【摘 要】 最大似然方法、期望最大化、变分推断三种方法,都可以用于对模型参数进行推断,但三者之间在应用场景上存在着显著区别,但也存在一定的关系。在知乎上看到一篇博文,内容貌似合理,但有更多概念是错误的,感觉有必要系统地梳理一下。
【参 考】 Reid, N. (2010) ‘Likelihood inference: Likelihood inference’, Wiley Interdisciplinary Reviews: Computational Statistics, 2(5), pp. 517–525. Available at: https://doi.org/10.1002/wics.110 .
【原 文】 https://zhuanlan.zhihu.com/p/378988804
1 建模场景设置
当建模的场景中存在混合效应时,通常会分别对 固定效应 和 随机效应 进行建模。例如,在空间统计场景中,通常将观测建模为如下形式:
Y ( s ) = X ( s ) β + η ϕ ( s ) + ϵ ( s ) \mathbf{Y}(\mathbf{s}) = \mathbf{X}(\mathbf{s}) \boldsymbol{\beta} + \eta_{\boldsymbol{\phi}}(\mathbf{s}) + \epsilon(\mathbf{s})
Y ( s ) = X ( s ) β + η ϕ ( s ) + ϵ ( s )
其中:
X ( s ) β \mathbf{X}(\mathbf{s}) \boldsymbol{\beta} X ( s ) β β \boldsymbol{\beta} β η ϕ ( s ) \eta_{\boldsymbol{\phi}}(\mathbf{s}) η ϕ ( s ) 0 0 0 ϕ \boldsymbol{\phi} ϕ ϵ ( s ) \epsilon(\mathbf{s}) ϵ ( s ) ϵ ( s ) = ϵ ∼ N ( 0 , σ ϵ 2 ) \epsilon(\mathbf{s})=\epsilon \sim \mathcal{N}(0,\sigma^2_{\epsilon}) ϵ ( s ) = ϵ ∼ N ( 0 , σ ϵ 2 ) σ ϵ 2 \sigma^2_{\epsilon} σ ϵ 2
此类模型在现实中是最常见的,需要根据样本对参数向量 θ = ( β , ϕ , σ ϵ 2 ) \boldsymbol{\theta} = (\boldsymbol{\beta},\boldsymbol{\phi},\sigma^2_{\epsilon}) θ = ( β , ϕ , σ ϵ 2 )
2 基础推断方法
根据贝叶斯定理:
p o s t o i r = l i k e l i h o o d × p r o i r e v i d e n c e postoir = \frac{likelihood \times proir}{evidence}
p os t o i r = e v i d e n ce l ik e l ih oo d × p ro i r
p ( θ ∣ D ; M ) = p ( D ∣ θ ; M ) p ( θ ; M ) p ( D ; M ) p(\boldsymbol{\theta} | \mathcal{D}; \mathcal{M}) = \frac{p(\mathcal{D} | \boldsymbol{\theta};\mathcal{M} )p(\boldsymbol{\theta};\mathcal{M} )}{p(\mathcal{D}; \mathcal{M})}
p ( θ ∣ D ; M ) = p ( D ; M ) p ( D ∣ θ ; M ) p ( θ ; M )
其中:
M \mathcal{M} M θ \boldsymbol{\theta} θ D \mathcal{D} D p ( θ ; M ) p(\boldsymbol{\theta} ; \mathcal{M}) p ( θ ; M ) 先验分布(简称先验) ,代表了人们对参数的先验知识p ( D ∣ θ ; M ) p(\mathcal{D} |\boldsymbol{\theta}; \mathcal{M}) p ( D ∣ θ ; M ) 似然函数(简称似然) ,代表了在特定 θ \boldsymbol{\theta} θ p ( D ; M ) p(\mathcal{D}; \mathcal{M}) p ( D ; M ) 证据或边缘似然 ),只是为了使后验是一个合理的概率,没有其他特殊解释p ( θ ∣ D ; M ) p(\boldsymbol{\theta} | \mathcal{D}; \mathcal{M}) p ( θ ∣ D ; M ) 后验分布(简称后验)
我们的目标是根据已知数据 D \mathcal{D} D M \mathcal{M} M θ \boldsymbol{\theta} θ
常用三种推断方法:
最大似然法 :仅考虑能够使 “ 似然 ” (即 p ( D ∣ θ ; M ) p(\mathcal{D} |\boldsymbol{\theta} ; \mathcal{M}) p ( D ∣ θ ; M ) θ ^ \hat{\boldsymbol{\theta}} θ ^ 最大后验法 :考虑能够使分子项 “先验 × \times × ” (即 p ( D ∣ θ ; M ) p ( θ ; M ) p(\mathcal{D} | \boldsymbol{\theta};\mathcal{M})p(\boldsymbol{\theta};\mathcal{M}) p ( D ∣ θ ; M ) p ( θ ; M ) θ ^ \hat{\boldsymbol{\theta}} θ ^ 贝叶斯方法 :将所有可能的参数值及其概率都列出,既考虑了模型参数的完整先验分布,又考虑了模型参数的完整后验分布,其推断结果是模型参数的一个概率分布。
在实际工作中,最大似然法和贝叶斯方法使用比较广泛。可以很容易看出:
最大似然法 : 计算快捷,但丢失了不确定性度量;
贝叶斯方法 : 由于要处理涉及一个区间的概率分布,而非单一的点,所以计算量巨大,并导致其应用受限,但能够保留不确定信息。
注: 似然函数通常基于对感兴趣变量的建模假设和选择,但通常这些假设必须是可参数化的,因为这是参数估计的基础:
最常见的选择是简单分布,例如:
假设感兴趣的连续型变量 y y y
假设感兴趣的计数型变量 c o u n t count co u n t
假设类别型变量 c l a s s class c l a ss
通过组合形成对感兴趣变量的建模假设,例如:
假设感兴趣的连续性变量 y y y
通过变换形成对感兴趣变量的建模假设,例如:
更复杂的情况出现在感兴趣变量无法作出概率分布建模的情况,这通常被称为 无似然方法(Free-Likelyhood Method) 或 近似贝叶斯计算(ABC) 参见 《近似贝叶斯计算简明教程》
3 基于似然的推断
将 第 1 节 的场景和 第 2 节 的方法结合,我们重点关注 最大似然估计方法 和 贝叶斯估计方法 。本节没有直接以 最大似然估计方法 为标题,是因为最大似然估计方法只是基于似然的推断方法中的一类,难以涵盖更广泛的知识体系。即便在最大似然估计方法范畴内,也多种改进版本(如剖面最大似然估计方法、受限最大似然估计方法)以及各种对似然函数的重新定义。
3.1 似然函数
假设感兴趣的随机变量 Y Y Y f ( y ; θ ) f(y; \boldsymbol{\theta}) f ( y ; θ ) y \boldsymbol{y} y n n n y 1 , . . . , y n , y i ∈ R y_1, ..., y_n, y_i \in \mathbb{R} y 1 , ... , y n , y i ∈ R θ ∈ Θ \boldsymbol{\theta} \in \Theta θ ∈ Θ Ω \Omega Ω R d \mathbb{R}^d R d R d \mathbb{R}^d R d d d d y \boldsymbol{y} y θ \boldsymbol{\theta} θ
L ( θ ; y ) = c ( y ) f ( y ; θ ) ∝ f ( y ; θ ) (1) \mathcal{L}(\boldsymbol{\theta}; \boldsymbol{y}) = c(y) f(y;\boldsymbol{\theta}) \propto f(y;\boldsymbol{\theta}) \tag{1}
L ( θ ; y ) = c ( y ) f ( y ; θ ) ∝ f ( y ; θ ) ( 1 )
读者可能会比较常见到没有 c ( y ) c(y) c ( y ) 似然函数值之间仅在相对比较时有意义 。
出于计算稳定性考虑,通常不会直接使用似然函数,而是使用对数似然函数(有些文献中也称对数密度,但两者之间还是有一些区别的):
ℓ ( θ ; y ) = a ( y ) + log f ( y ; θ ) (2) \ell(\boldsymbol{\theta}; y) = a(y) + \log f (y; \boldsymbol{\theta}) \tag{2}
ℓ ( θ ; y ) = a ( y ) + log f ( y ; θ ) ( 2 )
特别是当 y \boldsymbol{y} y
1️⃣ 例 1 : 独立同分布的高斯似然
若 Y = ( Y 1 , … , Y n ) Y = (Y_1, \ldots, Y_n) Y = ( Y 1 , … , Y n ) μ μ μ σ 2 \sigma^2 σ 2 y i y_i y i Y i Y_i Y i
ℓ ( θ ; y ) = log ∏ i = 1 n p ( y i ) = ∑ i = 1 n log p ( y i ) = − n 2 log σ 2 − 1 2 σ 2 ∑ ( y i − μ ) 2 \ell(\boldsymbol{\theta}; \boldsymbol{y}) = \log \prod\limits^{n}_{i=1} p(y_i) = \sum\limits^{n}_{i=1} \log p(y_i) = − \frac{n}{2}\log \sigma^2 − \frac{1}{2\sigma^2} \sum (y_i − μ)^2
ℓ ( θ ; y ) = log i = 1 ∏ n p ( y i ) = i = 1 ∑ n log p ( y i ) = − 2 n log σ 2 − 2 σ 2 1 ∑ ( y i − μ ) 2
其中模型参数为 θ = ( μ , σ 2 ) \boldsymbol{\theta} = (μ, \sigma^2) θ = ( μ , σ 2 ) Θ = R × R + \Theta = \mathbb{R} \times \mathbb{R}^+ Θ = R × R + − ( n / 2 ) log ( 2 π ) −(n/2) \log (2\pi) − ( n /2 ) log ( 2 π )
2️⃣ 例 2 : 线性回归模型的高斯似然
上例可以推广到以条件分布建模为主的回归任务中。例如,我们可以假设 Y i Y_i Y i x \mathbf{x} x Y i Y_i Y i Y i Y_i Y i μ i \mu_i μ i μ i = x i T β \mu_i = x_i^T \beta μ i = x i T β
ℓ ( θ ; y , x ) = − n 2 log σ 2 − 1 2 σ 2 ∑ ( y i − x i T β ) 2 \ell(\boldsymbol{\theta}; \boldsymbol{y,x}) =− \frac{n}{2} \log \sigma^2 − \frac{1}{2\sigma^2} \sum (y_i − x_i^T\beta)^2
ℓ ( θ ; y , x ) = − 2 n log σ 2 − 2 σ 2 1 ∑ ( y i − x i T β ) 2
此时,模型参数由协变量系数 β \boldsymbol{\beta} β σ 2 \sigma^2 σ 2 θ = ( β , σ 2 ) \boldsymbol{\theta} = (\boldsymbol{\beta}, \sigma^2) θ = ( β , σ 2 )
3.2 最大似然估计
可以看出,似然函数是在数据和模型假设已知情况下,关于模型参数的函数。顾名思义,最大似然估计就是找到使似然最大化的参数值。
3.2.1 最大似然估计
(1)分值函数(Score function)
为了实现最大似然估计,根据函数的极值定理,通常会选择使对数似然的一阶(偏)导数为 0 0 0
s ( θ ) = ℓ ′ ( θ ) = ∂ ℓ ( θ ; y ) ∂ θ \mathcal{s}(\boldsymbol{\theta} ) = \ell^\prime (\boldsymbol{\theta}) = \frac{\partial \ell(\boldsymbol{\theta};\boldsymbol{y})}{\partial \boldsymbol{\theta}}
s ( θ ) = ℓ ′ ( θ ) = ∂ θ ∂ ℓ ( θ ; y )
这个一阶导数 s ( θ ) \mathcal{s}(\boldsymbol{\theta}) s ( θ )
(2)Fisher 信息量
分值函数 s ( θ ) \mathcal{s}(\boldsymbol{\theta}) s ( θ ) Fisher 信息量 :
I ( θ ) = E θ [ s ( θ ) ] 2 I(\boldsymbol{\theta})=E_{\boldsymbol{\theta}}\left[\mathcal{s}(\boldsymbol{\theta}) \right]^{2}
I ( θ ) = E θ [ s ( θ ) ] 2
如果对数似然存在二阶导数(满足二次可微条件)
j ( θ ^ ) = d 2 d θ 2 ∫ − ∞ + ∞ p ( y ; θ ) d y = ∫ − ∞ + ∞ ∂ 2 p ( y ; θ ) ∂ θ 2 d y j(\hat{\theta}) = \frac{\mathrm{d}^{2}}{\mathrm{d} \boldsymbol{\theta} ^{2}} \int_{-\infty}^{+\infty} p(y ; \boldsymbol{\theta} ) \mathrm{d} y=\int_{-\infty}^{+\infty} \frac{\partial^{2} p(y ; \boldsymbol{\theta} )}{\partial \boldsymbol{\theta} ^{2}} \mathrm{d} y
j ( θ ^ ) = d θ 2 d 2 ∫ − ∞ + ∞ p ( y ; θ ) d y = ∫ − ∞ + ∞ ∂ θ 2 ∂ 2 p ( y ; θ ) d y
则可以证明 Fisher 信息量是对数似然的负二阶导数关于所有样本的期望值:
I ( θ ) = E θ [ ∂ ∂ θ ln p ( y ; θ ) ] 2 ⇔ I ( θ ) = − E θ [ ∂ 2 ∂ θ 2 log p ( y ; θ ) ] I(\boldsymbol{\theta} )=E_{\boldsymbol{\theta} }\left[\frac{\partial}{\partial \boldsymbol{\theta} } \ln p(y ; \boldsymbol{\theta} )\right]^{2} \Leftrightarrow I(\boldsymbol{\theta} )=-E_{\boldsymbol{\theta}}\left[\frac{\partial^{2}}{\partial \boldsymbol{\theta}^{2}} \log p(y ; \boldsymbol{\theta})\right]
I ( θ ) = E θ [ ∂ θ ∂ ln p ( y ; θ ) ] 2 ⇔ I ( θ ) = − E θ [ ∂ θ 2 ∂ 2 log p ( y ; θ ) ]
根据定义,Fisher 信息量 I ( θ ) {I(\boldsymbol{\theta} )} I ( θ ) θ \boldsymbol{\theta} θ θ \boldsymbol{\theta} θ
分值函数与 Fisher 信息量的统计学意义
对于随机变量 Y Y Y θ \boldsymbol{\theta} θ f ( y ; θ ) f(\mathbf{y};\boldsymbol{\theta}) f ( y ; θ ) Y ∼ f ( y ; θ ^ ) Y \sim f(\mathbf{y};\hat{\boldsymbol{\theta}}) Y ∼ f ( y ; θ ^ ) θ ^ \hat{\boldsymbol{\theta}} θ ^ θ \boldsymbol{\theta} θ
假设分布具有一些正则性。想要研究的是 Y Y Y θ \boldsymbol{\theta} θ ∂ ∂ θ log f ( x ; θ ) \frac{\partial}{\partial \boldsymbol{\theta}}\log f(x;\boldsymbol{\theta}) ∂ θ ∂ log f ( x ; θ ) Fisher score function s ( θ ) \mathcal{s}(\boldsymbol{\theta}) s ( θ ) θ \boldsymbol{\theta} θ
我们第一个感兴趣的是 Fisher score 在 θ ^ \hat{\boldsymbol{\theta}} θ ^ 期望 。Fisher score 的期望描述了平均意义上 Y Y Y θ \boldsymbol{\theta} θ θ ^ \hat{\boldsymbol{\theta}} θ ^ 0 0 0
我们第二个感兴趣的东西是 Fisher score 在 θ ^ \hat{\boldsymbol{\theta}} θ ^ 方差 。Fisher score 的方差描述了平均意义上 Y Y Y θ \boldsymbol{\theta} θ Fisher 信息量 I ( θ ) \mathcal{I}(\boldsymbol{\theta}) I ( θ )
在满足二次可微的条件下(例如二次可微),Fisher 信息量可以用对数似然的二阶导数来描述,也就是 I ( θ ) = − E [ ∂ 2 ∂ θ 2 log f ( x ; θ ) ] \mathcal{I}(\boldsymbol{\theta}) = - \mathbb{E}[\frac{\partial^2}{\partial \boldsymbol{\theta}^2} \log f(x;\theta)] I ( θ ) = − E [ ∂ θ 2 ∂ 2 log f ( x ; θ )] θ \boldsymbol{\theta} θ 曲率 (导数的变化率)。该值越大则在 θ \boldsymbol{\theta} θ Y Y Y
对于 n n n 独立同分布 的随机变量 Y = { Y 1 , Y 2 , … , Y n } \mathbf{Y} = \{Y_1,Y_2,\dots,Y_n \} Y = { Y 1 , Y 2 , … , Y n } I ( θ ∣ Y 1 , … , Y n ) = n I ( θ ) \mathcal{I}(\boldsymbol{\theta} | Y_1,\dots,Y_n) = n \mathcal{I}(\boldsymbol{\theta} ) I ( θ ∣ Y 1 , … , Y n ) = n I ( θ ) n n n θ \boldsymbol{\theta} θ N ( θ ^ , I − 1 ( θ ^ ∣ Y 1 … , Y n ) ) \mathcal{N}(\hat{\theta},\mathcal{I}^{-1}(\hat\theta|Y_1\dots,Y_n)) N ( θ ^ , I − 1 ( θ ^ ∣ Y 1 … , Y n )) 渐进正态性 ,也就是:在样本数量趋于无穷时,最大似然估计的方差会逼近 Fisher 信息量的倒数。
在某些模型中,人们仅对模型参数 θ \boldsymbol{\theta} θ θ = ( ψ , λ ) \boldsymbol{\theta}=(\psi, \lambda) θ = ( ψ , λ ) ψ \psi ψ
I ( θ ) = ( I ψ ψ ( θ ) I ψ λ ( θ ) I λ ψ ( θ ) I λ λ ( θ ) ) . I(\theta)=\left(\begin{array}{cc}
I_{\psi \psi}(\theta) & I_{\psi \lambda}(\theta) \\
I_{\lambda \psi}(\theta) & I_{\lambda \lambda}(\theta)
\end{array}\right) .
I ( θ ) = ( I ψψ ( θ ) I λ ψ ( θ ) I ψ λ ( θ ) I λλ ( θ ) ) .
(3)渐进性质
在相当广泛的普遍性中,可以得出以下渐进收敛性质:
ℓ ′ ( θ ) T { j ( θ ^ ) } − 1 ℓ ′ ( θ ) → L χ d 2 ( θ ^ − θ ) T j ( θ ^ ) ( θ ^ − θ ) → L χ d 2 2 { ℓ ( θ ^ ) − ℓ ( θ ) } → L χ d 2 \begin{align*}
\ell^{\prime}(\theta)^T\{j(\hat{\theta})\}^{-1} \ell^{\prime}(\theta) & \stackrel{\mathcal{L}}{\rightarrow} & \chi_d^2 \tag{5}\\
(\hat{\theta}-\theta)^T j(\hat{\theta})(\hat{\theta}-\theta) & \stackrel{\mathcal{L}}{\rightarrow} & \chi_d^2 \tag{6}\\
2\{\ell(\hat{\theta})-\ell(\theta)\} & \stackrel{\mathcal{L}}{\rightarrow} & \chi_d^2 \tag{7}
\end{align*}
ℓ ′ ( θ ) T { j ( θ ^ ) } − 1 ℓ ′ ( θ ) ( θ ^ − θ ) T j ( θ ^ ) ( θ ^ − θ ) 2 { ℓ ( θ ^ ) − ℓ ( θ )} → L → L → L χ d 2 χ d 2 χ d 2 ( 5 ) ( 6 ) ( 7 )
其中取指样本数量 n n n ∞ \infty ∞ χ d 2 \chi_d^2 χ d 2 d d d d d d θ \boldsymbol{\theta} θ
获得此渐进结果的条件是:中心极限定理可被用于 Fisher 分值函数 ℓ ′ ( θ ; y ) \ell^\prime (\boldsymbol{\theta; y}) ℓ ′ ( θ ; y ) y \boldsymbol{y} y n n n
最大似然估计 θ ^ \hat{\boldsymbol{\theta}} θ ^ θ \boldsymbol{\theta} θ
3.2.2 剖面最大似然估计
如果令 λ ^ ψ \hat{\lambda}_\psi λ ^ ψ ψ \psi ψ λ \lambda λ ψ \psi ψ 剖面(profile)对数似然函数(或 concentrated 对数似然函数):
ℓ P ( ψ ) = sup λ ℓ ( ψ , λ ; y ) = ℓ ( ψ , λ ^ ψ ; y ) (8) \ell_{\mathrm{P}}(\psi) = \sup_\lambda \ell(\psi, \lambda; \boldsymbol{y}) = \ell \left(\psi, \hat{\lambda}_\psi ; \boldsymbol{y}\right) \tag{8}
ℓ P ( ψ ) = λ sup ℓ ( ψ , λ ; y ) = ℓ ( ψ , λ ^ ψ ; y ) ( 8 )
根据 式(7)的极限性质,有如下渐进性质:
ℓ P ′ ( ψ ) T j ψ ψ ( θ ^ ) ℓ P ′ ( ψ ) → L χ q 2 , ( ψ ^ − ψ ) T { j ψ ψ ( θ ^ ) } − 1 ( ψ ^ − ψ ) → L χ q 2 , 2 { ℓ ( ψ ^ , λ ^ ) − ℓ ( ψ , λ ^ ψ ) } → L χ q 2 , \begin{align*}
\ell_{\mathrm{P}}^{\prime}(\psi)^T j^\psi \psi(\hat{\theta}) \ell_{\mathrm{P}}^{\prime}(\psi) & \stackrel{\mathcal{L}}{\rightarrow} & \chi_q^2, \tag{9}\\
(\hat{\psi}-\psi)^T\left\{j^{\psi \psi}(\hat{\theta})\right\}^{-1}(\hat{\psi}-\psi) & \stackrel{\mathcal{L}}{\rightarrow} & \chi_q^2, \tag{10}\\
2\left\{\ell(\hat{\psi}, \hat{\lambda})-\ell\left(\psi, \hat{\lambda}_\psi\right)\right\} & \stackrel{\mathcal{L}}{\rightarrow} & \chi_q^2, \tag{11}
\end{align*}
ℓ P ′ ( ψ ) T j ψ ψ ( θ ^ ) ℓ P ′ ( ψ ) ( ψ ^ − ψ ) T { j ψψ ( θ ^ ) } − 1 ( ψ ^ − ψ ) 2 { ℓ ( ψ ^ , λ ^ ) − ℓ ( ψ , λ ^ ψ ) } → L → L → L χ q 2 , χ q 2 , χ q 2 , ( 9 ) ( 10 ) ( 11 )
其中 q q q ψ \psi ψ
上述渐进性质产生模型参数的例如下一阶近似,并在实践中被广泛用于对 θ \boldsymbol{\theta} θ
θ ^ ∼ N { θ , j − 1 ( θ ^ ) } , ψ ^ ∼ ˙ { ψ , j ψ ψ ( θ ^ ) } , ± 2 { ℓ ( ψ ^ , λ ^ ) − ℓ ( ψ , λ ^ ψ ) } ∼ ˙ N ( 0 , 1 ) , \begin{align*}
\hat{\theta} \sim \mathcal{N} \left\{\theta, j^{-1}(\hat{\theta})\right\}, \tag{12}\\
\hat{\psi} \dot{\sim}\left\{\psi, j^{\psi \psi}(\hat{\theta})\right\}, \tag{13} \\
\pm \sqrt{2}\left\{\ell(\hat{\psi}, \hat{\lambda})-\ell\left(\psi, \hat{\lambda}_\psi\right)\right\} \dot{\sim} \mathcal{N}(0,1), \tag{14}
\end{align*}
θ ^ ∼ N { θ , j − 1 ( θ ^ ) } , ψ ^ ∼ ˙ { ψ , j ψψ ( θ ^ ) } , ± 2 { ℓ ( ψ ^ , λ ^ ) − ℓ ( ψ , λ ^ ψ ) } ∼ ˙ N ( 0 , 1 ) , ( 12 ) ( 13 ) ( 14 )
大多数统计软件包都包含计算上述近似值的通用代码。其中第三个近似仅适用于 q = 1 q = 1 q = 1 sign ( ψ ^ − ψ ) \text{sign}(\hat{\psi} − \psi) sign ( ψ ^ − ψ )
3.3 贝叶斯估计
基于似然函数的贝叶斯推断原则上也非常简单:将 θ \boldsymbol{\theta} θ π ( θ ) \pi (\boldsymbol{\theta}) π ( θ ) L ( θ ; y ) \mathcal{L}(\boldsymbol{\theta}; \boldsymbol{y}) L ( θ ; y ) θ \boldsymbol{\theta} θ
π ( θ ∣ y ) = L ( θ ; y ) π ( θ ) ∫ L ( θ ; y ) π ( θ ) d θ (15) \pi(\boldsymbol{\theta} | y) = \frac{ \mathcal{L}(\boldsymbol{\theta}; y) \pi(\boldsymbol{\theta})}{ \int \mathcal{L}(\boldsymbol{\theta}; y)\pi(\boldsymbol{\theta})d\boldsymbol{\theta}} \tag{15}
π ( θ ∣ y ) = ∫ L ( θ ; y ) π ( θ ) d θ L ( θ ; y ) π ( θ ) ( 15 )
对感兴趣的部分参数 ψ ( θ ) \psi(\boldsymbol{\theta}) ψ ( θ ) ψ \psi ψ
π m ( ψ ∣ y ) = ∫ ψ ( θ ) = ψ π ( θ ∣ y ) d θ (16) \pi_m(\psi | \boldsymbol{y} ) = \int_{\psi(\boldsymbol{\theta})=\psi} \pi (\boldsymbol{\theta}|y)d\boldsymbol{\theta} \tag{16}
π m ( ψ ∣ y ) = ∫ ψ ( θ ) = ψ π ( θ ∣ y ) d θ ( 16 )
部分参数 ψ \psi ψ 均值或众数。边缘后验的概率性陈述也很容易获得,例如,概率为 ( 1 − α ) (1 − α) ( 1 − α ) ( ψ L , ψ U ) (\psi_L, \psi_U) ( ψ L , ψ U ) ψ L \psi_L ψ L ψ U \psi_U ψ U
∫ ψ = ψ L ψ = ψ U π m ( ψ ∣ y ) d ψ \int^{\psi = \psi_U}_{\psi = \psi_L} \pi_m(\psi | y)d\psi
∫ ψ = ψ L ψ = ψ U π m ( ψ ∣ y ) d ψ
仅上述条件形成的区间并不唯一,通常推荐的一种选择是同时要求 区间具有最高的后验密度 ,相应的区间被称为最高后验密度区间(HPDI)。
事实上,式 (15) 和 式 (16) 所需的积分计算比较复杂,因此大多只能通过数值方法给出近似解。
当维度较低时,可以采用 拉普拉斯近似法 或 求积法则。
在高维情况下,可以采用 马尔可夫链蒙特卡罗 (MCMC) 方法,先从后验密度中采样,通过样本做计算。根据 MCMC 原理,需要构建一条以后验密度 π ( θ ∣ θ ) \pi (\boldsymbol{\theta} | \boldsymbol{\theta}) π ( θ ∣ θ )
在贝叶斯方法的大多数科学应用中,了解推断结果在某个固定参数 θ 0 \boldsymbol{\theta}_0 θ 0 p ( y ∣ θ 0 ) p(y|\boldsymbol{\theta}_0) p ( y ∣ θ 0 ) ψ \psi ψ
在模型和先验给定的条件下,可以证明 θ − θ ^ \boldsymbol{\theta} − \hat{\boldsymbol{\theta}} θ − θ ^ 0 0 0
4 MLE 数值算法
在常规模型中,最大似然估计结果来自于分值函数等于 0 时的解:
ℓ ′ ( θ ; y ) = 0 \ell^\prime (\boldsymbol{\theta; y}) = 0
ℓ ′ ( θ ; y ) = 0
通常使用 Newton-Raphson、梯度下降 、EM 算法 等方法迭代求解方程。
(1)Newton-Raphson 算法
前面提到的 Fisher 评分方法使用了 Newton-Raphson,不过将 Newton-Raphson 中的二阶导数替换为其期望值。当方程存在多个根时,理论上可以通过找到所有根并选择似然最大的那个根作为最终的最大似然估计。
(2)梯度下降算法
在广义线性模型(GLM)中,模型通常具有足够的平滑度来确保分值函数具有唯一解,并可以通过迭代地 加权最小二乘拟合 来找到该解。这使得用对数似然函数代替平方误差后,许多线性回归技术可以扩展到非线性模型。
【示例 5 】
假设响应 Y i Y_i Y i n i n_i n i p i p_i p i k k k
ℓ ( p ) = ∑ i = 1 k { y i log ( p i ) + ( n i − y i ) log ( 1 − p i ) } \ell(p) = \sum^k_{i=1} \{y_i \log (p_i) + (n_i − y_i) \log (1− p_i) \}
ℓ ( p ) = i = 1 ∑ k { y i log ( p i ) + ( n i − y i ) log ( 1 − p i )}
由于没有进一步的信息来链接观测结果,p p p ( y 1 / n 1 , . . . , y k / n k ) (y_1/n_1, ..., y_k/n_k) ( y 1 / n 1 , ... , y k / n k ) x i 1 , … , x i q x_{i1}, \ldots, x_{iq} x i 1 , … , x i q y i y_i y i p p p
log p i 1 − p i = x i T β , \log \frac{p_i}{1 − p_i} = x_i^T\beta,
log 1 − p i p i = x i T β ,
这使得
ℓ ( β ) = ∑ i = 1 k y i x i T β − n i log { 1 + exp ( x i T β ) } \ell(β) = \sum^k_{i=1} y_i x_i^T \beta − n_i \log \{1 + \exp (x_i^T \beta)\}
ℓ ( β ) = i = 1 ∑ k y i x i T β − n i log { 1 + exp ( x i T β )}
分值函数为:
∑ ( y i / n i ) x i T = ∑ p i ( β ) x i T \sum(y_i/n_i) x_i^T = \sum p_i(β) x_i^T
∑ ( y i / n i ) x i T = ∑ p i ( β ) x i T
其中 p i ( β ) = exp ( x i T β ) / { 1 + exp ( x i T β ) } p_i(β) = \exp (x_i^T \beta)/\{1 + \exp (x_i^T \beta)\} p i ( β ) = exp ( x i T β ) / { 1 + exp ( x i T β )} β β β β β β n i = 1 n_i = 1 n i = 1 [14]
【示例 6 】
在具有一个隐藏层的前馈神经网络中,该模型可以表示为非线性回归模型 [2]
Y i ∼ Bin ( n i , p i ) log p i 1 − p i = β 0 + Z i T β Z i m = exp ( x i T α m ) 1 + exp ( x i T α m ) \begin{align*}
Y_i &\sim \text{Bin}(n_i, p_i)\\
\log \frac{p_i}{1-p_i} &= \beta_0 + Z_i^T \beta\\
Z_{im} &= \frac{\exp (x_i^T α_m) }{1 + \exp (x_i^T α_m)}
\end{align*}
Y i log 1 − p i p i Z im ∼ Bin ( n i , p i ) = β 0 + Z i T β = 1 + exp ( x i T α m ) exp ( x i T α m )
其中 Z Z Z [14]
(3)期望最大化算法
Dempster 等 [15] [6] [16] [17]
期望最大化(EM) 算法从形式上看,与 第 3.2 节 中的剖面最大似然估计极为相似,似乎都是先给出部分参数的估计值,而后再通过最大似然法估计剩余参数的值。但两者之间事实上存在着截然不同的本质和意义。其中最大的不同在于建模场景和模型假设,EM 算法的 E 步骤给出的是隐变量的期望值,而非参数的估计值。也就是说,EM 算法将 E 步骤估计的变量视为一个感兴趣的隐变量,而非模型参数。隐变量与模型参数之间的最大区别在于:隐变量往往每个样本有一个估计值,因此也可以被称为局部估计量;而模型参数是全局性的,所有样本共享相同的估计值 。
具体来说,在机器学习的很多现实应用中,人们经常会发现一些相关的特征,但其中只有部分可观测,其余特征不可观测(例如:可以听到来自多个音箱的声音,但无法观测到具体是哪个音箱参与了声音)。当所有特征都可观测时,我们通过建模并简单采用 第 3 节 中给出的推断方法,基本就能获得最优参数值;但当存在具有局部性质的隐变量时,问题会变得非常复杂。此时最常用的推断方法是期望最大化算法,该算法需要预设隐变量的参数化概率分布形式,并通过最大似然估计获取该概率分布参数的值。 一个常见的隐变量模型是高斯混合模型:
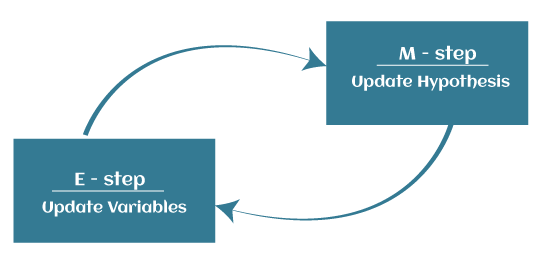
EM 算法作为一种迭代方法,它由两种模式组成。在第一种模式中,估计缺失变量或隐变量,因此被称为期望估计步骤(Expectation/estimation step)或 E 步。另一种模式用于优化模型参数,使其能够更清楚地解释数据,因此被称为最大化步骤(maximization-step )或 M 步。
EM 算法的 4 个步骤:
第一步,初始化参数值 。系统提供了不完整的观测数据,并假设数据来自特定模型。第二步:E-步 ,使用已观测数据来估计或猜测隐变量(或缺失数据)的值,也就是说,E-步主要用于更新隐变量。第三步:M 步 ,使用从第二步获得的完整数据来更新模型参数值。也就是说,M-步主要用于更新模型假设。第四步:检查隐变量值的收敛性 。如果收敛则停止算法,否则继续从 步骤 2 开始重复,直至收敛。
5 受限最大似然估计
重新审视 式 (9)、式(10) 和 式 (11) 中给出的剖面最大似然估计。直观上很明显,剖面对数似然过于聚集在其最大值点 ψ ^ \hat{\psi} ψ ^ λ \lambda λ ℓ P \ell_P ℓ P ψ ^ \hat{\psi} ψ ^ ψ ^ \hat{\psi} ψ ^
示例 3
如果模型是 y i = x i T β + ϵ i y_i = x_i^T \beta + \epsilon_i y i = x i T β + ϵ i x i x_i x i q × 1 q × 1 q × 1 ϵ i \epsilon_i ϵ i N ( 0 , ψ ) N(0, \psi) N ( 0 , ψ ) ψ \psi ψ
ψ ^ = 1 n ∑ ( y i − x i T β ^ ) 2 (18) \hat{\psi} = \frac{1}{n} \sum (y_i − x_i^T \hat{β})^2 \tag{18}
ψ ^ = n 1 ∑ ( y i − x i T β ^ ) 2 ( 18 )
它往往太小,因为它不允许 q q q β β β ( β , ψ ) (β, \psi) ( β , ψ )
L 1 ( β , ψ ; y ˉ ) L 2 ( ψ ; ∑ ( y i − x i T β ^ ) 2 ) (19) L_1 (β, \psi; \bar{y}) L_2 \left(\psi; \sum (y_i − x_i^T \hat{β})^2 \right) \tag{19}
L 1 ( β , ψ ; y ˉ ) L 2 ( ψ ; ∑ ( y i − x i T β ^ ) 2 ) ( 19 )
因子 L 2 ( ψ ) L_2(\psi) L 2 ( ψ ) ∑ ( y i − x i T β ^ ) 2 \sum(y_i − x_i^T \hat{\beta})^2 ∑ ( y i − x i T β ^ ) 2 ψ \psi ψ ψ \psi ψ
ψ ^ m = 1 n − q ∑ ( y i − x i T β ^ ) 2 (20) \hat{\psi}_m = \frac{1}{n − q} \sum (y_i − x_i^T \hat{\beta})^2 \tag{20}
ψ ^ m = n − q 1 ∑ ( y i − x i T β ^ ) 2 ( 20 )
基于残差边缘似然的估计通常称为受限最大似然 (REML) 估计,REML 方法在估计具有随机效应的线性模型中的方差分量时尤为重要。参考文献 [20]
高阶近似理论已被用于推导对剖面似然或剖面对数似然函数的一般调整,其形式为:
ℓ A ( ψ ) = ℓ P ( ψ ) + 1 2 log ∣ J λ λ ( ψ , λ ^ ψ ) ∣ + B ( ψ ) (21) \ell_A(\psi) = \ell_P(\psi) + \frac{1}{2} \log |J_{\lambda\lambda}(\psi, \hat{\lambda}_\psi)| + B(\psi) \tag{21}
ℓ A ( ψ ) = ℓ P ( ψ ) + 2 1 log ∣ J λλ ( ψ , λ ^ ψ ) ∣ + B ( ψ ) ( 21 )
其中 J λ λ J_{\lambda\lambda} J λλ B ( ψ ) B(\psi) B ( ψ ) O p ( 1 ) \mathcal{O}_p(1) O p ( 1 ) B ( ψ ) B(\psi) B ( ψ ) λ \lambda λ [21] B ( ψ ) B(\psi) B ( ψ ) [22] [23]
在 ψ \psi ψ λ \lambda λ I ψ λ ( θ ) = 0 I_{\psi\lambda}(\boldsymbol{\theta}) = 0 I ψ λ ( θ ) = 0 ℓ A ( ψ ) \ell_A(\psi) ℓ A ( ψ )
ℓ C R ( ψ ) = ℓ P ( ψ ) − 1 2 log ∣ J λ λ ( ψ , λ ^ ψ ) ∣ (22) \ell_{CR}(\psi) = \ell_P(\psi) − \frac{1}{2} \log |J_{\lambda\lambda}(\psi, \hat{\lambda}_\psi)| \tag{22}
ℓ CR ( ψ ) = ℓ P ( ψ ) − 2 1 log ∣ J λλ ( ψ , λ ^ ψ ) ∣ ( 22 )
该式由 Cox 和 Reid 引入 [24] log ∣ J λ λ ∣ \log |J_{\lambda\lambda}| log ∣ J λλ ∣ ℓ P ( ψ ) \ell_P(\psi) ℓ P ( ψ ) O p ( n ) \mathcal{O}_p(n) O p ( n ) n n n log ∣ J λ λ ∣ \log |J_{\lambda\lambda}| log ∣ J λλ ∣ O p ( 1 ) \mathcal{O}_p(1) O p ( 1 ) ℓ C R \ell_{CR} ℓ CR λ \lambda λ ψ \psi ψ ℓ A ( ψ ) \ell_A(\psi) ℓ A ( ψ ) θ = ( ψ , λ ) \boldsymbol{\theta}=(\psi,\lambda) θ = ( ψ , λ ) θ ~ = { ψ , η ( ψ , λ ) } \tilde{\boldsymbol{\theta}} =\{\psi, η(\psi, \lambda)\} θ ~ = { ψ , η ( ψ , λ )} [25] [26] ℓ A ( ⋅ ) \ell_A(·) ℓ A ( ⋅ ) B ( ⋅ ) B(·) B ( ⋅ )
从参考文献 [27] [28] [29] [30] [31] [8] [8] [32] [33] [34]
6 似然函数的常见变体
除了直接使用似然函数作为目标函数之外,还有大量根据不同目的提出的改进似然函数。其中常见的有:偏似然、近似似然(组合似然)、准似然、经验似然等。
6.1 偏似然
类似然函数扩展中最重要的一类,是删失生存数据的 偏似然(partial likelihoods [35] [36]
【示例 6 】
假设我们对 n n n y i y_i y i y i y_i y i 示例 4 的非齐次泊松过程密切相关的模型,是假设第 i i i
λ ( t i ) = exp ( x i T β ) λ 0 ( t i ) (23) λ(t_i) = \exp (x_i^T \beta) λ_0(t_i) \tag{23}
λ ( t i ) = exp ( x i T β ) λ 0 ( t i ) ( 23 )
其中 x i x_i x i λ 0 ( t ) λ_0(t) λ 0 ( t ) k k k y ( 1 ) < ⋅ ⋅ ⋅ < y ( k ) y(1) < ··· < y(k) y ( 1 ) < ⋅⋅⋅ < y ( k ) R i \mathcal{R}_i R i y ( i ) y_{(i)} y ( i ) y y y y ( i ) y_{(i)} y ( i ) [35] β β β
∏ i = 1 k exp ( x ( i ) T β ) ∑ j ∈ R i exp ( x j T β ) \prod^k_{i=1} \frac{\exp (x_{(i)}^T β)}{\sum_{j \in \mathcal{R}_i} \exp (x_j^T β)}
i = 1 ∏ k ∑ j ∈ R i exp ( x j T β ) exp ( x ( i ) T β )
其中 x ( i ) x_{(i)} x ( i ) y ( i ) y_{(i)} y ( i )
模型 (23) 是一个半参数模型,此类模型的一般似然理论可通过参考文献 [36] [38]
6.2 近似似然与组合似然
许多其他类似然函数可以仅使用部分数据的密度来构造。 Besag [39] 伪似然函数(pseudo-likelihood function) 概念,伪似然由每个数据点的条件密度相乘得到,而每个数据点的条件密度则均以其直接邻居为条件。在 Lindsay 之后,这通常代表一大类被称为 组合似然(composite likelihoods) 的似然 [40]
【示例 8 】
对相关的二值数据建模的一种方法,是从不可观测的隐变量建模开始,例如,
z i r = x i r T β + w i r T b i + ϵ i r b i ∼ N ( 0 , Σ b ) ϵ i r ∼ N ( 0 , 1 ) \begin{align*}
z_{ir} &= x_{ir}^T β + w_{ir}^T b_i + \epsilon_{ir}\\
b_i &\sim N(0, \Sigma_b)\\
\epsilon_{ir} &\sim N(0, 1)
\end{align*}
z i r b i ϵ i r = x i r T β + w i r T b i + ϵ i r ∼ N ( 0 , Σ b ) ∼ N ( 0 , 1 )
其中 r = 1 , . . . , n i r = 1, ..., n_i r = 1 , ... , n i i = 1 , . . . , n i = 1, ..., n i = 1 , ... , n n n n n i n_i n i x i r x_{ir} x i r w i r w_{ir} w i r i i i r r r y i r = 1 y_{ir} = 1 y i r = 1 z i r ≥ 0 z_{ir} ≥ 0 z i r ≥ 0 y \boldsymbol{y} y
L ( θ ; y ) = ∏ i = 1 n log ∫ − ∞ ∞ ∏ r = 1 n i p i r y i r ( 1 − p i r ) 1 − y i r ϕ ( b i , Σ b ) d b i \mathcal{L}(\boldsymbol{\theta; y}) = \prod^n_{i=1} \log \int^\infty_{-\infty} \prod^{n_i}_{r=1} p^{y_{ir}}_{ir} (1 − p_{ir})^{1−y_{ir}} \phi (b_i, \Sigma_b)d b_i
L ( θ ; y ) = i = 1 ∏ n log ∫ − ∞ ∞ r = 1 ∏ n i p i r y i r ( 1 − p i r ) 1 − y i r ϕ ( b i , Σ b ) d b i
其中 p i r = Φ ( x i r T β + w i r T b i ) p_{ir} = \Phi(x_{ir}^T β + w_{ir}^T b_i) p i r = Φ ( x i r T β + w i r T b i ) Φ ( ⋅ ) \Phi(·) Φ ( ⋅ ) ϕ ( ⋅ ; μ , Σ ) \phi(·;μ,\Sigma) ϕ ( ⋅; μ , Σ ) μ μ μ Σ \Sigma Σ b i b_i b i [41] 成对似然(pairwise likelihoods),成对似然可以被视为组合似然的一个例子。 Renard 等 [41] [42]
6.3 准似然
用基于似然的方法分析复杂数据,还有一种稍微有些不同的方法,那就是 Wedderburn 的准似然(quasi-likelihood) [43]
E ( y i ∣ x i ) = μ ( x i T β ) V a r ( y i ∣ x i ) = φ V ( μ i ) \begin{align*}
\mathbb{E}(y_i | x_i) &= μ(x_i^T \beta)\\
\mathbb{V}ar(y_i | x_i) &= \varphi V(\mu_i)
\end{align*}
E ( y i ∣ x i ) V a r ( y i ∣ x i ) = μ ( x i T β ) = φ V ( μ i )
其中 μ ( ⋅ ) μ(·) μ ( ⋅ ) V ( ⋅ ) V(·) V ( ⋅ ) φ \varphi φ β β β
∑ i = 1 n V ( μ i ) − 1 / 2 ( y i − μ ( x i T β ) ) = 0 \sum^n_{i=1} V(\mu_i)^{−1/2} \left(y_i − μ(x_i^T \beta) \right) = 0
i = 1 ∑ n V ( μ i ) − 1/2 ( y i − μ ( x i T β ) ) = 0
如果该模型存在,上式将对应于具有二阶矩的广义线性模型的得分方程。
准似然推断理论由 McCullagh 提出 [44] [45] V ( ⋅ ) V(·) V ( ⋅ )
如果均值函数是用固定效应和随机效应建模的,如 示例 8 所示,那么这种准似然法也会涉及到积分计算。 Breslow 和 Clayton [46] 带惩罚准似然版本。 Green [47] i i i
θ i = x i T β + m ( w i ) \boldsymbol{\theta}_i = x_i^T \beta + m(w_i)
θ i = x i T β + m ( w i )
m ( ⋅ ) m(·) m ( ⋅ ) [48] [49]
6.4 经验似然
Owen [50] 经验似然(empirical likelihood) 的非参数似然。
在最简单的情况下,y 1 , … , y n y_1, \ldots, y_n y 1 , … , y n f f f 1 / n 1/n 1/ n f f f μ μ μ
∏ i = 1 n p i ,subject to ∑ p i y i = μ , and ∑ p i = 1 \prod^n_{i=1} p_i \text{,subject to } \sum p_i y_i = μ \text{ , and } \sum p_i = 1
i = 1 ∏ n p i ,subject to ∑ p i y i = μ , and ∑ p i = 1
经验似然允许在非参数设置中使用基于似然的参数。自 Owen 的原始论文以来,它已得到相当大的扩展和概括,例如,参见参考文献 [51]
在 Owen 的 [50]
非参数似然推断的另一个版本是使用参数为函数的 类似然参数(likelihood-like arguments)。例如,从一个此类密度的独立样本中,对对数凹密度的最大似然估计。这方面的理论要复杂得多:有关此类估计量一致性的最新结果,请参阅参考文献 [52] 示例 7 的比例风险模型,参考文献 [53]
7 结论
似然函数以及其派生的量是所有基于数学建模的统计推断方法的基础。基于似然函数派生出的各种量为未知参数估计、不确定性估计、假设检验、模型选择提供了方法。此外,为解决应用中出现的特定复杂模型,人们也发展出了大量似然的扩展,证明了似然和基于似然的思想在统计推断中的核心作用。
参考文献
[1] Wood S. Generalized Additive Models: An Introduction with R.NewYork:Chapman&Hall/CRC;2006. [2] Hastie T, Tibshirani RJ, Friedman J. The Elements of Statistical Learning.2nded.NewYork:SpringerVerlag; 2009. [3] Fisher RA. Statistical Methods and Scientific Inference. Edinburgh: Oliver & Boyd; 1956. [4] Edwards AF. Likelihood (Expanded Edition).Baltimore: Johns Hopkins University Press; 1992. [5] Azzalini A. Statistical Inference.London:Chapman &Hall;1998. [6] Davison AC. Statistical Models.Cambridge:Cambridge University Press; 2003. [7] Cox DR, Hinkley DV. Theoretical Statistics.London: Chapman & Hall; 1974. [8] Barndorff-Nielsen OE, Cox DR. Inference and Asymptotics.London:Chapman&Hall;1994. [9] Casella G, Robert CP. Monte Carlo Statistical Methods. New York: Springer-Verlag; 1999. [10] Gilks WR, Richardson S, Spiegelhalter D. Markov Chain Monte Carlo in Practice.NewYork:Chapman &Hall/CRC;1996. [11] Berger JO. Statistical Decision Theory and Bayesian Analysis.NewYork:Springer-Verlag;1985. [12] Berger JO. The case for objective Bayes analysis. Bayesian Stat 2006, 1:385–402, doi:10.1214/06BA115. [13] Goldstein M. Subjective Bayesian analysis: principles and practice. Bayesian Stat 2006, 1:403–420, doi:10.1214/06-BA116. [14] Venables WN, Ripley BD. Modern Applied Statistics with S.NewYork:Springer-Verlag;2003. [15] Dempster A, Laird N, Rubin D. Maximum likelihood from incomplete data via the EM algorithm. JRStat Soc B 1977, 39:1–38. [16] Little RJA, Rubin DB. Statistical Analysis with Missing Data.2nded.NewYork:JohnWiley&Sons;2002. [17] McLachlan GJ, Krishnan T. The EM Algorithm and Extensions.NewYork:JohnWiley&Sons;2007. [18] Claeskens G, Hjort NL. Model Selection and Model Averaging.Cambridge:CambridgeUniversityPress; 2008. [19] Kass RE, Wasserman L. Formal rules for selecting prior distributions: a review andannotatedbibliography.J Am Stat Assoc 1996, 91:1343–1370. [20] Searle SR, Casella G, McCulloch CE. Variance Components.NewYork:JohnWiley&Sons;1992. [21] Fraser DAS. Inference and Linear Models.NewYork: McGraw-Hill; 1979. [22] Barndorff-Nielsen OE. On a formula for the distribution of the maximum likelihood estimator. Biometrika 1983, 70:343–365. [23] Fraser DAS. Likelihood for component parameters. Biometrika 2003, 90:327–339. [24] Cox DR, Reid N. Parameter orthogonality and approximate conditional inference (with discussion). JRStat Soc B 1987, 49:1–39. [25] Diciccio TJ, Martin MA, Stern SE, Young GA. Information bias and adjusted profile likelihoods. JRStat Soc B 1996, 58:189–203. [26] Chang H, Mukerjee R. Probability matching property of adjusted likelihoods. Stat Probab Lett 2006, 76:838 – 842. [27] Barndorff-Nielsen OE. Conditionality resolutions. Biometrika 1980, 67:293–310. [28] Cox DR. Local ancillarity. Biometrika 1980, 67:279 – 286. [29] Durbin J. Approximations for densities of sufficient statistics. Biometrika 1980, 67:311–333. [30] Hinkley DV. Likelihood as approximate pivotal. Biometrika 1980, 67:287–292. [31] Daniels HE. Saddlepoint approximations in statistics. Ann Math Stat 1954, 46:631–650. [32] Pace L, Salvan A. Principles of Statistical Inference: From a Neo-Fisherian Perspective.Singapore:World Scientific; 1997. [33] Severini TA. Likelihood Methods in Statistics.Oxford: Oxford University Press; 2001. [34] Brazzale AR, Davison AC, Reid N. Applied Asymptotics.Cambridge:CambridgeUniversityPress;2007. [35] Cox DR. Regression models and life tables (with discussion). JRStatSocB1972, 34:187–220. [36] Cox DR. Partial likelihood. Biometrika 1975, 62:269 – 276. [37] Murphy SA, van der Vaart AW. On profile likelihood (with discussion). JAmStatAssoc2000, 95:449–485. [38] Murphy SA, van der Vaart AW. Semiparametric likelihood ratio inference. Ann Stat 1997, 25:1471–1509. [39] Besag JE. Spatial interaction and the statistical analysis of lattice systems (with discussion). JRStatSocB1974, 34:192 – 236. [40] Lindsay BG. Composite likelihood methods. Contemp Math 1988, 80:220–239. [41] Renard D, Molenberghs G, Geys H. A pairwise likelihood approach to estimation in multilevel probit models. Comput Stat Data Anal 2004, 44:649–667. [42] Varin C. On composite marginal likelihoods. Adv Stat Anal 2008, 92:1–28. [43] Wedderburn RWM. Quasi-likelihood functions, generalized linear models, and the Gauss–Newton method. Biometrika 1974, 61:439–447. [44] McCullagh P. Quasi-likelihood functions. Ann Stat 1983, 11:59–67. [45] Liang K-Y, Zeger S. Longitudinal data analysis using generalized linear models. Biometrika 1986, 73:13–22. [46] Breslow N, Clayton D. Approximate inference in generalized linear mixed models. JAmStatAssoc1993, 88:9 – 25. [47] Green PJ. Penalized likelihood for general semiparametric regression models. Int Statist Rev 1987, 55:245 – 259. [48] Lee Y, Nelder JA. Hierarchical generalised linear models: a synthesis of generalised linear models, randomeffect models and structured dispersions. Biometrika 2001, 88:987–1006. [49] Nelder JA, Lee Y. Likelihood, quasi-likelihood and pseudolikelihood: some comparisons. JRStatSocB 1992, 54:273–284. [50] Owen AB. Empirical likelihood ratio confidence intervals for a single functional. Biometrika 1988, 75:237 – 249. [51] Hjort NL, McKeague IW, van Keilegom I. Extending the scope of empirical likelihood. Ann Stat 2009, 37:1079 – 1111. [52] Balabdaoui F, Rufibach K, Wellner JA. Limit distribution theory for maximum likelihood estimation of a log-concave density. Ann Stat 2009, 37:1299–1331. [53] van der Vaart AW. Asymptotic Statistics. Cambridge: Cambridge University Press; 1998.