附录 H:模型集成
Contents
附录 H:模型集成¶
【摘要】贝叶斯模型平均(贝叶斯模型平均) 提供了一种连贯且系统的机制来解释模型的不确定性。它可以看作是贝叶斯推理在模型选择、组合估计和预测问题上的直接应用。贝叶斯模型平均产生了一个简单的模型选择标准和风险较低的预测。然而,贝叶斯模型平均的应用并不总是直截了当的,导致对其不同方面的不同假设和情境选择。
【原文】Joseph Rocca; Ensemble methods: bagging, boosting and stacking Understanding the key concepts of ensemble learning; Apr 23, 2019
1 为什么做模型集成?¶
已经了解了机器学习中的多种分类和回归模型。那现在有一个问题就是,哪一个模型最好呢?以分类任务为例,当拿到一个需要进行分类的任务时,如果是你你会选择哪种模型进行建模呢?一个狡猾的办法就是挨个都试一下,那这样做有没有道理呢?还别说,在实际的情况中真的可能会都去试一下,因为在没有实验之前谁都不会知道真正的结果。假如现在对A、C、D这三个模型进行建模,最后得到结果是:A的分类准确率为0.93,B的分类准确率为0.95,C的准确率为0.88。那最终应该选择哪一个模型呢?是模型B吗?
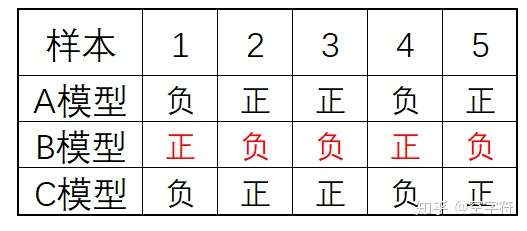
假设一共有100个数据样本,数据标签为二分类(正、负两类),如图所示为三个模型的部分分类结果。其中图示中的5个样本,模型A和C均能分类正确,而模型B不能分类正确。如果此时将这三个模型一起用于分类任务的预测,并且对于每一个样本的最终输出结果采用基于投票的规则在三个模型的输出结果中进行选择。例如图示中的第1个样本,模型A和C均判定为“负类”只有B判定为“正类“,则最后的输出便为”负类“。那么此时,就有可能得到一个分类准确率为1的“混合”模型。
注:在其余的95个样本中,假设根据投票规则均能分类正确
2 监督分类任务中的主要集成学习方法¶
在机器学习中,基于这种组合思想来提高模型精度的方法被称为集成学习(ensemble learning)。俗话说”三个臭皮匠,赛过诸葛亮“,这句话完美的阐述了集成学习的潜在思想——通过将多个弱的模型结合在一起来提高最终结果的预测精度。
常见的集成模型主要包括以下三种:
装袋法(
Bagging): 装袋法的核心思想为并行地训练一组各自独立的同质弱学习器,然后按照某种确定性平均过程将他们组合起来(例如:分类中的投票策略,回归中的平均策略)。提升法(
Boosting):提升法的核心思想为串行地训练一组前后适应性的同构弱学习器,然后按照某种确定性策略组合它们。此处『适应性』指用后一个模型来对前一个模型的输出进行纠正。堆叠法(
Stacking):Stacking的核心思想为并行地训练一组各自独立的异构弱学习器,然后通过训练一个元模型(meta-model)来将各弱学习器组合起来。
我们可以粗略地说装袋法主要专注于获得方差小于其组件的集成模型(过拟合场景);而提升法和堆叠法主要尝试生成比其组件偏差更少的强模型(欠拟合场景)。

可以组合弱学习器以获得性能更好的模型。组合基础模型的方式应该适应它们的类型。低偏差和高方差弱模型应该以一种使强模型更健壮的方式组合,而低方差和高偏差基础模型最好以一种使集成模型更少偏差的方式组合。
2.1 装袋法( Bagging )¶
装袋法( Bagging )的全称为 自举/聚合( bootstrap aggregation ),这两个单词分别代表了装袋法在执行过程中的两个步骤:① 自举样本(bootstrap samples);② 聚合输出( aggregate outputs)。也就是装袋法首先从原始数据集中随机抽取多组包含若干数量样本点的子训练集;然后基于这些子训练集分别得到不同的基模型;最后对各基模型预测的结果进行聚合输出。
其中 \(M\) 表示基模型的数量,\(f_m(x)\) 表示不同的基模型。

由于装袋法的策略是取所有基模型的”平均“值作为最终模型的输出结果,因此能够很好的降低模型的高方差(过拟合)状况。通常在使用装袋法时,尽量使每个基模型都出现过拟合的现象。
(1) sklearn 中的装袋法
下面以 sklearn 中实现的BaggingClassifier为例,并对其中的参数进行简单的说明一下。在 sklearn 中,可以通过from sklearn.ensemble import BaggingClassifier来导入 bagging 集成方法。
def __init__(self,
base_estimator=None,
n_estimators=10,
max_samples=1.0,
max_features=1.0,
bootstrap=True,
bootstrap_features=False,
n_jobs=None,
verbose=0):
Input In [1]
verbose=0):
^
SyntaxError: unexpected EOF while parsing
上面的初始化函数是类BaggingClassifier中的一部分参数,其中base_estimator 表示所使用的基模型;n_estimators 表示需要同时训练多少个基模型;max_samples 表示每个子训练集中最大的样本数量;max_features 表示子训练集的最大特征维度(由于是随机抽样,所以不同的子训练集特征维度可能不一样); bootstrap=True 表示在每个子训练集中同一个样本可以重复出现;bootstrap_features=False 表示在每个子训练集中每个特征维度不能重复出现(如果设置为 True ,极端情况下所有的特征维度可能都一样)。
如下代码所示为以 KNN 作为基模型进行装袋法集成的示例用法:
if __name__ == '__main__':
x_train, x_test, y_train, y_test = load_data()
bagging = BaggingClassifier(KNeighborsClassifier(n_neighbors=3),
n_estimators=5,
max_samples=50,
max_features=3,
bootstrap=True,
bootstrap_features=False)
bagging.fit(x_train, y_train)
print(bagging.estimators_features_)
print(bagging.score(x_train, y_train))
print(bagging.score(x_test, y_test))
(2) 随机森林
正如上面说到,在装袋法方法进行模型集成的时候,基模型可以是任意模型,自然而然也也可以是决策树了。由于对决策树使用装袋法方法是一个较为受欢迎的研究方向,因此也给它取了另外一个名字随机森林(random forests)。根据装袋法的思想来看,随机森林这个名字也很贴切,一系列的树模型就变成了森林。因此在 sklearn 中,如果是通过BaggingClassifier来实现装袋法集成,当 base_estimator=None 时,默认就会采用决策树作为基模型。
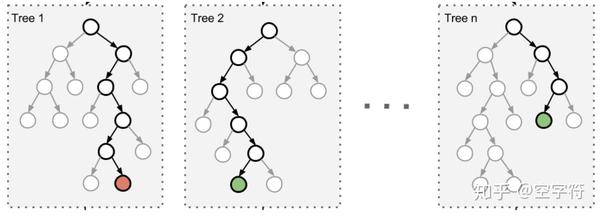

上图为随机采样后生成的若干决策树模型,可以看到,在不同子样本集中训练的决策树中,同一个样本所归属的节点不同,甚至连类别也可能不同。这充分体现了集成模型的优点,通过 『平均』 来降低误差。如下所示代码为基于决策树的装袋法集成方法在 sklearn 中的两种实现方式:
from `sklearn` .ensemble import BaggingClassifier,RandomForestClassifier
from `sklearn` .tree import DecisionTreeClassifier
if __name__ == '__main__':
x_train, x_test, y_train, y_test = load_data()
# 使用装袋分类器
bagging = BaggingClassifier(n_estimators=5,
max_samples=50,
max_features=3,
bootstrap=True,
bootstrap_features=False)
bagging.fit(x_train, y_train)
print(bagging.score(x_test, y_test))
# 直接使用随机森林分类器
rfc = RandomForestClassifier(n_estimators=5)
rfc.fit(x_train,y_train)
print(rfc.score(x_test,y_test))
2.2 提升法(Boosting )¶
提升法同装袋法一样,都用于提高模型的泛化能力。不同的是:提升法通过训练一系列串行的模型来达到这一目的。在提升法的一些串行的基模型中,每个基模型都是对前一个基模型输出结果的改善。如果前一个基模型对某些样本进行了错误分类,那么后一个基模型就会针对该错误结果做改善。在经过一系列串行的基模型拟合之后,最终会得到一个更加准确的结果。因此,提升法经常被用于改善模型高偏差的情况(欠拟合现象)。
提升法的工作原理与装袋法相同:构建一系列基模型,然后将这些基模型聚合在一起以获得性能更好的强学习器。然而,与旨在减少方差(过拟合)的装袋法不同,提升法是一种非常适应性的方式串行拟合多个弱学习器的方法:拟合序列中的每个基模型都更加重视数据集中被之前的基模型错误处理的观测数据。直观地说,每个新模型都将精力集中在迄今为止最难拟合的观测数据上,以便在串行过程结束时获得一个具有较低偏差的强学习器。提升法即可用于回归任务,也可用于分类任务。
由于提升法主要专注于减少偏差,因此被考虑用于提升的基模型通常具有低方差和高偏差。例如:如果想使用树作为基模型,我们大多数时候会选择只有很少深度的浅层决策树。另一个促使使用此类弱学习器的重要原因是,这些模型的拟合计算量通常较少。事实上,由于拟合不同模型的计算不能并行完成(与装袋不同),顺序拟合多个复杂模型的代价可能会变得过于昂贵。
选择了弱学习器后,仍然需要定义按照何种顺序拟合(即:我们在拟合当前模型时考虑了来自先前模型的哪些信息?)以及按照什么方式聚合(我们如何聚合当前模型到以前的?)的问题。下面介绍两个重要的提升算法:自适应提升法(Adaboost) 和梯度提升法( Gradient Boosting)。
这两种元算法在顺序过程中创建和聚合弱学习器的方式不同。自适应提升法更新附加到每个训练集中观测样本点上的权重,而梯度提升法更新这些观测样本的值。这个主要区别来自于两种方法解决优化问题方式的不同。

提升法迭代地拟合弱学习器,将其聚合到集成模型并“更新”训练数据集,以便在拟合下一个基本模式时更好地考虑当前集成模型的优势和劣势。
(1)自适应提升
在自适应提升(通常称为“adaboost”)中,我们尝试将集成模型定义为 L 个弱学习器的加权和
寻找具有这种形式的最佳集成模型是一个困难的优化问题。然后,我们不是尝试一次性解决它(找到所有系数和弱学习器,以提供最佳的整体加法模型),而是使用更易于处理的迭代优化过程,即使它可能导致次优解。更特别的是,我们一个一个地添加弱学习器,在每次迭代中寻找最佳的可能对(系数,弱学习器)以添加到当前的集成模型中。换句话说,我们循环定义 (s_l) 使得
其中 c_l 和 w_l 的选择使得 s_l 是最适合训练数据的模型,因此,这是对 s_(l-1) 的最佳改进。然后我们可以表示
其中 E(.) 是给定模型的拟合误差,e(.,.) 是损失/误差函数。因此,我们不是对总和中的所有 L 个模型进行“全局”优化,而是通过优化“局部”构建并将弱学习器逐一添加到强模型中来近似最优。
更特别的是,在考虑二进制分类时,我们可以证明 adaboost 算法可以重写为如下过程。首先,它更新数据集中的观测权重并训练一个新的弱学习器,特别关注当前集成模型错误分类的观测。其次,它根据表达该弱模型性能的更新系数将弱学习器添加到加权和中:弱学习器性能越好,它对强学习器的贡献就越大。
因此,假设我们正面临一个二元分类问题,在我们的数据集中有 N 个观测值,并且我们希望对给定的弱模型系列使用 adaboost 算法。在算法的最开始(序列的第一个模型),所有观测值都具有相同的权重 1/N。然后,我们重复 L 次(对于序列中的 L 个学习者)以下步骤:
用当前的观测权重拟合最好的弱模型 计算更新系数的值,该系数是弱学习器的某种标量评估指标,表明该弱学习器应在集成模型中考虑多少 通过添加新的弱学习器乘以其更新系数来更新强学习器 计算新的观察权重,表示我们希望在下一次迭代中关注哪些观察结果(由聚合模型错误预测的观察权重增加,正确预测观察的权重减少)
重复这些步骤,我们依次构建我们的 L 个模型并将它们聚合成一个简单的线性组合,由表示每个学习器性能的系数加权。请注意,存在初始 adaboost 算法的变体,例如 LogitBoost(分类)或 L2Boost(回归),其主要区别在于它们选择的损失函数。
2.3 堆叠法( Stacking )¶
与装袋法和提升法中采用同质基模型的思路不同,堆叠法采用异质基模型。首先通过训练得到多个基于不同算法的基模型,然后再通过训练一个元模型来对其它模型的输出结果进行融合。例如:可以选择逻辑回归、朴素贝叶斯和 KNN 作为基模型,以决策树作为元模型。 堆叠法首先训练得到前三个基模型;然后再以基模型的输出作为决策树的输入,继续训练元模型;最后以决策树的输出作为最终分类结果。
下代码所示为 sklearn 中实现上述过程的部分代码:
if __name__ == '__main__':
x_train, x_test, y_train, y_test = load_data()
estimators = [('logist', LogisticRegression()),
('nb', MultinomialNB()),
('knn', KNeighborsClassifier(n_neighbors=3))]
stacking = StackingClassifier(estimators=estimators,
final_estimator=DecisionTreeClassifier(),
cv=3)
stacking.fit(x_train, y_train)
acc = stacking.score(x_test, y_test)
print(acc)
2.4 半监督分类任务¶
4 深度集成¶
4.1 一般性的深度集成¶
4.1 快照法( Snapshot )¶
4.2 快速几何集成法( fast geometric ensembling, FGE )¶
4.3 随机权重平均法( stochastic weight averaging, SWA )¶
4.4 LoMiFoSS¶
6 总结¶
在这篇文章中, 笔者首先通过一个引例大致介绍了什么是集成模型;然后再分别介绍了三种常见的集成模型:装袋法、提升法和 堆叠法,其中对于装袋法和 堆叠法两种集成模型还列举了 sklearn 中的示例用法。本次内容就到此结束,感谢阅读!