自回归模型概览
【摘要】
【原文】 Murphy, Kevin P. Chapter 22 of Probabilistic Machine Learning: Advanced Topics. MIT Press, 2023. probml.ai.
【参考】
1 概述
根据概率链式法则,我们可以写出 T 个变量上的任意联合分布如下:
其中 是第 个观测,我们定义 作为初始状态分布。
上述模型被称为自回归模型,对应于一个全连接的有向无环图,其中每个节点都依赖于其排序中的所有前辈,如 图 1 所示。模型也可以以任意输入或上下文 为条件,来定义 ,但为了符号简洁,本文省略了这一点。
我们当然也可以按照时间顺序 “反向” 分解联合分布:
但这种 “反因果” 方向通常更难学习(参见例如 [PJS17])。
尽管 公式 (1) 中的分解是一般性的,但该表达式中的每一项(即每个条件分布 )会变得越来越复杂,因为它依赖的参数越来越多,这使得这些项的计算速度变慢,并且需要更多数据来估计这些参数。
解决此问题的一种方法是做(一阶) 马尔可夫假设,进而产生 马尔可夫模型 。这也被称为一阶自回归模型。不幸的是,马尔可夫假设非常受限。
放宽该限制的一种方法是:让 依赖于所有过去的 但不显式地回归它们,我们可以假设过去可以被压缩到隐状态 中。
- 如果 是过去观测 的确定性函数,则生成的模型称为循环神经网络。
- 如果 是过去隐藏状态 的随机函数,则生成的模型称为 隐马尔可夫模型。
另一种方法是保留 公式 (1) 的通用自回归模型,但是对条件 使用一种严格受限的函数形式,例如某种类型的神经网络。该方法既不做条件独立性假设,也未明确将过去压缩为一个统计量,而是隐含地学习了从过去到未来的一种紧凑映射。此类 AR 模型的主要优点是易于计算和优化每个序列(数据向量)的确切似然;其主要缺点是生成的样本在本质上是顺序的,这可能很慢。此外,该方法并不学习数据的紧凑隐表示,因此无法通过对隐表示的随机采样生成新样本。

图 1:全连接自回归模型。
2 神经自回归密度估计器(NADE)
一种表示条件概率分布 的简单方法是使用 [Fre98] 中提出的广义线性模型,例如逻辑斯谛回归;但我们也可以通过使用神经网络使模型更强大。采用神经网络的模型被称为 神经自回归密度估计器 或 NADE 模型 [LM11]。
如果假设 是高斯的条件混合,我们会得到一个被称为 RNADE(“Real-valued Neural Autoregressive Density Estimator”) 的模型 [UML13] 。更准确地说,其形式为:
其中 时刻的分布参数由神经网络生成, 。
与使用独立的神经网络 不同,创建具有 个输入和 个输出的单一神经网络会更有效。通常可以使用掩码来实现,从而产生一个被称为 MADE(“密度估计的掩码自动编码器”)模型 [Ger+15] 。
NADE 型模型的缺点是: 它们假设变量具有自然的线性顺序。这对于时间或顺序数据有意义,但对于更一般的数据类型(例如图像或图形)则不然。 [UML14;Uri+16] 中提出了对 NADE 的无顺序扩展方法。
3 因果卷积神经网络(Causal CNN)
表示分布 的一种方法是尝试识别已经过去的历史中有可能预测 值的模式。如果假设这些模式可以发生在任何位置,那么使用卷积神经网络来检测它们是有意义的。但我们需要确保只将卷积掩码应用于过去的输入,而不是未来的输入。这可以使用掩蔽卷积来完成,也称为因果卷积。
3.1 一维情况( 卷积马尔可夫模型 )
考虑 离散序列的以下卷积马尔可夫模型:
其中 是大小为 的卷积滤波器,为了符号简单起见,我们假设了单个非线性 和分类输出。这就像常规的一维卷积,只是我们“屏蔽”了未来的输入,因此 仅取决于过去的值。我们当然可以使用更深层次的模型,并且可以以输入特征 为条件。
为了捕获远距离的依赖关系,我们可以使用扩张卷积(参见 [Mur22, Sec 14.4.1])。该模型已成功用于创建最先进的文本到语音 (TTS) 合成系统,称为 wavenet [oor-16]。参见 图 2 的说明。 wavenet 模型 是一个条件模型,,其中 是从输入的单词序列中导出的一组语言特征, 是原始音频。
tacotron 系统 [Wan ] 是一种完全端到端的方法,其中输入是单词而不是语言特征。
尽管wavenet 可以产生高质量语音,但它对于生产系统的使用来说太慢了。但 “提炼” 成并行生成模型 [Oor+18],参见 归一化流模型中的自回归流。

图 2:使用扩张(atrous)卷积的 wavenet 模型图示,扩张因子为 1、2、4 和 8。来自 [oor+16] 的 图 3。
3.2 二维情况( PixelCNN )
我们可以将因果卷积扩展到 ,获得形式如下的自回归模型
其中 是行数, 为列数,我们以光栅扫描顺序对所有先前生成的像素进行调节,如 图 3 所示,这被称为 pixelCNN 。
该模型的朴素采样(生成)需要 时间,其中 是像素数,但 [Ree+17] 展示了如何使用多尺度方法将复杂度降低到 。
已经提出了该模型的各种扩展。
- [Sal+17c] 的
pixelCNN++模型通过使用逻辑分布的混合来提高质量,以捕获 的多模态。 - [OKK16] 的
pixelRNN将掩码卷积与 RNN 相结合,以获得更远范围的上下文相关性。 - [MK19] 的
Subscale Pixel Network提议生成像素,使得高阶位在低阶位之前被采样,这允许以整个图像的低分辨率版本为条件对高分辨率细节进行采样,而不仅仅是左上角角落。

图 3:PixelCNN 模型中因果二维卷积的图示。红色直方图显示了单个 RGB 通道的单个像素的离散值的经验分布。红色和绿色的 5 × 5 数组显示了二进制掩码,它选择左上角的上下文,以确保卷积是因果的。右侧的图表说明了我们如何通过使用包含所有先前行的垂直上下文堆栈和仅包含当前行的值的水平上下文堆栈来避免盲点。来自 [Oor+16] 的图 1。经 Aaron van den Oord 许可使用。
4 Transformer 解码器
关于 Transformer
考虑对句子中的每个单词进行分类的问题,例如使用其词性标签(名词、动词等)。也就是说,我们要学习一个映射 f : X → Y,其中 X = VT 是在(单词)词汇表 V 上定义的输入序列的集合,T 是句子的长度,Y = T T 是输出的集合序列,在(标记)词汇表 T 上定义。为了做好这项任务,我们需要学习每个单词的上下文嵌入。 RNN 一次处理一个标记,因此单词在位置 t 的嵌入 zt 取决于网络的隐藏状态 st,它可能是所有先前看到的单词的有损总结。我们可以创建双向 RNN,这样未来的词也可以影响 zt 的嵌入,但这种依赖性仍然是通过隐藏状态来调节的。另一种方法是通过使用第 16.2.7 节中讨论的注意力算子而不是使用隐藏状态来计算 zt 作为句子中所有其他单词的直接函数。这称为(仅编码器)转换器,并被 BERT [Dev+19] 等模型使用。图 16.16 概述了这个想法。
也可以创建一个仅解码器的转换器,其中每个输出 yt 只关注所有先前生成的输出 y1:t−1。这可以使用 masked attention 来实现,并且对于 GPT 等生成语言模型很有用(参见第 22.4.1 节)。我们可以结合编码器和解码器来创建一个条件序列到序列模型,p(y1:Ty |x1:Tx),如原始转换器论文 [Vas+17c] 中提出的那样。有关详细信息,请参阅补充第 16.1.1 节和 [PH22]。
已经发现,如果在足够多的数据上进行训练,大型转换器是非常灵活的序列到序列函数逼近器(参见例如 [Lin+21a] 以了解 NLP 的背景,以及 [Kha+21; Han+20 ; Zan21] 用于计算机视觉背景下的评论)。它们运作良好的原因仍然不是很清楚。然而,一些初步的见解可以在例如 [Rag+21; WGY21;内尔21; BP21]。另见补充第 16.1.2.5 节,我们在其中讨论与图神经网络的连接。
我们在 16.3.5 节介绍了转换器。它们可用于编码序列(如在 BERT 中)或解码(生成)序列。在本节中,我们关注后一种情况。
基本思路如下。在每一步 t,模型将掩蔽(因果)自我注意(第 16.2.7 节)应用于前 t 个输入 y1:t,以计算一组注意权重 a1:t。由此它计算出一个激活向量 zt = ∑t τ=1 atyt。然后通过前馈层计算 ht = MLP(zt)。对模型中的每一层重复此过程。最后,输出用于预测序列中的下一个元素 yt+1 ∼ Cat(softmax(Wht))。 (在条件生成设置中,我们想要计算 p(y|x),我们可以将前 x 个标记视为初始输出序列的一部分。不需要使用编码器块。)
在训练时,所有预测都可以并行发生,因为目标生成的序列已经可用。也就是说,给定输入 y1:t−1,可以预测第 t 个输出 yt,这可以同时对所有 t 完成。但是,在测试时,模型必须按顺序应用,因此将 t + 1 时产生的输出反馈到模型中以预测 t + 2 等。注意,transformers 的运行时间为 O(T 2),尽管已经开发了各种更有效的版本(参见例如 [Mur22, Sec 15.6] 了解详细信息)。

图 22.4:GPT-2 响应输入提示生成的示例文本。来自 https://openai. com/博客/更好的语言模型/。
Transformer 是许多流行的(条件)序列生成模型的基础。我们在下面给出一些例子:
4.1 文本生成(GPT)
在 [Rad+18] 中,OpenAI 提出了一个模型,称为 GPT,它是“Generative Pre-training Transformer”的缩写。这是一个仅解码器的转换器模型,它使用因果(掩蔽)注意力。在 [Rad+19] 中,他们提出了 GPT-2,它是 GPT 的更大版本(15 亿参数,或 6.5GB,对于 XL 版本),在大型网络语料库(800 万页,或 40GB)上训练。他们还简化了训练目标,只使用最大似然进行训练。 GPT-2 生成的文本流畅度相当显著;示例见图 22.4。另请参阅 https://demo.allennlp.org/nex_t-token-lm,它允许您与(中等大小的)模型进行交互,并在给定一些输入上下文的情况下生成 K 个最可能的序列(使用波束搜索计算)。
最近,OpenAI 发布了 GPT-3 [Bro+20d],它是 GPT-2(1750 亿参数)的更大版本,基于更多数据(3000 亿字)进行训练,但基于相同的原理。 (训练估计需要 355 GPU 年,花费 460 万美元。)由于数据和模型的庞大规模,GPT-3 显示出更显著的生成新颖文本的能力。特别是,可以(部分)通过更改条件提示来控制输出。这使模型能够执行它从未接受过训练的任务,只需在提示中给出一些示例即可。这称为“上下文学习”(参见第 19.5.1.2 节)。示例请参见图 22.5,请参见交互式演示。

图 22.5:使用 GPT-3 进行少量镜头学习的图示。该模型被要求使用一个新词创建一个例句,该词的含义在提示中提供。粗体是 GPT-3 的补全,浅灰色是人工输入。来自 [Bro+20d] 的图 3.16。
4.2 音乐生成
可以修改转换器解码器,使其生成音乐而不是自然语言,如音乐转换器论文 [Hua+18a] 所示。关键的“技巧”是要注意音乐的 midi 格式可以表示为参数化标记的序列,如图 22.6 所示。为了应对长序列长度,设计了一种相对注意力机制。有关可视化,请参见图 22.7。为了最好地欣赏生成输出的质量,请参阅交互式演示 。

图 22.6:一段钢琴演奏片段,可视化为钢琴卷(左)并编码为演奏事件(右,从左到右序列化,然后向下排列)。音符开/关有 128 个离散值,速度有 32 个值,时移有 100 个,因此输入是长度为 388 的单热向量序列。来自 [Hua+18a] 的图 7。经 Anna Huang 许可使用。

图 22.7:音乐转换器中注意力的图示。不同颜色的线对应于 6 个注意力头。线条粗细对应于注意力权重。来自[Hua+18a]的图8。经 Anna Huang 许可使用。
4.3 文本到图像生成(DALL-E)
OpenAI [Ram+21a] 的 DALL-E 模型 1 可以在给定文本提示的情况下生成具有卓越质量和多样性的图像,如图 22.8 所示。该方法在概念上非常简单,大部分精力都用于数据收集(他们在网上搜索了 2.5 亿图文对)并扩大训练规模(它们适合具有 120 亿个参数的模型)。这里我们只关注算法方法。
基本思想是使用离散 VAE 模型(第 21.6.5 节)将图像 x 转换为离散标记 z 序列,该模型定义了 p(x,z) 形式的模型。然后,我们将一个变换器拟合到图像标记 z 和文本标记 y 的连接上,以获得 p(z, y) 形式的模型。
为了在给定文本提示 y 的情况下对图像 x 进行采样,我们对潜在代码 z ∼ p(z|y) 进行采样,然后将 z 输入 VAE 解码器以得到 x ∼ p(x|z)。为每个提示生成多个图像,然后根据预先训练的评论家对它们进行排名,根据生成的图像与输入文本的匹配程度给它们评分:sn =评论家(xn,yn)。他们使用的批评者是对比 CLIP 模型(参见第 32.3.4.1 节)。这种有区别的重新排序显著改善了结果。
部分示例结果如图 22.8 所示,更多示例结果可在 https://openai 在线找到。 com/blog/dall-e/.图 22.8 右边的图像特别有趣,因为提示——“一个穿着圣诞毛衣的小刺猬遛狗的插图”——可以说要求模型解决“变量绑定问题”。这句话暗示刺猬应该穿毛衣而不是狗。我们看到该模型有时会正确解释这一点,但并非总是如此:有时它会用圣诞毛衣绘制两只动物。此外,有时它会画出一只刺猬走在一只较小的刺猬上。结果的质量也可能对提示的形式很敏感。因此,尽管令人印象深刻,但这项技术显然还不可靠
自 2021 年 1 月发布以来,已经提出了许多 DALL-E 的替代方案。比如谷歌发布了parti[Yu+22],和DALL-E类似,但是使用了 ViT-VQ-GAN 编码器[Yu+21],而不是 VQ-VAE编码器; XMC-GAN [Zha+21b],它使用 GAN 而不是 Transformer; Imagen [Sah+22],它使用扩散模型而不是 Transformer。 OpenAI 还发布了一个基于扩散的模型,称为 GLIDE [Nic+21],后来又发布了一个更好的扩散模型,称为 DALL-E 2 [Ram+22]。

图 22.8:DALL-E 模型响应文本提示生成的一些图像。 (a) “鳄梨形状的扶手椅”。 (b) “小刺猬穿着圣诞毛衣遛狗的插图”。来自 https://openai. com/博客/dall-e。
5 最大似然估计
经常用来衡量数据和模型分布之间近的程度的指标是 KL divergence,这个概念我们在 VI-变分推断里面也有提到。
\min \limits_{\theta \in \mathcal{M}} d_{KL}(p_{data},p_\theta) = \mathbf{E}_{\boldsymbol{x} \sim p_{data}}\[\log p_{data}(\boldsymbol{x}) - \log p_\theta(\boldsymbol{x})\]
首先 KL divergence 是不对称的,其次,它惩罚模型分布 如果它给那些在 下很有可能的点赋值了很低的概率。
因为 不依赖 , 我们可以发现可以通过最大似然估计来优化模型参数:
\max \limits_{\theta \in \mathcal{M}} \mathbf{E}_{\boldsymbol{x} \sim p_{data}}\[\log p_\theta(\boldsymbol{x})\]
为了能够近似未知的分布 ,我们假设在数据集 中的点都是独立同分布。这就让我们可以获得目标函数的无偏蒙特卡洛估计:
极大似然估计的直观上是要挑选出模型参数 ,最大化在数据集 中观测到的数据点的概率值。
极大似然估计如果求最优解相信大家都很熟悉,log-likelihood 对参数求导即可。这里给出自回归模型的 likelihood 形式:
其中, 为数据集大小, 为每个样本的随机变量个数, 为第 个样本中与第 个随机变量相连的其它随机变量。因此整个计算过程:
- 随机初始化
- 计算 (用反向传播)
- 更新参数:
当然我们也可以用随机梯度上升等方法, 还有很多其它的随机梯度上升的变种,采用不同的更新参数机制像是 Adam 和 RMSprop。
6 生成新样本
在自回归模型中,推断是很直接的。对于任何一个样本 的概率密度估计,只需要简单的计算每个随机变量的log 条件概率 ,然后相加得到样本点 log-likelihood。
从自回归模型中采样是一个序列化过程 (sequential procedure)。因此要先采样 ,然后根据 的值采样 ,以此类推直到 ( 依赖前 )。对于需要实时生成高维数据的应用语音合成等应用,序列化采样开销是很大的。
最后,自回归模型没有像变分自编码器、扩散模型等一样直接学习到数据的隐变量表示。
附录
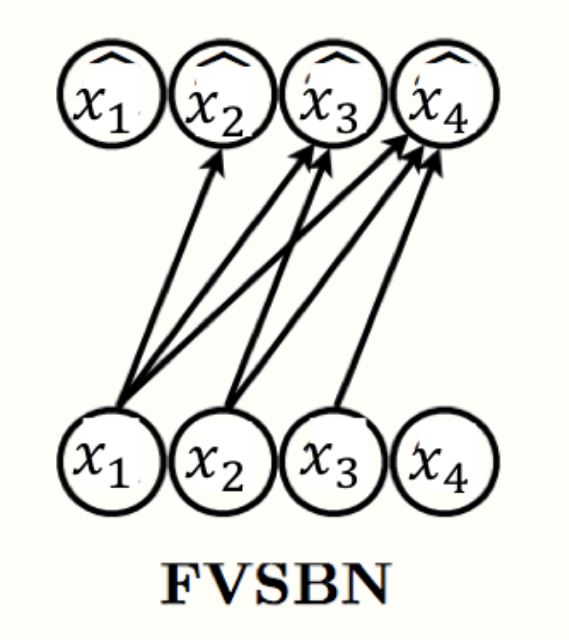
FVSBN
最简单的自回归生成模型的例子是,我们制定了这些函数必须是输入元素的线性组合再接一个sigmoid函数(把输出限制到0到1之间)。那么我们就得到了 fully-visible sigmoid belief network (FVSBN)。
其中 指的是sigmoid函数,参数 是均值函数 的参数。因此,总的模型参数量为 。
NADE
为了增加自回归生成模型的表达能力(expressiveness),我们可以用更加灵活的参数函数,比如多层感知机(multi-layer perceptrons, MLP)。例如,假设神经网络只有一个隐藏层,那么第 i 个随机变量的均值函数可以表示为:
其中, 是隐藏层的激活元, 是第 个均值函数的参数, 那么总参数主要取决于矩阵 ,所以我们可以得到总参数数量为
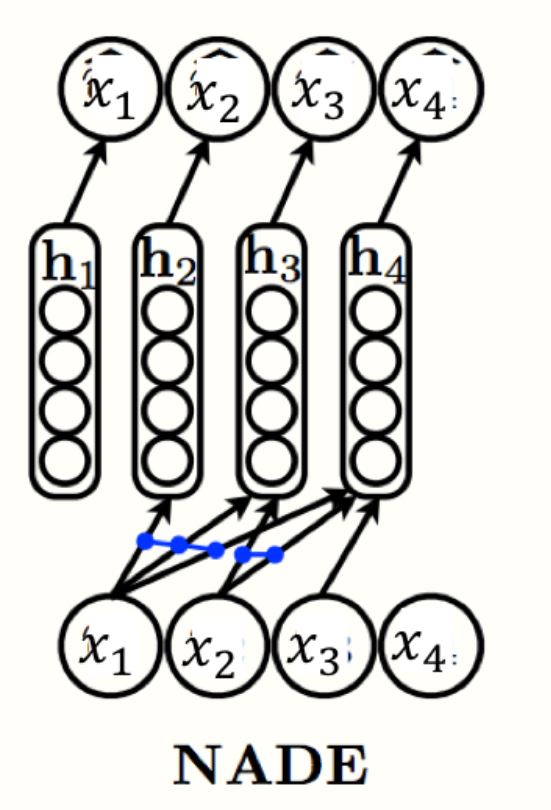
我们发现参数量还是很大,因此另一个方法是用 Neural Autoregressive Density Estimator (NADE),它采用了参数共享的方法,隐藏层表示为:
其中 是所有的均值函数( )的参数。矩阵 和 偏差向量 在所有的均值函数之间共享,共享参数提供了两个好处:
- 总的参数量从 减少到
- 隐藏层的激活值计算时间可以用下面的迭代策略减小到 :
RNADE
RNADE 算法拓展了 NADE来在实数数据上学习生成模型。假设我们的每个条件分布是由相等权重的 K个高斯组合而成的。 因此,我们不在学习一个均值函数,我们为每个条件分布都学习 K 个均值 和 K 个方差 , 每个函数 为第 个条件分布输出了 个高斯的均值和方差。
EoNADE
NADE 算法需要指定一个固定的随机变量顺序。选择不同的顺序会导致不同的模型。 EoNADE 算法允许用不同的顺序训练 NADE 模型的集合(ensemble)
MADE
表面上来看, FBSBN 和 NADE 和自编码器(autoencoder)很像,但是我们能在自编码器中得到一个生成模型吗?我们需要确保它符合一个有效的贝叶斯网络(DAG, 有向无环图结构),比如我们需要一个随机变量的顺序(ordering),如果顺序是1,2,3,那么:
- 不能依赖任何的输入 。在生成的采样的时候,一开始我们也不需要任何的输入。
- 只能依赖 , ….
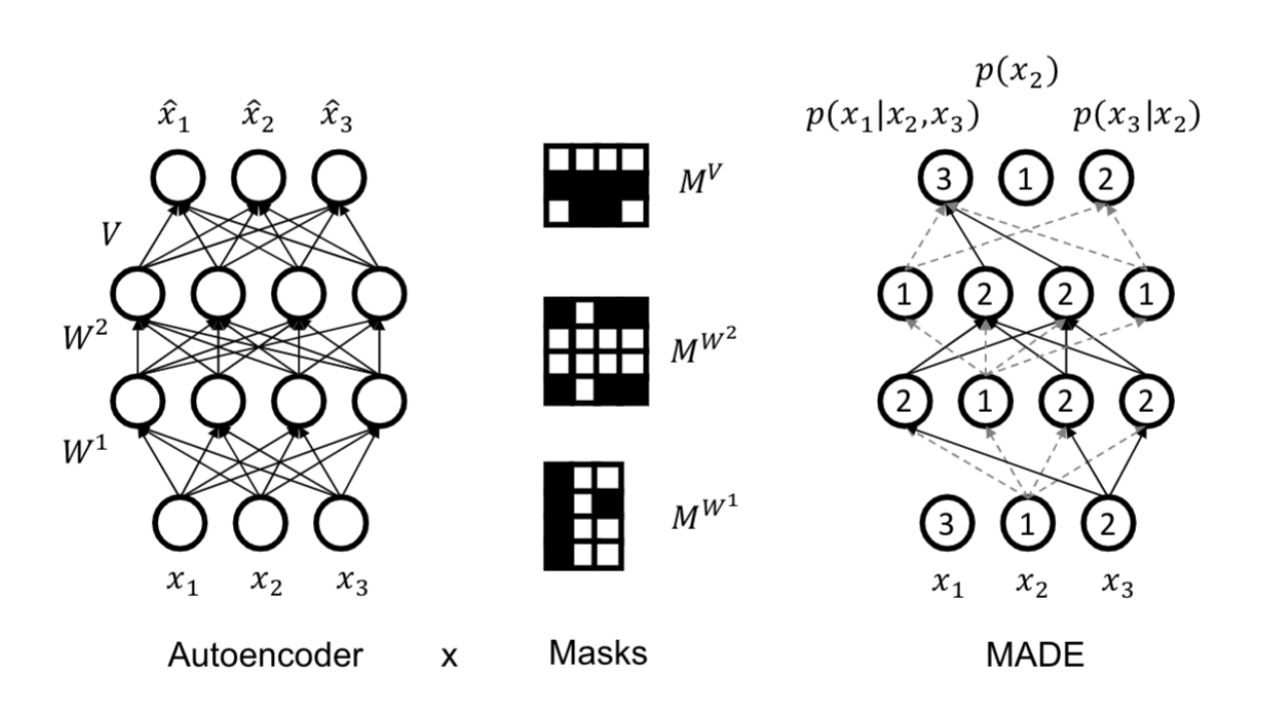
好处是我们可以只用一个神经网络(n个输出)来产生所有的参数。在 NADE 中,我们需要计算 n 次。 但是我们要怎么样才能把一个自编码器变成一个自回归(DAG结构)呢?
MADE (Masked Autoencoder for Distribution Estimation)方法是用掩码 mask把一些路径遮住。(见上图),假设顺序是 ,那么计算分布 的参数的时候是不依赖于任何输入的。 对于 是只依赖于 ,以此类推。其次,在隐藏层的每一层,随机在 中选择一个整数 ,这个选中的单元(units)只能依赖它在选定的顺序中的前 个数。在每层中加上 mask来保证这种无关性(invariant)。最后,在最后一层,把所有前一层中比当前单元小的那些单元连接起来。
RNN
RNN (Recurrent Neural Network) 相信大家都很熟悉了。它防止了自回归模型中 history 太长的问题。主要思想是,将 history 做一个 summary,并且迭代地更新它。
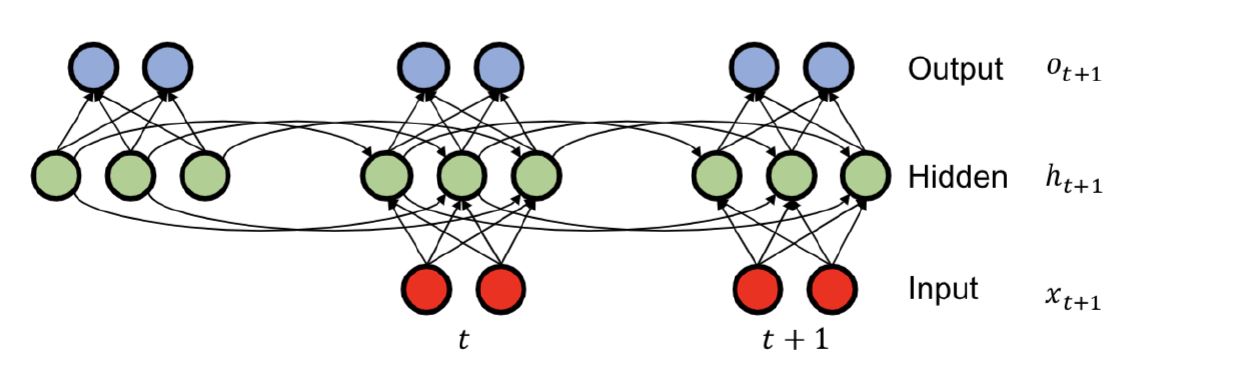
- Summary 更新规则:
- 输出的预测:
- Summary 初始胡:
我们可以发现参数的数量是恒定的。
实例展示
Character RNN
它的优点是可以应用到任意长度,并且比较泛化(general),缺点是仍然需要一个顺序(ordering),序列性的似然计算会很慢,并且生成样本也是序列的方式生成的。训练起来也可能会有梯度消失或者爆炸的问题。
Pixel RNN
图片按照光栅扫描(raster scan)(从左到右,再从右到左)的顺序进行建模。每个条件分布都需要指定三个颜色:
每个条件分布都是一个分类的(categorical)随机变量,256个值。条件分布的模型用 LSTMs + MASKing (类似于 MADE)。
![]()
PixelCNN
它用的是卷积的架构来在给定周边的像素情况下预测当前像素。因为要保证自回归的性质,所以用了掩码卷积(masked convolutions),保留了光栅扫描的顺序。在颜色序上,需要额外的掩码。
![]()
速度比 pixelRnn 快很多。
PixelDefend
机器学习的模型通常对一些对抗样本(adversarial examples)无法区分别,这些样本通常就是一张图加了一些噪音,那么我们要怎么找出这些对抗的样本呢?防止黑客hack我们的系统呢?
- 首先我们可以在干净的数据集上训练一个生成模型 , 比如用 PixelCNN
- 给定了一个新的输入 , 我们评估计算 的值
- 如果是对抗的样本的话,它的概率值 会非常小
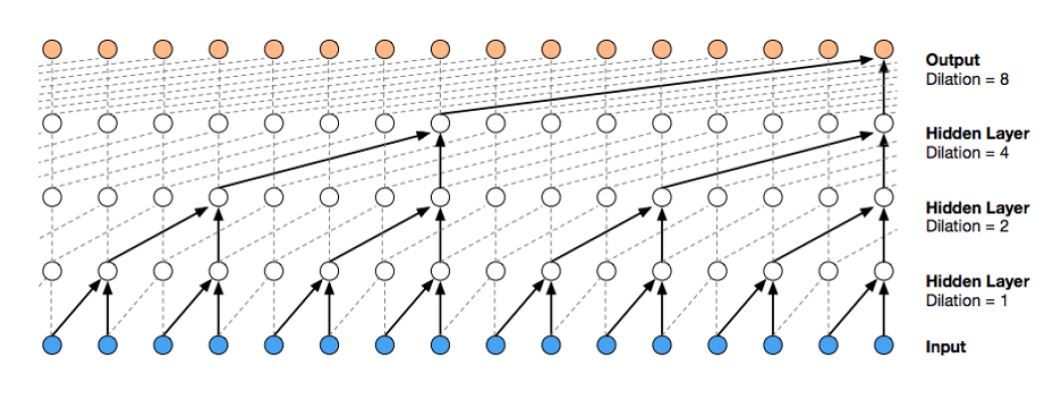
WaveNet
WaveNet 是语音合成上的一个模型,它用了膨胀卷积(dilated convolutions)来增加感受野(receptive field)。