
根据这一结果的完整推导和图 6 中所示的图,[38] 显示了如何在有限的计算资源下实现近似高斯性质,以及如何保持该和的大小。Williams 随后展示了针对不同激活函数如何分析协方差函数的形式 [77]。高斯过程与具有单一隐层的无限宽网络之间的关系最近扩展到了深层神经网络 [78]。
5.2 深度高斯过程
上述联系促进了在贝叶斯神经网络中的许多研究工作。高斯过程提供了许多我们希望获得的特性,例如可靠的不确定性估计、可解释性和鲁棒性。但高斯过程在提供这些好处同时,代价却是随着数据集大小的增加,预测性能和所需计算资源呈指数级增长。高斯过程和贝叶斯神经网络之间的这种联系推动了两个建模方案的合并:既保持神经网络中看到的预测性能和灵活性,又融入了高斯过程带来的稳健性和概率属性。这导致了深度高斯过程的发展。
深度高斯过程是单个高斯过程的级联,前一个高斯过程的输出用作新高斯过程的输入 [79] [80],与神经网络非常相似。这种高斯过程的堆叠允许从高斯过程的组合中学习非高斯密度。高斯过程的一个关键挑战是适应大数据集,因为单个高斯过程的格拉姆矩阵(Gram Matrix)的维度与数据点的数量是平方关系。由于级联中的每个单独高斯过程都会产生一个独立的格拉姆矩阵(Gram Matrix),因此该问题会被深度高斯过程放大。此外,由于产生的是非线性函数,深度高斯过程的边缘似然在分析上是难以处理的。在 [82] 工作的基础上,Damianou 和 Lawrence [79] 使用变分推断方法来创建易于处理的近似,并将计算复杂度降低到稀疏高斯过程中常见的计算复杂度 [83]。
Neil Lawrence 提供了对深度高斯过程的完整介绍、代码和讲座 [81]。
深度高斯过程展示了高斯过程如何从神经网络中受益。Gal 和 Ghahramani [84] [85] [86] 阐明了如何用贝叶斯神经网络来近似深度高斯过程。这是一个可预期的结果;鉴于 Neal [38] 发现具有单个隐藏层的无限宽网络收敛到一个高斯过程,通过连接多个无限宽的层,整个网络可以收敛到一个深度高斯过程。
当每层中隐藏单元的数量接近∞时,贝叶斯神经网络近似成为深度高斯过程。
5.3 高斯过程的协方差函数与激活函数的选择
除了对深度高斯过程的分析外,[84] [85] [86] 在 [77] 工作的基础上分析了贝叶斯神经网络中使用的现代非线性激活函数与高斯过程的协方差函数之间的关系。该工作可能允许在神经网络中更原则性地选择激活功能,类似于高斯过程的激活功能。哪些激活函数会产生一个稳定的过程?过程的预期长度尺度是多少?这些问题或许可以用高斯过程现有的丰富理论来解决。
高斯过程属性不限于 多层感知机贝叶斯神经网络 。最近的研究已经表明,在卷积贝叶斯神经网络中产生高斯过程性质的某些关系和条件 [87] [88]。这一结果是可预期的,因为卷积神经网络可以被视为具有某种权重结构的多层感知机。该论文工作说明实施权重结构如何导致形成高斯过程。Van der Wilk [89] 等人提出了卷积高斯过程,它实现了一种类似于在卷积神经网络中看到的面片操作,来定义函数上的高斯过程先验。该方法的实现需要使用近似方法,因为对于大数据集的评估成本高得令人望而却步,甚至在单个面片上的评估都是令人望而却步的。生成的点由变分推断框架形成(以减少需要评估的数据点数量和面片数量)。
6 当前贝叶斯神经网络的局限性
6.1 存在的主要问题
虽然人们已付出了很大努力来开发在神经网络中执行推断的贝叶斯方法,但这些方法存在很大局限性,文献中还存在许多空白。其中一个关键限制是严重依赖变分推断方法。在变分推断框架内,最常用的方法是 MFVB 方法 。MFVB 通过强制参数之间的独立性假设,提供了一种表示近似后验分布的方法。该假设允许使用因子分解来构建近似后验分布。这种独立性假设大大降低了近似推断的计算复杂度,但损失了概率精度。
变分推断方法还存在一个问题,即结果模型过于自信,其预测均值可能是准确的,但方差被大大低估了 [90] [91] [92] [51] [93]。文献 [2] 的第 10.1.2 节和文献 [35] 的 第 21.2 节 描述了这一现象,两个章节都附有举例和直观的数字来说明这一性质。这种问题存在于当前贝叶斯神经网络的大部分研究中 [39]。
在文献 [49] 中,作者提出使用热重启来获得多个点估计网络,而不是仅拟合一个参数分布。此方法被称为深度集成(见图 13),在传统机器学习领域中曾被用于模型平均,但 [49] 的主要贡献是表明:该方法能够实现非常好的校准误差估计。虽然 [49] 的作者声称其方法是非贝叶斯的,但已经证明其方法可以从贝叶斯角度来理解 [68] [93]。特别是,如果使用了正则化(即声明了先验),不同的点估计应该分别对应于贝叶斯后验中的某个峰值。为了成为真正的贝叶斯方法,这些峰值处的相对后验概率应该在模型平均过程中得到考虑。这可以被解释为用参数化为多个狄拉克增量的变分分布来逼近后验(见 式 55)。这从概念上也可以被视为某种变分推断,即便其变分分布无法被用于计算对传统优化方法而言意义重大的 ELBO:
有理由认为,当前变分推断方法的局限性可能受到所选择变分分布的影响,特别是 MFVB 方法 经常使用的独立高斯分布。如果使用更全面的近似分布,会不会生成与已知或未知数据更加一致的预测呢?
对于一般的变分推断方法, [98] [49] 提出了混合模型近似,但该方法的 个混合分量的引入增加了 倍的参数数量。[99] 在贝叶斯神经网络中引入了 矩阵-正态近似后验(Matrix-Normal approximate posteriors) ,这与满秩高斯相比减少了模型中变分参数的数量,但没有对协方差结构建模。MC Dropout 在折中低熵近似后验的情况下,能够在权重矩阵行内保持一定的相关性信息。
6.2 标准化流推断方法
最近提出了一种新的变分推断方法,通过使用 标准化流(Normalising Flows)来捕获更复杂的后验分布 [100] [101]。在标准化流中,初始分布通过一系列可逆函数的“流动”,产生更复杂的分布。这可以在变分推断框架内通过摊销推断实现 [102]。摊销推断引入了一个推断网络,将输入数据映射到生成式模型的变分参数,然后利用这些参数从生成式过程的后验中采样。标准化流的使用已扩展到贝叶斯神经网络 [103]。这种方法出现了与计算复杂性相关的问题,以及摊销推断的局限性。
标准化流需要计算雅可比行列式,这对于某些模型来说可能计算过于昂贵。通过将标准化流限制为包含数值稳定的可逆运算,可以降低计算复杂度 [102] [104]。这些限制已被证明严重限制了推断过程的灵活性,以及由此产生的后验近似的复杂性 [105]。
6.3 改进目标函数
如前所述,在变分推断框架中,选择近似分布,然后最大化 ELBO。这个 ELBO 源于在真实后验和近似后验之间应用 KL 散度,但这回避了一个问题,为什么要使用 KL 散度呢?KL 散度是评估两个分布间相似性的一个众所周知的度量,它满足散度的所有关键性质(即 KL 散度为正,并且仅当两个分布相等时为零)。散度可以让我们知道近似分布是否接近真实分布,但无法知道离真实分布有多近。为什么不用定义明确的距离来代替散度呢?
贝叶斯推断的目标是在先验知识和观测数据的分布下识别最适合模型的参数。变分推断框架将推断视为优化问题,优化参数以最小化近似分布和真实分布之间的 KL 散度(最大化 ELBO)。通过将边缘似然从目标函数中分离出来,能够计算相对于易处理量的导数。由于边际似然与参数无关,当求导数时,该分量消失。这就是使用KL 散度的关键原因,因为它允许我们从目标函数中分离出难以处理的量,然后在使用梯度信息执行优化时,目标函数将被评估为零。
KL 散度已被证明是 α-散度族 的一部分。α散度表示为:
正向 KL 散度 可以在公式 57 中 趋近于 −1 时生成,而反向 KL 散度 则在 趋近于 +1 时生成。虽然在变分推断中使用正向 KL 散度通常会导致低估方差,但是使用反向 KL 散度通常会高估方差 [2]。类似地,当 时,式 57 中的 海灵格距离(Hellinger distance) 将升高:
这是一个有效距离,因为它满足三角形不等式并且是对称的。与两个 KL 散度相比,海灵格距离的最小化在方差估计上提供了合理的折衷 [107]。虽然这些措施可能提供理想的质量,但它们不适合在变分推断中直接使用,因为难以处理的边缘似然不能与其他项分开。虽然这些度量不能立即使用,但它说明了客观度量的变化如何导致不同的近似。通过对目标函数使用不同的度量,可以找到更准确的后验期望。
6.4 改进 MCMC 的可能性
绝大多数现代方法都围绕着变分推断方法展开,这在很大程度上归功于 SGD 。现存许多复杂的工具来简化和加速自动微分和反向传播的实现 [108] [109] [110] [111] [112] [113] [114]。变分推断的另一个好处是它接受似然的子采样。子采样减少了对大数据集进行训练所需的计算开销。这是传统 MCMC 方法在贝叶斯神经网络领域失宠的关键原因。
MCMC 具有丰富的理论发展、渐近保证和实用的收敛诊断能力,是进行贝叶斯推断的黄金标准。传统 MCMC 方法 需要从完全联合似然(即所有样本)中采样来执行更新,要求在提出任何新点前看到所有训练数据。
目前,子采样 MCMC(Sub-sampling MCMC) 或 随机梯度 MCMC(SG-MCMC) 方法已在 [61] [115] [116] 中提出,并应用于贝叶斯神经网络 [117]。已有研究表明,MCMC 内的朴素子采样将使随机更新的轨迹偏离后验 [118]。这种偏离消除了传统 MCMC 方法在理论上的优势,使其不如计算开销更低的变分推断方法。为使采样方法变得可行,需要发展确保收敛于后验分布的新子采样方法。
7 现代贝叶斯神经网络的比较
7.1 两种现代贝叶斯推断方法
从文献调研情况来看,当前贝叶斯神经网络中两种最重要的近似推断方法是 反向传播贝叶斯(Bayes by Backprop)[76] 和 MC Dropout [85]。这些方法被认为是贝叶斯神经网络中最有前途、影响最大的近似推断方法。两种推断方法都足够灵活,并且可以使用 SGD,从而使其部署到大型数据集成为可能。鉴于这些方法的突出之处,有必要对其进行比较,看看它们的表现如何。
为比较这些方法,进行了一系列简单的同方差回归任务。在这些回归模型中,似然为高斯分布。有了这个,可以写出未标准化的后验:
其中 是贝叶斯神经网络表示的函数。在 Bayes by Backprop 和 MC Dropout
两个模型中,均采用高斯混合模型对 spike-slab 先验建模。然后用各自方法,求出模型的近似后验 。
对于 Bayes by Backprop,近似后验分布是完全分解的高斯分布,而对于 MC Dropout,近似后验分布是缩放了的伯努利分布。利用模型的近似后验,可以使用蒙特卡洛积分做出点或区间预测。前两个点可以近似为 [39]:
其中星号上标表示来自测试集中的新输入/输出样本 。
用于评估这些模型的数据集是来自高影响力论文的 simple toy 数据集,其中提供了类似的实验作为经验证据 [76] [119]。然后将两种贝叶斯神经网络方法与高斯过程模型进行比较。图 7 显示了这些结果。

图 7:贝叶斯神经网络与高斯过程在三个玩具数据集的回归任务上的比较。
顶行:由 Bayes by Backprop [76] 训练的贝叶斯神经网络;中间行:用 MC Dropout [39] 训练的贝叶斯神经网络,底部:使用 GPflow 软件包 基于 Mattern52 核 拟合的高斯过程模型 [120]。 两个贝叶斯神经网络均包含两个 RELU 激活的隐藏层。训练数据用深灰色散点表示,平均值用紫色表示,真实测试函数用蓝色表示,阴影区域表示 和 。
对图 7 中所示回归结果的分析显示,在预测中的偏差和方差方面表现不同:
- 用
Bayes by Backprop和分解后的高斯近似后验数据训练的模型显示出合理的训练数据分布预测结果。尽管与高斯过程相比,训练数据区域外的方差被显著低估了。 - 具有缩放伯努利近似后验的
MC Dropout对于训练数据区域外的方差更大了,尽管在训练数据的区域内保持了不必要的高方差。 - 对这些模型的超参数进行了微调。通过更好地选择超参数,可以获得更好的结果,特别是对于
MC Dropout。或者,可以使用更完整的贝叶斯方法,其中将超参数视为隐变量,并对这些变量执行边缘化。
值得注意的是,上述方法在计算和实际应用中都遇到了困难。MC Dropout 方法非常灵活,因为它对先验分布的选择不那么敏感。它还设法用更少的样本和训练迭代来适应更复杂的分布。最重要的是显著节省了计算资源。考虑到使用 MC Dropout 训练一个模型通常与训练多个现有的深层网络相同,因此推断与传统网络同时进行。MC Dropout 也没有增加网络的参数数量,而 Bayes by Backprop 需要两倍的参数。在实际情况下应考虑这些因素。如果被建模的数据是平滑的,有足够的数量,并且允许额外的时间进行推断,使用 Bayes by Backprop 可能更可取。对于功能复杂、数据稀疏、时间要求较严格的大型网络,MC Dropout 可能更合适。
7.2 卷积贝叶斯神经网络
虽然 MLP 是神经网络的基础,但最突出的神经网络架构是卷积神经网络。这些网络在图像分类任务方面表现出色,其预测性能远远超过先前基于核或特征工程的方法。卷积神经网络不同于典型的 MLP ,它使用类似于卷积的算子代替 MLP 的内积,单个卷积层的输出可以表示为:
其中 是非线性激活, 表示类卷积运算。输入 和权重矩阵 不再局限于向量或矩阵,可以是多维数组。CNN 可以被写成等效的 MLP 模型,从而允许利用反向传播进行训练 [122]。
在现有研究方法基础上,发展出一种新型贝叶斯卷积神经网络 (BCNN)。该网络将 Bayes by Backprop 方法扩展到适合于图像分类的卷积神经网络模型[76] 。卷积层中的每个权重被假定为独立的,从而允许对每个单独的参数进行因子分解。
通过实验研究了 BCNN 的预测性能及其不确定性估计的质量。这些网络被配置用于 MNIST 手写数字数据集的分类 [123]。
由于该任务是分类任务,因此 BCNN 的似然被设置为 SoftMax 函数,
未标准化的后验可以表示为:
利用 Bayes by Backprop求出近似后验。可使用式 60 找到测试样本的预测平均值,并且使用 蒙特卡洛积分来近似可信区间 [35]。
有学者 [123] 在均为 LeNet 架构的普通 CNN 网络与 BCNN 网络间做了比较 。使用 BCNN 的平均输出进行分类,并使用可信区间来评估模型的不确定性。在 MNIST 数据集中的 10,000 张测试图像上,两个网络的总体预测显示出接近的性能。BCNN 的测试预测准确率为 98.99%,而普通网络的预测准确率为 99.92%,略有提高。虽然竞争性预测性能是必不可少的,但 BCNN 的主要好处是提供了有关预测不确定性的有价值信息。难以分类的数字示例显示在附录中,并附有平均预测值和每类 95% 可信区间的曲线图。从这些例子中,可以看到这些具有挑战性的图像的大量预测不确定性,这些不确定性可以用来在实际场景中做出更明智的决策。
这种不确定性信息对于许多感兴趣的场景来说是无价的。随着统计模型越来越多地用于包含人类交互的复杂任务,这些系统中的许多系统基于其感知的世界模型做出负责任的决策至关重要。例如,神经网络在自动驾驶汽车的开发中被大量使用。由于场景的高度可变性和与人类互动相关的复杂性,自动驾驶汽车的开发是一项令人难以置信的具有挑战性的壮举。目前的技术不足以安全地实现这项任务,正如前面讨论的那样,这些技术的使用已导致多人死亡 [24] [25]。在这样一个高度复杂的系统中对所有变量进行建模是不可能的。这伴随着不完美的模型和对近似推断的依赖,重要的是模型可以传达与决策相关的任何不确定性。至关重要的是,我们必须承认,所有模型从本质上都是错误的。这就是为什么概率模型在此场景中更受青睐的原因:有一个基本理论来处理数据中的异质性,并解释模型中未包含变量引起的不确定性。至关重要的是,用于此类复杂场景的模型在用于此类复杂和高风险场景时能够传达其不确定性。
8 结论
本调研报告阐明了典型神经网络和特殊模型设计中存在的过度自信预测问题,而贝叶斯分析被证明可用来解决这些问题。尽管对贝叶斯神经网络来说,精确推断仍然是分析和计算上的难题,但实践表明,可以依靠近似推断方法获得较为精确的近似后验。
贝叶斯神经网络中的许多近似推断方法都围绕 MFVB 方法展开。这为优化变分参数提供了一个易于处理的下限。这些方法在易用性、预测均值的准确性、可接受的参数数目等方面具有吸引力。文献调研和实验结果表明,在完全因子分解的 MFVB 方法中所做的假设会导致过度自信的预测。同时文献也表明,这些 MFVB 方法可以推广到更复杂的模型,如卷积神经网络。对于图像分类任务,贝叶斯卷积神经网络的预测性能与基于点估计的卷积神经网络相当(稍弱),但贝叶斯卷积神经网络能够为预测提供可信区间,而这为难以分类的数据点提供了高度信息性和直观性的不确定性度量。
本文突出了贝叶斯分析解决机器学习社区中常见挑战的能力。这些结果还突显了当前用于贝叶斯神经网络的近似推断方法的不足,甚至可能提供不准确的方差信息。不仅要确定网络是如何运行的,而且要确定现代大型网络如何才能实现精确推断,这有待进一步研究。将 MCMC 等推断方法扩展到大数据集上允许更有原则性的推断。MCMC 提供了评估收敛和推断质量的诊断方法。对变分推断的类似诊断允许研究人员和实践者评估他们假设后验的质量,并告知改进该假设的方法。实现这些目标将使我们能够获得更精确的后验近似。由此,我们将能够充分确定模型知道什么,也可以确定模型不知道什么。
参考文献
- [1] F. Rosenblatt, “The perceptron: A probabilistic model for information storage and organization in the brain.” Psychological Review, vol. 65, no. 6, pp. 386 – 408, 1958.
- [2] C. Bishop, Pattern recognition and machine learning. New York: Springer, 2006.
- [3] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back-propagating errors,” nature, vol. 323, no. 6088, p. 533, 1986.
- [4] K.-S. Oh and K. Jung, “GPU implementation of neural networks,” Pattern Recognition, vol. 37, no. 6, pp. 1311–1314, 2004.
- [5] D. C. Ciresan, U. Meier, L. M. Gambardella, and J. Schmidhuber, “Deep big simple neural nets excel on handwritten digit recognition,” CoRR, 2010.
- [6] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems,2012, pp. 1097–1105.
- [7] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” CoRR, 2014.
- [8] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich et al., “Going deeper with convolutions,” in CVPR, 2015.
- [9] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proceedings of the IEEE conference on computervision and pattern recognition, 2014, pp. 580–587.
- [10] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems, 2015, pp. 91–99.
- [11] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified,real-time object detection,” in Proceedings of the IEEE conference on computervision and pattern recognition, 2016, pp. 779–788.
- [12] A. Mohamed, G. E. Dahl, and G. Hinton, “Acoustic modeling using deep belief networks,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 1, pp. 14–22, 2012.
- [13] G. E. Dahl, D. Yu, L. Deng, and A. Acero, “Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition,” IEEE Transactions on audio,speech, and language processing, vol. 20, no. 1, pp. 30–42, 2012.
- [14] G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath et al., “Deep neural networks for acoustic modeling in speech recognition: The sharedviews of four research groups,” IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82–97, 2012.
- [15] D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chen, J. Chen, J. Chen, Z. Chen, M. Chrzanowski, A. Coates, G. Diamos, K. Ding, N. Du, E. Elsen, J. Engel, W. Fang, L. Fan, C. Fougner, L. Gao, C. Gong, A. Hannun, T. Han, L. Johannes, B. Jiang, C. Ju, B. Jun, P. LeGresley, L. Lin, J. Liu, Y. Liu, W. Li, X. Li, D. Ma, S. Narang, A. Ng, S. Ozair, Y. Peng, R. Prenger, S. Qian, Z. Quan, J. Raiman, V. Rao, S. Satheesh, D. Seetapun, S. Sengupta, K. Srinet, A. Sriram, H. Tang, L. Tang, C. Wang, J. Wang, K. Wang, Y. Wang, Z. Wang, Z. Wang, S. Wu, L. Wei, B. Xiao, W. Xie, Y. Xie, D. Yogatama, B. Yuan, J. Zhan, and Z. Zhu, “Deep speech 2 : End-to-end speech recognition in english and mandarin,” in Proceedings of The 33rd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. F. Balcan and K. Q. Weinberger, Eds., vol 48. New York, New York, USA: PMLR, 20–22 Jun 2016, pp. 173–182.
- [16] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton et al., “Mastering the game of go without human knowledge,” Nature, vol. 550, no. 7676, p. 354, 2017.
- [17] “Smartening up with artificial intelligence (ai) - what’s in it for germany and its industrial sector?” McKinsey & Company, Inc, Tech. Rep., 4 2017. [Online].Available: https://www.mckinsey.de/files/170419 mckinsey ki final m.pdf
- [18] E. V. T. V. Serooskerken, “Artificial intelligence in wealth and asset management,” Pictet on Robot Advisors, Tech. Rep., 1 2017.[Online]. Available: https://perspectives.pictet.com/wp-content/uploads/2016/12/Edgar-van-Tuyll-van-Serooskerken-Pictet-Report-winter-2016-2.pdf
- [19] A. van den Oord, T. Walters, and T. Strohman, “Wavenet launches in the google assistant.” `[Online]. Available: https://deepmind.com/blog/wavenet-launches-google-assistant/
- [20] Siri Team, “Deep learning for siri’s voice: On-device deep mixture density networks for hybrid unit selection synthesis,” 8 2017. [Online]. Available: https://machinelearning.apple.com/2017/08/06/siri-voices.html
- [21] J. Wakefield, “Microsoft chatbot is taught to swear on twitter.” `[Online]. Available:www.bbc.com/news/technology-35890188
- [22] J. Guynn, “Google photos labeled black people ’gorillas’.” `[Online]. Available: https://www.usatoday.com/story/tech/2015/07/01/ google-apologizes-after-photos-identify-black-people-as-gorillas/29567465/
- [23] J. Buolamwini and T. Gebru, “Gender shades: Intersectional accuracy disparities in commercial gender classification,” in Conference on fairness, accountability and transparency, 2018, pp. 77–91.
- [24] Tesla Team, “A tragic loss.” `[Online]. Available: https://www.tesla.com/en GB/blog/tragic-loss
- [25] ABC News, “Uber suspends self-driving car tests after vehicle hits and kills woman crossing the street in arizona,” 2018. [Online]. Available: http://www.abc.net.au/news/2018-03-20/uber-suspends-self-driving-car-tests-after-fatal-crash/9565586
- [26] Council of European Union, “Regulation (eu) 2016/679 of the european parliment and of the council,” 2016.
- [27] B. Goodman and S. Flaxman, “European union regulations on algorithmic decision making and a right to explanation,” AI magazine, vol. 38, no. 3, pp. 50–57, 2017.
- [28] M. Vu, T. Adali, D. Ba, G. Buzsaki, D. Carlson, K. Heller, C. Liston, C. Rudin, V. Sohal, A. Widge, H. Mayberg, G. Sapiro, and K. Dzirasa, “A sharedvision for machine learning in neuroscience,” JOURNAL OF NEUROSCIENCE, vol. 38, no. 7, pp. 1601–1607, 2018.
- [29] A. Holzinger, C. Biemann, C. S. Pattichis, and D. B. Kell, “What do we need to build explainable ai systems for the medical domain?” arXiv preprint arXiv:1712.09923, 2017.
- [30] R. Caruana, Y. Lou, J. Gehrke, P. Koch, M. Sturm, and N. Elhadad, “Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission,” in Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2015, pp. 1721–1730.
- [31] D. Gunning, “Explainable artificial intelligence (xai),” Defense Advanced Research Projects Agency (DARPA), nd Web, 2017.
- [32] D. J. MacKay, “Probable networks and plausible predictionsa review of practical bayesian methods for supervised neural networks,” Network: computation in neural systems, vol. 6, no. 3, pp. 469–505, 1995.
- [33] J. Lampinen and A. Vehtari, “Bayesian approach for neural networks review and case studies,” Neural networks, vol. 14, no. 3, pp. 257–274, 2001.
- [34] H. Wang and D.-Y. Yeung, “Towards bayesian deep learning: A survey,” arXiv preprint arXiv:1604.01662, 2016.
- [35] K. Murphey, Machine learning, a probabilistic perspective. Cambridge, MA: MIT Press, 2012.
- [36] X. Glorot, A. Bordes, and Y. Bengio, “Deep sparse rectifier neural networks,” in AISTATS, 2011, pp. 315–323.
- [37] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier nonlinearities improve neural network acoustic models,” in ICML, vol. 30, 2013, p. 3.
- [38] R. M. Neal, Bayesian learning for neural networks. Springer Science & Business Media, 1996, vol. 118.
- [39] Y. Gal, “Uncertainty in deep learning,” University of Cambridge, 2016.
- [40] N. Tishby, E. Levin, and S. A. Solla, “Consistent inference of probabilities in layered networks: predictions and generalizations,” in International 1989 Joint Conference on Neural Networks, 1989, pp. 403–409 vol.2.
- [41] J. S. Denker and Y. Lecun, “Transforming neural-net output levels to probability distributions,” in NeurIPS, 1991, pp. 853–859.
- [42] G. Cybenko, “Approximation by superpositions of a sigmoidal function,” Mathematics of control, signals and systems, vol. 2, no. 4, pp. 303–314, 1989.
- [43] K.-I. Funahashi, “On the approximate realization of continuous mappings by neural networks,” Neural networks, vol. 2, no. 3, pp. 183–192, 1989.
- [44] K. Hornik, “Approximation capabilities of multilayer feedforward networks,” Neural networks, vol. 4, no. 2, pp. 251–257, 1991.
- [45] S. F. Gull and J. Skilling, “Quantified maximum entropy memsys5 users manual,” Maximum Entropy Data Consultants Ltd, vol. 33, 1991.
- [46] D. J. MacKay, “Bayesian interpolation,” Neural computation, vol. 4, no. 3, pp. 415–447, 1992.
- [47] ——, “Bayesian methods for adaptive models,” Ph.D. dissertation, California Institute of Technology, 1992.
- [48] ——, “A practical bayesian framework for backpropagation networks,” Neural computation, vol. 4, no. 3, pp. 448–472, 1992.
- [49] M. I. Jordan, Z. Ghahramani, T. S. Jaakkola, and L. K. Saul, “An introduction to variational methods for graphical models,” Machine learning, vol. 37, no. 2, pp. 183–233, 1999.
- [50] M. J. Wainwright, M. I. Jordan et al., “Graphical models, exponential families, and variational inference,” Foundations and Trends R ? in Machine Learning, vol. 1, no.1–2, pp. 1–305, 2008.
- [51] D. M. Blei, A. Kucukelbir, and J. D. McAuliffe, “Variational inference: A review for statisticians,” Journal of the American Statistical Association, vol. 112, no. 518, pp. 859–877, 2017.
- [52] M. D. Hoffman, D. M. Blei, C. Wang, and J. Paisley, “Stochastic variational inference,” The Journal of Machine Learning Research, vol. 14, no. 1, pp. 1303–1347, 2013.
- [53] D. Barber and C. M. Bishop, “Ensemble learning in bayesian neural networks,” NATO ASI SERIES F COMPUTER AND SYSTEMS SCIENCES, vol. 168, pp. 215–238,1998.
- [54] G. E. Hinton and D. Van Camp, “Keeping the neural networks simple by minimizing the description length of the weights,” in Proceedings of the sixth annual conference on Computational learning theory. ACM, 1993, pp. 5–13.
- [55] M. Betancourt, “A conceptual introduction to hamiltonian monte carlo,” arXiv preprint arXiv:1701.02434, 2017.
- [56] M. Betancourt, S. Byrne, S. Livingstone, M. Girolami et al., “The geometric foundations of hamiltonian monte carlo,” Bernoulli, vol. 23, no. 4A, pp. 2257–2298, 2017.
- [57] G. Madey, X. Xiang, S. E. Cabaniss, and Y. Huang, “Agent-based scientific simulation,” Computing in Science & Engineering, vol. 2, no. 01, pp. 22–29, jan 2005.
- [58] S. Duane, A. D. Kennedy, B. J. Pendleton, and D. Roweth, “Hybrid monte carlo,” Physics letters B, vol. 195, no. 2, pp. 216–222, 1987.
- [59] R. M. Neal et al., “MCMC using hamiltonian dynamics,” Handbook of markov chain monte carlo, vol. 2, no. 11, p. 2, 2011.
- [60] S. Brooks, A. Gelman, G. Jones, and X.-L. Meng, Handbook of markov chain monte carlo. CRC press, 2011.
- [61] M. Welling and Y. Teh, “Bayesian learningvia stochastic gradient langevin dynamics,” Proceedings of the 28th International Conference on Machine Learning, ICML 2011, pp. 681–688, 2011.
- [62] A. Graves, “Practical variational inference for neural networks,” in Advances in Neural Information Processing Systems 24, J. Shawe-Taylor, R. S. Zemel, P. L. Bartlett,F. Pereira, and K. Q. Weinberger, Eds. Curran Associates, Inc., 2011, pp. 2348–2356.
- [63] M. Opper and C. Archambeau, “The variational gaussian approximation revisited,” Neural computation, vol. 21, no. 3, pp. 786–792, 2009.
- [64] J. M. Hern´ andez-Lobato and R. Adams, “Probabilistic backpropagation for scalable learning of bayesian neural networks,” in International Conference on Machine Learning, 2015, pp. 1861–1869.
- [65] J. Paisley, D. Blei, and M. Jordan, “Variational bayesian inference with stochastic search,” arXiv preprint arXiv:1206.6430, 2012.
- [66] J. R. Wilson, “Variance reduction techniques for digital simulation,” American Journal of Mathematical and Management Sciences, vol. 4, no. 3-4, pp. 277–312, 1984.
- [67] M. Opper and C. Archambeau, “The variational gaussian approximation revisited,” Neural computation, vol. 21 3, pp. 786–92, 2009.
- [68] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [69] D. J. Rezende, S. Mohamed, and D. Wierstra, “Stochastic backpropagation and approximate inference in deep generative models,” in Proceedings of the 31st International Conference on Machine Learning (ICML), 2014, pp. 1278–1286.
- [70] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,” The Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929–1958, 2014.
- [71] D. P. Kingma, T. Salimans, and M. Welling, “Variational dropout and the local reparameterization trick,” in Advances in Neural Information Processing Systems, 2015, pp. 2575–2583.
- [72] S. Wang and C. Manning, “Fast dropout training,” in international conference on machine learning, 2013, pp. 118–126.
- [73] A. Livnat, C. Papadimitriou, N. Pippenger, and M. W. Feldman, “Sex, mixability, and modularity,” Proceedings of the National Academy of Sciences, vol. 107, no. 4, pp. 1452–1457, 2010.
- [74] M. Opper and O. Winther, “A bayesian approach to on-line learning,” On-line learning in neural networks, pp. 363–378, 1998.
- [75] T. P. Minka, “A family of algorithms for approximate bayesian inference,” Ph.D. dissertation, Massachusetts Institute of Technology, 2001.
- [76] C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra, “Weight uncertainty in neural networks,” arXiv preprint arXiv:1505.05424, 2015.
- [77] C. K. Williams, “Computing with infinite networks,” in Advances in neural information processing systems, 1997, pp. 295–301.
- [78] J. Lee, J. Sohl-dickstein, J. Pennington, R. Novak, S. Schoenholz, and Y. Bahri, “Deep neural networks as gaussian processes,” in International Conference on Learning Representations, 2018.
- [79] A. Damianou and N. Lawrence, “Deep gaussian processes,” in AISTATS, 2013, pp. 207–215.
- [80] A. Damianou, “Deep gaussian processes and variational propagation of uncertainty,” Ph.D. dissertation, University of Sheffield, 2015.
- [81] N. Lawrence, “Deep gaussian processes,” 2019. [Online]. Available: http://inverseprobability.com/talks/notes/deep-gaussian-processes.html
- [82] A. Damianou, M. K. Titsias, and N. D. Lawrence, “Variational gaussian process dynamical systems,” in NeurIPS, 2011, pp. 2510–2518.
- [83] M. Titsias, “Variational learning of inducing variables in sparse gaussian processes,” in Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, D. van Dyk and M. Welling, Eds., vol. 5. Hilton Clearwater Beach Resort, Clearwater Beach, Florida USA: PMLR, 16–18 Apr 2009, pp. 567–574.
- [84] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Insights and applications,” in Deep Learning Workshop, ICML, vol. 1, 2015, p. 2.
- [85] ——, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in ICML, 2016, pp. 1050–1059.
- [86] ——, “Dropout as a bayesian approximation: Appendix,” arXiv preprint arXiv:1506.02157, 2015.
- [87] A. Garriga-Alonso, L. Aitchison, and C. E. Rasmussen, “Deep convolutional networks as shallow gaussian processes,” arXiv preprint arXiv:1808.05587, 2018.
- [88] R. Novak, L. Xiao, Y. Bahri, J. Lee, G. Yang, D. A. Abolafia, J. Pennington, and J. Sohl-dickstein, “Bayesian deep convolutional networks with many channels are gaussian processes,” in International Conference on Learning Representations, 2019.
- [89] M. Van der Wilk, C. E. Rasmussen, and J. Hensman, “Convolutional gaussian processes,” in Advances in Neural Information Processing Systems, 2017, pp. 2849–2858.
- [90] D. J. MacKay and D. J. Mac Kay, Information theory, inference and learning algorithms. Cambridge university press, 2003.
- [91] B. Wang and D. Titterington, “Inadequacy of interval estimates corresponding to variational bayesian approximations.” in AISTATS. Barbados, 2005.
- [92] R. E. Turner and M. Sahani, “Two problems with variational expectation maximisation for time-series models,” in Bayesian Time Series Models, D. Barber, A. T. Cemgil, and S. Chiappa, Eds. Cambridge University Press, 2011.
- [93] R. Giordano, T. Broderick, and M. I. Jordan, “Covariances, robustness, and variational bayes,” Journal of Machine Learning Research, vol. 19, no. 51, pp. 1–49, 2018.
- [94] D. Hafner, D. Tran, A. Irpan, T. Lillicrap, and J. Davidson, “Reliable uncertainty estimates in deep neural networks using noise contrastive priors,” arXiv preprint arXiv:1807.09289, 2018.
- [95] V. Kuleshov, N. Fenner, and S. Ermon, “Accurate uncertainties for deep learning using calibrated regression,” arXiv preprint arXiv:1807.00263, 2018.
- [96] Y. Gal, J. Hron, and A. Kendall, “Concrete dropout,” in Advances in Neural Information Processing Systems, 2017, pp. 3581–3590.
- [97] C. J. Maddison, A. Mnih, and Y. W. Teh, “The concrete distribution: A continuous relaxation of discrete random variables,” arXiv preprint arXiv:1611.00712, 2016.
- [98] T. S. Jaakkola and M. I. Jordan, “Improving the mean field approximationvia the use of mixture distributions,” in Learning in graphical models. Springer, 1998, pp. 163–173.
- [99] C. Louizos and M. Welling, “Structured and efficient variational deep learning with matrix gaussian posteriors,” in International Conference on Machine Learning, 2016, pp. 1708–1716.
- [100] E. G. Tabak and E. Vanden-Eijnden, “Density estimation by dual ascent of the log-likelihood,” Commun. Math. Sci., vol. 8, no. 1, pp. 217–233, 03 2010.
- [101] E. G. Tabak and C. V. Turner, “A family of nonparametric density estimation algorithms,” Communications on Pure and Applied Mathematics, vol. 66, no. 2, pp. 145–164, 2013.
- [102] D. J. Rezende and S. Mohamed, “Variational inference with normalizing flows,” arXiv preprint arXiv:1505.05770, 2015.
- [103] C. Louizos and M. Welling, “Multiplicative normalizing flows for variational bayesianneural networks,” in Proceedings of the 34th International Conference on Machine Learning - Volume 70, ser. ICML’17. JMLR.org, 2017, pp. 2218–2227.
- [104] L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real NVP,”CoRR, vol. abs/1605.08803, 2016.
- [105] C. Cremer, X. Li, and D. K. Duvenaud, “Inference suboptimality in variational au-toencoders,” CoRR, vol. abs/1801.03558, 2018.
- [106] S.-i. Amari, Differential-geometrical methods in statistics. Springer Science & Busi-ness Media, 2012, vol. 28.
- [107] T. Minka et al., “Divergence measures and message passing,” Technical report, Mi-crosoft Research, Tech. Rep., 2005.
- [108] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama,and T. Darrell, “Caffe: Convolutional architecture for fast feature embedding,” arXiv preprint arXiv:1408.5093, 2014.
- [109] F. Chollet, “keras,” https://github.com/fchollet/keras, 2015.
- [110] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado,A. Davis, J. Dean, M. Devin, S. Ghemawat, I. J. Goodfellow, A. Harp, G. Irving,M. Isard, Y. Jia, R. J´ ozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Man´ e,R. Monga, S. Moore, D. G. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner,I. Sutskever, K. Talwar, P. A. Tucker, V. Vanhoucke, V. Vasudevan, F. B.vi´ egas,O.vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng, “Tensor-flow: Large-scale machine learning on heterogeneous distributed systems,” CoRR,vol. abs/1603.04467, 2016.
- [111] J. V. Dillon, I. Langmore, D. Tran, E. Brevdo, S. Vasudevan, D. Moore, B. Patton,A. Alemi, M. D. Hoffman, and R. A. Saurous, “Tensorflow distributions,” CoRR, vol. abs/1711.10604, 2017.
- [112] P. Adam, G. Sam, C. Soumith, C. Gregory, Y. Edward, D. Zachary, L. Zeming, D. Al-ban, A. Luca, and L. Adam, “Automatic differentiation in pytorch,” in Proceedings of Neural Information Processing Systems, 2017.
- [113] T. Chen, M. Li, Y. Li, M. Lin, N. Wang, M. Wang, T. Xiao, B. Xu, C. Zhang, and Z. Zhang, “Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems,” CoRR, vol. abs/1512.01274, 2015.
- [114] A. Kucukelbir, D. Tran, R. Ranganath, A. Gelman, and D. M. Blei, “Automatic Differentiation Variational Inference,” arXiv e-prints, p. arXiv:1603.00788, Mar 2016.
- [115] S. Patterson and Y. W. Teh, “Stochastic gradient riemannian langevin dynamics on the probability simplex,” in Advances in Neural Information Processing Systems 26,C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger, Eds.Curran Associates, Inc., 2013, pp. 3102–3110.
- [116] T. Chen, E. Fox, and C. Guestrin, “Stochastic gradient hamiltonian monte carlo,” in Proceedings of the 31st International Conference on Machine Learning, ser. Proceed-ings of Machine Learning Research, E. P. Xing and T. Jebara, Eds., vol. 32. PMLR, 22–24 Jun 2014, pp. 1683–1691.
- [117] C. Li, C. Chen, D. Carlson, and L. Carin, “Preconditioned Stochastic Gradient Langevin Dynamics for Deep Neural Networks,” arXiv e-prints, Dec. 2015.
- [118] M. Betancourt, “The fundamental incompatibility of scalable hamiltonian montecarlo and naive data subsampling,” in Proceedings of the 32Nd International Confer-ence on International Conference on Machine Learning - Volume 37, ser. ICML’15.JMLR.org, 2015, pp. 533–540.
- [119] I. Osband, C. Blundell, A. Pritzel, and B. V. Roy, “Deep explorationvia bootstrapped DQN,” CoRR, vol. abs/1602.04621, 2016.
- [120] A. G. d. G. Matthews, M. van der Wilk, T. Nickson, K. Fujii, A. Boukouvalas,P. Le´ on-villagr´ a, Z. Ghahramani, and J. Hensman, “GPflow: A Gaussian process library using TensorFlow,” Journal of Machine Learning Research, vol. 18, no. 40, pp. 1–6, 4 2017.
- [121] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, “Backpropagation applied to handwritten zip code recognition,” Neural computation, vol. 1, no. 4, pp. 541–551, 1989.
- [122] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT Press, 2016.
- [123] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, Nov 1998.





