【摘 要】 卫星和飞机上的自动传感仪器能够收集大空间区域空间场的大量高分辨率观测数据。如果可以有效地利用这些数据集,它们可以为各种问题提供新的见解。然而,传统的空间统计技术(如克里金法)在计算上对于大数据集不可行。我们提出了在空间不规则位置观测到的高斯过程的多分辨率近似 (M-RA)。 M-RA 过程被指定为多个空间分辨率级别的基函数的线性组合,它可以捕获从非常精细到非常大尺度的空间结构。自动选择基函数来近似给定的协方差函数,该协方差函数可以是非平稳的。所有涉及 M-RA 的计算,包括参数推断和预测,对于海量数据集都是高度可扩展的。至关重要的是,推断算法也可以并行化,以充分利用大型分布式内存计算环境。在使用模拟数据和大型卫星数据集进行比较时,M-RA 优于相关的最新技术
【原 文】 Katzfuss, M. (2017) ‘A Multi-Resolution Approximation for Massive Spatial Datasets’, Journal of the American Statistical Association, 112(517), pp. 201–214. Available at: https://doi.org/10.1080/01621459.2015.1123632 .
1 简介
卫星和飞机上的自动传感仪器已经能够收集大型和非均匀空间域上空间场的大量高分辨率观测数据。如果可以有效地利用这些类型的数据集,它们可以为各种各样的问题提供新的见解,例如气候变化的温室气体浓度、精准农业的土壤特性以及天气预报的大气状态。基于(隐式或显式)高斯过程,空间统计领域为分析此类数据提供了丰富的工具包,包括估计未知参数,预测未观测到的位置的空间场,以及适当量化预测和参数中的不确定性(例如, Cressie 和 Wikle, 2011 [7]
然而,传统的空间统计技术(如克里金法)在计算上对于大数据集不可行,因为需要分解密集的 n × n n \times n n × n n n n
(1)纯数值计算方法
通用方法,例如预处理共轭梯度算法(例如,Golub 和 Van Loan,2012 年 [15] [17] [45]
(2)近似推断方法
文献中提出了更专门的近似空间推断方法,这些方法明确尝试利用数据中的空间信息,但其中:
大多数方法都需要对协方差函数进行限制性假设(例如,Fuentes,2007 年 [12] [32]
或者忽略了很多精细尺度的依赖性(例如,Higdon,1998 年 [20] [33] [3] [6] [24] [31] [25] [26]
大规模依赖(例如,Furrer 等,2006 年 [13] [29] [40]
复合似然法(例如,Vecchia,1988 年 [47] [8] [46] [4] [2] [9]
(3)本文方法
我们在这里提出了在空间中不规则(即非网格)位置观测到的高斯过程的多分辨率近似(M-RA)。
在模型结构方面:
M-RA 过程被定义为多个空间分辨率级别基函数的线性组合,它可以捕获从非常精细到非常大尺度的空间结构 。
与多分辨率模型的关系 :多分辨率模型(例如 Chui,1992 年;Johannesson 等,2007 年;Nychka 等,2015 年 [35] 与这些多分辨率模型方法相比, M-RA 中的基函数及其权重分布是通过对指定协方差函数的 “预测过程” 递归优化选择的,而多分辨率模型则大多事先选定基函数的形式 。具体来说,每一级分辨率的每一个子区域的基函数,都是根据预测过程(Quinonero Candela 和 Rasmussen,2005 年 [36] [1] 与全尺度近似方法的关系 :M-RA 是全尺度近似的泛化 (Snelson 和 Ghahramani,2007 年 [42] [38] [37]
注:
多分辨率模型 :将空间过程分解为在多个多分辨率上的子过程,每个子过程进一步根据 KL 展开分解为该分辨率层级上若干 “结点” 位置处的基函数组合,由于超参数会随着分辨率层级的变化而相应变化,因此使得空间过程能够反映多个分辨率上的空间模式。参见 Nychka 等 2015 年提出的 《格子克里金法》 。
全尺度近似 : 是 Sang 和 Huang (2012 年 [37]
预测过程 : 是 Banerjee 等 2008 年提出的一种近似方法。该方法是一种更接近空间几何的方法,采用某种策略在研究区域内选择 m m m 预测过程 )来近似原始空间过程,显然 “结点” 的选择策略是一个重要环节。参见 《高斯预测过程》 。
降秩过程 :代表作是 Cressie 等 2008 年提出的 《固定秩克里金法》 。该方法采是纯数学方法,将满秩的 n × n n \times n n × n r × r r \times r r × r c o v ( s , t ) = S ( s ) ⊤ K S ( t ) cov(\mathbf{s,t}) = S(\mathbf{s})^{\top} \mathbf{K} S(\mathbf{t}) co v ( s , t ) = S ( s ) ⊤ K S ( t ) K \mathbf{K} K r × r r \times r r × r S ( s ) S(\mathbf{s}) S ( s ) r r r r × 1 r \times 1 r × 1 K \mathbf{K} K
在模型推断方面:
基于基函数的模型推断,本质上包含对基函数权重(注:被视为随机变量)后验分布的推断。在之前的方法中:
通过将基函数的数量限制在较小范围内(例如,Higdon,1998 年 [20] [36] [6]
或指定权重随机向量的协方差矩阵为对角矩阵或稀疏矩阵(例如,Higdon,1998 年 [20] [32] [35]
M-RA 结合了这两种方法:它产生了多分辨率(块)的稀疏精度矩阵,但每个区域内的空间基函数数量很少,允许重复应用 Sherman-Morrison-Woodbury 公式 (Sherman 和 Morrison,1950 年[41] [48] 《固定秩克里金法》 的 第 2.3 节)。这导致 M-RA 的高度可扩展推断算法(注:该算法也可以应用于任何具有类似结构的多分辨率基函数模型)。至关重要的是,基于之前工作(Katzfuss 和 Hammerling,2014 [27]
这篇文章的结构安排如下:
在 第 2 节 中,我们介绍了 M-RA 并讨论了它的一些属性。
在 第 3 节 中,我们介绍了参数推断和空间预测的算法,并描述了 M-RA 的计算复杂度。
在 第 4 节 中,我们将 M-RA 应用于大型模拟数据集和真实数据示例,并将 M-RA 与全面近似进行比较。
在 第 5 节 总结。所有证明都在附录 A 中给出。
2 多分辨率近似(M-RA)
我们从描述要近似的真实高斯过程开始本节( 第 2.1 节 )。经过一些准备工作( 第 2.2 节 ),我们介绍了多分辨率近似 (M-RA)( 第 2.3 节 )并讨论了它的属性( 第 2.4 节 和 第 2.5 节 )。
2.1 真正的高斯过程
令 { y 0 ( s ) : s ∈ D } \{y_0(\mathbf{s}) : \mathbf{s} \in \mathcal{D}\} { y 0 ( s ) : s ∈ D } y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ ) D ⊂ R d \mathcal{D} \subset \mathbb{R}^d D ⊂ R d d ∈ N + d \in \mathbb{N}^+ d ∈ N + y 0 ( ⋅ ) ∼ G P ( 0 , C 0 ) y_0(·) \sim \mathcal{GP}(0, C_0) y 0 ( ⋅ ) ∼ G P ( 0 , C 0 ) C 0 C_0 C 0 C 0 C_0 C 0 D \mathcal{D} D θ \boldsymbol{\theta} θ y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ ) n n n S = { s 1 , … , s n } \mathcal{S} = \{\mathbf{s}_1,\ldots , \mathbf{s}_n\} S = { s 1 , … , s n } y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ )
y 0 ( S ) : = ( y 0 ( s 1 ) , … , y 0 ( s n ) ) ′ ∼ N n ( 0 , C 0 ( S , S ) ) y_0(\mathcal{S}) := (y_0(\mathbf{s}_1), \ldots , y_0(\mathbf{s}_n))^{\prime} \sim \mathcal{N}_n(\mathbf{0}, \mathbf{C}_0(\mathcal{S,S}))
y 0 ( S ) := ( y 0 ( s 1 ) , … , y 0 ( s n ) ) ′ ∼ N n ( 0 , C 0 ( S , S ))
一个具有协方差矩阵 C 0 ( S , S ) = ( C 0 ( s i , s j ) ) i , j = 1 , … , n C_0(\mathcal{S,S}) = (C_0(\mathbf{s}_i, \mathbf{s}_j))_{i,j=1,\ldots ,n} C 0 ( S , S ) = ( C 0 ( s i , s j ) ) i , j = 1 , … , n n n n
空间统计的基本目标是(基于似然的)对参数 θ \boldsymbol{\theta} θ S P \mathcal{S}^P S P y θ ( ⋅ ) \mathbf{y}_{\boldsymbol{\theta}}(·) y θ ( ⋅ ) y 0 ( S P ) \mathbf{y}_0(\mathcal{S}^P) y 0 ( S P ) C 0 ( S , S ) \mathbf{C}_0(\mathcal{S, S}) C 0 ( S , S ) O ( n 3 ) \mathcal{O}(n^3) O ( n 3 ) O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) n = 10 5 n = 10^5 n = 1 0 5
2.2 域划分和节点
(1)空间域的划分
为了定义 M-RA,我们要对空间域 D \mathcal{D} D J J J D 1 , … , D J \mathcal{D}_1,\ldots, \mathcal{D}_J D 1 , … , D J J J J M M M
D j 1 , … , j m − 1 = ∪ ˙ j m = 1 , … , J D j 1 , … , j m , where j 1 , … , j m − 1 = 1 , … , J ; m = 1 , … , M \mathcal{D}_{j_1,\ldots ,j_{m-1}} =\dot{\cup}_{j_m=1,\ldots ,J} \mathcal{D}_{j_1,\ldots ,j_m},\qquad \text{where} \quad j_1,\ldots , j_{m-1} = 1,\ldots,J ; m = 1,\ldots,M
D j 1 , … , j m − 1 = ∪ ˙ j m = 1 , … , J D j 1 , … , j m , where j 1 , … , j m − 1 = 1 , … , J ; m = 1 , … , M
对于高斯过程 x ( ⋅ ) ∼ G P ( 0 , C ) x(·) \sim \mathcal{GP}(0, C) x ( ⋅ ) ∼ G P ( 0 , C ) [ x ( ⋅ ) ] [ m ] [x(·)]_{[m]} [ x ( ⋅ ) ] [ m ] x ( ⋅ ) x(·) x ( ⋅ ) m m m [ x ( ⋅ ) ] [ m ] ∼ G P ( 0 , [ C ] [ m ] ) [x(·)]_{[m]} \sim \mathcal{GP}(0, [C]_{[m]}) [ x ( ⋅ ) ] [ m ] ∼ G P ( 0 , [ C ] [ m ] ) s 1 \mathbf{s}_1 s 1 s 2 \mathbf{s}_2 s 2 m m m D j 1 , … , j m \mathcal{D}_{j_1,\ldots,j_m} D j 1 , … , j m [ C ] [ m ] ( s 1 , s 2 ) = C ( s 1 , s 2 ) [C]_{[m]}(\mathbf{s}_1, \mathbf{s}_2) = C(\mathbf{s}_1, \mathbf{s}_2) [ C ] [ m ] ( s 1 , s 2 ) = C ( s 1 , s 2 ) [ C ] [ m ] ( s 1 , s 2 ) = 0 [C]_{[m]}(\mathbf{s}_1, \mathbf{s}_2) = 0 [ C ] [ m ] ( s 1 , s 2 ) = 0
(2)结点的设置
我们还需要一组多多分辨率 “结点”,例如 Q j 1 , … , j m \mathcal{Q}_{j_1,\ldots ,j_m} Q j 1 , … , j m r r r r ≪ n r \ll n r ≪ n D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m M M M Q j 1 , … , j M = S j 1 , … , j M \mathcal{Q}_{j_1,\ldots ,j_M} = \mathcal{S}_{j_1,\ldots ,j_M} Q j 1 , … , j M = S j 1 , … , j M m m m Q ( m ) = { Q j 1 , … , j m : j 1 , … , j m = 1 , … , J } \mathcal{Q}^{(m)} = \{\mathcal{Q}_{j_1,\ldots ,j_m} : j_1,\ldots , j_m = 1,\ldots , J \} Q ( m ) = { Q j 1 , … , j m : j 1 , … , j m = 1 , … , J } r J m rJ^{m} r J m
对于一维玩具示例, 图 1 的顶行显示了 M = 1 M = 1 M = 1 M = 3 M = 3 M = 3 J J J r r r 第 2.5 节 给出了他们选择的进一步讨论。
图 1:在 n = 54 n = 54 n = 54 D = [ 0 , 1 ] \mathcal{D} = [0, 1] D = [ 0 , 1 ] M r = 6 M r = 6 M r = 6 3 3 3 m m m m = 0 , … , M m = 0, \ldots, M m = 0 , … , M m m m m = M m = M m = M 第 2.5 节)。
2.3 多分辨率近似(M-RA)的定义
回忆 第 2.1 节 中的真实高斯过程 y 0 ( ⋅ ) ∼ G P ( 0 , C 0 ) y_0(·) \sim \mathcal{GP}(0, C_0) y 0 ( ⋅ ) ∼ G P ( 0 , C 0 ) C 0 C_0 C 0 第 3.3 节 中讨论)。 M-RA 过程以分辨率 m = 0 , … , M m = 0,\ldots , M m = 0 , … , M y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ ) C 0 C_0 C 0 第 2.2 节 中指定的 “结点” 和 “分区” 。在每个分辨率 m m m D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m [1] y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ ) 图 1(d) 所示,低 M-RA 分辨率捕获低频(即远距离)的可变性,导致随着 m m m
更具体地说,我们从 y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ ) τ 0 ( s ) : = E ( y 0 ( s ) ∣ y 0 ( Q ( 0 ) ) ) \tau_0(\mathbf{s}) := \mathbb{E}(y_0(\mathbf{s}) \mid \mathbf{y}_0(\mathcal{Q}^{(0)})) τ 0 ( s ) := E ( y 0 ( s ) ∣ y 0 ( Q ( 0 ) )) s ∈ D \mathbf{s} \in \mathcal{D} s ∈ D D 1 , … , D J \mathcal{D}_1,\ldots , \mathcal{D}_J D 1 , … , D J 1 1 1 δ 1 ( ⋅ ) = [ y 0 ( ⋅ ) − τ 0 ( ⋅ ) ] [ 1 ] \delta_1(·) = [y_0(·) − \tau_0(·)]_{[1]} δ 1 ( ⋅ ) = [ y 0 ( ⋅ ) − τ 0 ( ⋅ ) ] [ 1 ] [38] τ 1 ( s ) = E ( δ 1 ( s ) ∣ δ 1 ( Q ( 1 ) ) ) \tau_1(\mathbf{s}) = \mathbb{E}(\delta_1(\mathbf{s}) | \delta_1(\mathcal{Q}^{(1)})) τ 1 ( s ) = E ( δ 1 ( s ) ∣ δ 1 ( Q ( 1 ) )) s ∈ D \mathbf{s} \in \mathcal{D} s ∈ D δ 2 ( ⋅ ) = [ δ 1 ( ⋅ ) − τ 1 ( ⋅ ) ] [ 2 ] \delta_2(·) = [ \delta_1(·) − \tau_1(·)]_{[2]} δ 2 ( ⋅ ) = [ δ 1 ( ⋅ ) − τ 1 ( ⋅ ) ] [ 2 ] M M M
y M ( ⋅ ) = τ 0 ( ⋅ ) + τ 1 ( ⋅ ) + … + τ M − 1 ( ⋅ ) + δ M ( ⋅ ) (1) y_M(·) = \tau_0(·) + \tau_1(·) + \ldots + \tau_{M-1}(·) + \delta_M(·) \tag{1}
y M ( ⋅ ) = τ 0 ( ⋅ ) + τ 1 ( ⋅ ) + … + τ M − 1 ( ⋅ ) + δ M ( ⋅ ) ( 1 )
其中预测过程 τ m ( s ) = E ( δ m ( s ) ∣ δ m ( Q ( m ) ) ) \tau_m(\mathbf{s}) = \mathbb{E}(\delta_m(\mathbf{s}) | \delta_m(\mathcal{Q}^{(m)})) τ m ( s ) = E ( δ m ( s ) ∣ δ m ( Q ( m ) )) s ∈ D \mathbf{s} \in \mathcal{D} s ∈ D δ m ( ⋅ ) = [ δ m − 1 ( ⋅ ) − τ m − 1 ( ⋅ ) ] [ m ] ∼ G P ( 0 , v m ) \delta_m(·) = [\delta_{m−1}(·) − \tau_{m−1}(·)]_{[m]} \sim \mathcal{GP}(0, v_m) δ m ( ⋅ ) = [ δ m − 1 ( ⋅ ) − τ m − 1 ( ⋅ ) ] [ m ] ∼ G P ( 0 , v m )
注意到,对于 m = 0 , … , M − 1 m = 0,\ldots , M − 1 m = 0 , … , M − 1 s ∈ D j 1 , … , j m \mathbf{s} \in \mathcal{D}_{j_1,\ldots ,j_m} s ∈ D j 1 , … , j m [23] τ m ( s ) = b j 1 , … , j m ( s ) ′ η j 1 , … , j m \tau_m(\mathbf{s}) = \mathbf{b}_{j_1,\ldots ,j_m}(\mathbf{s})^{\prime} \boldsymbol{η}_{j_1,\ldots ,j_m} τ m ( s ) = b j 1 , … , j m ( s ) ′ η j 1 , … , j m η j 1 , … , j m ∼ N r ( 0 , K j 1 , … , j m ) \boldsymbol{η}_{j_1,\ldots ,j_m} \sim \mathcal{N}_r(\mathbf{0}, \mathbf{K}_{j_1,\ldots ,j_m}) η j 1 , … , j m ∼ N r ( 0 , K j 1 , … , j m )
b j 1 , … , j m ( s ) : = v m ( s , Q j 1 , … , j m ) , s ∈ D j 1 , … , j m K j 1 , … , j m − 1 : = v m ( Q j 1 , … , j m , Q j 1 , … , j m ) v m + 1 ( s 1 , s 2 ) : = v m ( s 1 , s 2 ) − b j 1 , … , j m ( s 1 ) ′ K j 1 , … , j m b j 1 , … , j m ( s 2 ) , s 1 , s 2 ∈ D j 1 , … , j m (2) \begin{align*}
\mathbf{b}_{j_1,\ldots ,j_m} (\mathbf{s}) &:= v_m({\mathbf{s}}, \mathcal{Q}_{j_1,\ldots ,j_m}), \mathbf{s} \in \mathcal{D}_{j_1,\ldots ,j_m} \\
\mathbf{K}^{-1}_{j_1,\ldots ,j_m} &:= v_m(\mathcal{Q}_{j_1,\ldots ,j_m}, \mathcal{Q}_{j_1,\ldots ,j_m})\\
v_{m+1}(\mathbf{s}_1, \mathbf{s}_2) &:= v_m(\mathbf{s}_1, \mathbf{s}_2) − \mathbf{b}_{j_1,\ldots ,j_m} (\mathbf{s}_1)^{\prime} \mathbf{K}_{j_1,\ldots ,j_m} \mathbf{b}_{j_1 ,\ldots ,j_m}(\mathbf{s}_2), \quad \mathbf{s}_1, \mathbf{s}_2 \in \mathcal{D}_{j_1,\ldots ,j_m}
\end{align*} \tag{2}
b j 1 , … , j m ( s ) K j 1 , … , j m − 1 v m + 1 ( s 1 , s 2 ) := v m ( s , Q j 1 , … , j m ) , s ∈ D j 1 , … , j m := v m ( Q j 1 , … , j m , Q j 1 , … , j m ) := v m ( s 1 , s 2 ) − b j 1 , … , j m ( s 1 ) ′ K j 1 , … , j m b j 1 , … , j m ( s 2 ) , s 1 , s 2 ∈ D j 1 , … , j m ( 2 )
其中如果 s 1 \mathbf{s}_1 s 1 s 2 \mathbf{s}_2 s 2 m m m v m + 1 ( s 1 , s 2 ) = 0 v_{m+1}(\mathbf{s}_1, \mathbf{s}_2) = 0 v m + 1 ( s 1 , s 2 ) = 0 v 0 = C 0 v_0 = C_0 v 0 = C 0
因此,式(1) 的 M-RA 也可以写成分辨率 0 , … , M − 1 0,\ldots , M − 1 0 , … , M − 1 M M M
y M ( s ) = b ( s ) ′ η + b j 1 ( s ) ′ η j 1 + … + b j 1 , … , j M − 1 ( s ) ′ η j 1 , … , j M − 1 + δ M ( s ) , s ∈ D j 1 , … , j M (3) \mathbf{y}_M(\mathbf{s}) = \mathbf{b}(\mathbf{s})^{\prime} \boldsymbol{η} + \mathbf{b}_{j_1}(\mathbf{s})^{\prime} \boldsymbol{η}_{j_1} + \ldots + \mathbf{b}_{j_1,\ldots ,j_{M−1}}(\mathbf{s})^{\prime} \boldsymbol{η}_{j_1,\ldots ,j_{M−1}} + \delta_M(\mathbf{s}), \qquad \mathbf{s} \in \mathcal{D}_{j_1,\ldots ,j_M} \tag{3}
y M ( s ) = b ( s ) ′ η + b j 1 ( s ) ′ η j 1 + … + b j 1 , … , j M − 1 ( s ) ′ η j 1 , … , j M − 1 + δ M ( s ) , s ∈ D j 1 , … , j M ( 3 )
其中权重向量相互独立且与 δ M ( ⋅ ) ∼ G P ( 0 , v M ) \delta_M(·) \sim \mathcal{GP}(0, v_M ) δ M ( ⋅ ) ∼ G P ( 0 , v M ) 图 1 (a) 和 图 1 (c) 显示了玩具示例中的基函数。一旦我们在位置 S \mathcal{S} S 式 (3) 中的 “残余项” δ M ( ⋅ ) \delta_M(·) δ M ( ⋅ ) 式 (2) 中 δ M ( s ) = b j 1 , … , j M ( s ) ′ η j 1 , … , j M \delta_M(\mathbf{s}) = \mathbf{b}_{j_1,\ldots ,j_M}(\mathbf{s})^{\prime} \boldsymbol{η}_{j_1,\ldots,j_M} δ M ( s ) = b j 1 , … , j M ( s ) ′ η j 1 , … , j M s ∈ D j 1 , … , j M \mathbf{s} \in \mathcal{D}_{j_1,\ldots ,j_M} s ∈ D j 1 , … , j M Q j 1 , … , j M = S j 1 , … , j M \mathcal{Q}_{j_1,\ldots,j_M} = \mathcal{S}_{j_1,\ldots ,j_M} Q j 1 , … , j M = S j 1 , … , j M
2.4 M-RA 的特性
(1)许多基函数
与依赖于少量或中等数量基函数的所谓低秩方法(参见如,Stein,2014 [44] M > 0 M > 0 M > 0 r t o t a l r_{total} r t o t a l n n n r t o t a l = r ∑ m = 0 M J M = r J M + r ∑ m = 0 M − 1 J m = n + r J M − 1 J − 1 > n r_{total} = r \sum^{M}_{m=0} J^M = rJ^M + r \sum^{M-1}_{m=0} J^m = n + r \frac{ J^M −1}{J−1} > n r t o t a l = r ∑ m = 0 M J M = r J M + r ∑ m = 0 M − 1 J m = n + r J − 1 J M − 1 > n
(2)正交分解
因为预测过程是一个条件期望,也是一个投影运算,对于所有 m = 0 , … , M − 1 m = 0,\ldots , M − 1 m = 0 , … , M − 1 τ m ( ⋅ ) \tau_m(·) τ m ( ⋅ ) δ m ( ⋅ ) − τ m ( ⋅ ) \delta_m(·) − \tau_m(·) δ m ( ⋅ ) − τ m ( ⋅ ) 式 (1) 中的 M-RA 定义为正交分量之和。在 式 (3) 中,M-RA 是空间基函数的加权和,其权重 η j 1 , … , j m \boldsymbol{η}_{j_1,\ldots ,j_m} η j 1 , … , j m D j 1 , … , j m 1 ∩ D i 1 , … , i m 2 = ∅ \mathcal{D}_{j_1,\ldots ,j_{m_1}} \cap D_{i_1,\ldots ,i_{m_2}} = \emptyset D j 1 , … , j m 1 ∩ D i 1 , … , i m 2 = ∅ \mathbf{b}_{j_1,\ldots, j_{m_1} 和 \mathbf{b}_{i_1,\ldots,i_{m_2} 仅在物理空间中是块正交的。
(3)有效的高斯过程
【命题 1】 M-RA 是具有非负定协方差函数 C M C_M C M
(4)“最优” 的基函数
在每个分辨率 m = 0 , … , M − 1 m = 0,\ldots , M −1 m = 0 , … , M − 1 D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m 式 (1) 中 M-RA 的目标是尽可能接近地近似 “残余项” 过程 δ m ( ⋅ ) \delta_m(·) δ m ( ⋅ )
δ m ( ⋅ ) = [ δ m − 1 ( ⋅ ) − τ m − 1 ( ⋅ ) ] [ m ] = [ y 0 ( ⋅ ) − ∑ l = 0 m − 1 τ l ( ⋅ ) ] [ m ] (4) \delta_m(·) = [\delta_{m−1}(·) − \tau_{m−1}(·)]_{[m]} = [y_0(·) − \sum^{m-1}_{l=0} \tau_l(·)]_{[m]} \tag{4}
δ m ( ⋅ ) = [ δ m − 1 ( ⋅ ) − τ m − 1 ( ⋅ ) ] [ m ] = [ y 0 ( ⋅ ) − l = 0 ∑ m − 1 τ l ( ⋅ ) ] [ m ] ( 4 )
因此,在每个区域中,式 (1) 中的 δ m ( ⋅ ) \delta_m(·) δ m ( ⋅ ) y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ ) ∑ l = 0 m − 1 τ l ( ⋅ ) \sum^{m-1}_{l=0} \tau_l(·) ∑ l = 0 m − 1 τ l ( ⋅ ) τ m ( ⋅ ) \tau_m(·) τ m ( ⋅ ) δ m ( ⋅ ) \delta_m(·) δ m ( ⋅ ) τ m ( ⋅ ) \tau_m(·) τ m ( ⋅ ) δ m ( Q ( m ) ) \delta_m(\mathcal{Q}^{(m)}) δ m ( Q ( m ) ) δ m ( s ) \delta_m(\mathbf{s}) δ m ( s ) δ m ( Q ( m ) ) \delta_m(\mathcal{Q}^{(m)}) δ m ( Q ( m ) ) [1] τ m ( ⋅ ) \tau_m(·) τ m ( ⋅ ) D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m δ m ( ⋅ ) \delta_m(·) δ m ( ⋅ ) r r r τ m ( ⋅ ) \tau_m(·) τ m ( ⋅ ) δ m ( ⋅ ) \delta_m(·) δ m ( ⋅ ) r r r [37] r r r τ m ( ⋅ ) \tau_m(·) τ m ( ⋅ ) δ m ( ⋅ ) \delta_m(·) δ m ( ⋅ ) Q j 1 , … , j m \mathcal{Q}_{j_1,\ldots ,j_m} Q j 1 , … , j m S j 1 , … , j m \mathcal{S}_{j_1,\ldots ,j_m} S j 1 , … , j m D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m τ m ( S j 1 , … , j m ) = δ m ( S j 1 , … , j m ) \tau_m(\mathcal{S}_{j_1,\ldots ,j_m}) = \delta_m(\mathcal{S}_{j_1,\ldots ,j_m}) τ m ( S j 1 , … , j m ) = δ m ( S j 1 , … , j m ) τ m ( ⋅ ) \tau_m(·) τ m ( ⋅ ) δ m ( ⋅ ) \delta_m(·) δ m ( ⋅ )
与空间数据的许多其他多分辨率方法相比,M-RA 因此自动提供基函数表示来近似给定的协方差函数 C 0 C_0 C 0 C 0 C_0 C 0 图 2 中进行了说明,它显示了高度非平稳协方差函数 C 0 C_0 C 0
图 2:对于在一维域 D = [ 0 , 1 ] \mathcal{D} = [0, 1] D = [ 0 , 1 ] 0.15 0.15 0.15 ν ( s ) = 0.2 + 0.7 s ν(s) = 0.2+0.7s ν ( s ) = 0.2 + 0.7 s J = 2 J = 2 J = 2 r = 3 r = 3 r = 3
(5)协方差近似的质量
在分辨率为 m m m b j 1 , … , j m ( ⋅ ) ′ η j 1 , … , j m \mathbf{b}_{j_1,\ldots ,j_m}(·)^{\prime} \boldsymbol{η}_{j_1,\ldots ,j_m} b j 1 , … , j m ( ⋅ ) ′ η j 1 , … , j m C M ( s 1 , s 2 ) C_M(\mathbf{s}_1, \mathbf{s}_2) C M ( s 1 , s 2 ) C 0 ( s 1 , s 2 ) C_0(\mathbf{s}_1, \mathbf{s}_2) C 0 ( s 1 , s 2 ) s 1 \mathbf{s}_1 s 1 s 2 \mathbf{s}_2 s 2 s 1 \mathbf{s}_1 s 1 s 2 \mathbf{s}_2 s 2 M M M C M ( s 1 , s 2 ) = C 0 ( s 1 , s 2 ) C_M(\mathbf{s}_1, \mathbf{s}_2) = C_0(\mathbf{s}_1, \mathbf{s}_2) C M ( s 1 , s 2 ) = C 0 ( s 1 , s 2 ) 式 (1) 与 式 (4) 结合起来。)这也意味着 y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ ) y M ( ⋅ ) y_M(·) y M ( ⋅ ) s 1 \mathbf{s}_1 s 1 s 2 \mathbf{s}_2 s 2 m < M m<M m < M D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m m + 1 m + 1 m + 1 C 0 ( s 1 , s 2 ) C_0(\mathbf{s}_1, \mathbf{s}_2) C 0 ( s 1 , s 2 ) m m m C M ( s 1 , s 2 ) = ∑ l = 0 m b j 1 , … , j l ( s 1 ) ′ K j 1 , … , j l b j 1 , … , j l ( s 2 ) C_M (\mathbf{s}_1, \mathbf{s}_2) = \sum^{m}_{l=0} \mathbf{b}_{j_1,\ldots ,j_l}(\mathbf{s}_1)^{\prime} \mathbf{K}_{j_1,\ldots ,j_l} \mathbf{b}_{j_1,\ldots ,j_l}(\mathbf{s}_2) C M ( s 1 , s 2 ) = ∑ l = 0 m b j 1 , … , j l ( s 1 ) ′ K j 1 , … , j l b j 1 , … , j l ( s 2 )
(6)与全尺寸近似的比较
M-RA 的重要特例是 M = 0 M = 0 M = 0 y 0 y_0 y 0 M = 1 M = 1 M = 1 [42] [38] r F r^F r F Q F \mathcal{Q}^F Q F D = ∪ ˙ j = 1 , … , J F D j F \mathcal{D} =\dot{\cup}_{j=1,\ldots ,J^F} \mathcal{D}^F_j D = ∪ ˙ j = 1 , … , J F D j F D j F \mathcal{D}^F_j D j F
比较 M-RA(M > 1 M > 1 M > 1 Q F = Q \mathcal{Q}^F = Q Q F = Q { D j F : j = 1 , … , J F } = { D j 1 , … , j M : j 1 , … , j M = 1 , … , J } \{\mathcal{D}^F_j : j = 1,\ldots , J^F\} = \{\mathcal{D}_{j_1,\ldots ,j_M} : j_1,\ldots , j_M = 1,\ldots , J\} { D j F : j = 1 , … , J F } = { D j 1 , … , j M : j 1 , … , j M = 1 , … , J } D j F \mathcal{D}^F_j D j F 1 1 1 i ≠ j i \neq j i = j D i \mathcal{D}_i D i D j \mathcal{D}_j D j r r r τ m ( ⋅ ) \tau_m(·) τ m ( ⋅ ) D j 1 , … , j m + 1 \mathcal{D}_{j_1,\ldots ,j_{m+1}} D j 1 , … , j m + 1 δ m ( ⋅ ) \delta_m(·) δ m ( ⋅ ) y 0 ( ⋅ ) y_0(·) y 0 ( ⋅ )
如稍后在 第 3.6 节 中所述,具有 r r r M r M r M r 图 1 所示,M-RA 可以产生相当好的近似。进一步的比较在 第 4 节 中介绍。
2.5 更多关于节点和 “分区” 的选择
为了获得良好的近似,我们建议在 r J M ≤ n rJ^M \leq n r J M ≤ n M M M J J J r r r 表(1a) )。
如果观测位置近似均匀分布在域 D \mathcal{D} D J J J
剩下的问题是每个区域内 r r r D j 1 , … , j m \mathcal{D}_{j_1,\ldots,j_m} D j 1 , … , j m 式(4) 和 第 2.3 节 中每个区域 D j 1 , … , j m \mathcal{D}_{j_1,\ldots,j_m} D j 1 , … , j m δ m ( ⋅ ) ∼ G P ( 0 , v m ) \delta_m(·) \sim \mathcal{GP}(0, v_m) δ m ( ⋅ ) ∼ G P ( 0 , v m ) J = 2 J = 2 J = 2 S = { S 1 , S 2 } \mathcal{S} = \{\mathcal{S}_1, \mathcal{S}_2\} S = { S 1 , S 2 } S j = { S j B , S j I } \mathcal{S}_j = \{\mathcal{S}^B_j , \mathcal{S}^I_j \} S j = { S j B , S j I } S j B \mathcal{S}^B_j S j B c c c S j I \mathcal{S}^I_j S j I j j j Q j + 1 , … , j m = S B : = { S 1 B , S 2 B } \mathcal{Q}_{j+1,\ldots,j_m} = \mathcal{S}^B := \{\mathcal{S}^B_1 , \mathcal{S}^B_2 \} Q j + 1 , … , j m = S B := { S 1 B , S 2 B } var ( δ m ( S I ) ∣ δ m ( S B ) ) \operatorname{var}(\delta_m(\mathcal{S}I)|\delta_m(\mathcal{S}B)) var ( δ m ( S I ) ∣ δ m ( S B )) var ( δ m ( S I ) ∣ δ m ( S B ) ) \operatorname{var}(\delta_m(\mathcal{S}^I)|\delta_m(\mathcal{S}^B)) var ( δ m ( S I ) ∣ δ m ( S B )) cov ( δ m ( S I 1 ) , δ m ( S I 2 ) ∣ δ m ( S B ) ) \operatorname{cov}(\delta_m(\mathcal{S}I 1 ), \delta_m(\mathcal{S}I 2 )|\delta_m(\mathcal{S}B)) cov ( δ m ( S I 1 ) , δ m ( S I 2 ) ∣ δ m ( S B )) c c c [43] v m v_m v m
图 1 说明了该策略的一个极端情况。对于在一个空间维度上没有块块的指数协方差函数,筛选效果完全成立,因为在给定第三个观测值将两者分开的情况下,两个观测值是条件独立的。因为 图 1 中特定分辨率的节点位于下一个更高分辨率的 “分区” 之间的边界上,所以 M-RA 在这种情况下是精确的。对于没有屏蔽效应或更高维度的协方差函数,M-RA 通常不准确。
虽然 第 4.1 节 中的(有利的)数值结果是通过最简单的等面积 “分区” 和等距节点选择获得的,但可以采用更复杂的策略,例如基于聚类选择节点和 “分区” (例如,Snelson 和Ghahramani, 2007 [42] [16] [23] [21]
3 推断
在本节中,我们描述了 M-RA 的推断。对于参数向量 θ \boldsymbol{\theta} θ C 0 C_0 C 0 式 (3) 中的基函数 b j 1 , … , j m \mathbf{b}_{j_1,\ldots ,j_m} b j 1 , … , j m K j 1 , … , j m \mathbf{K}_{j_1,\ldots ,j_m} K j 1 , … , j m 第 3.1 节 )。然后,推断的主要任务是获得未知权重向量 E M − 1 \mathcal{E}^{M-1} E M − 1 第 3.2 节 ),其中我们定义 E m : = { η j 1 , … , j l : j 1 , … , j l = 1 , … , J ; l = 0 , … , m } \mathcal{E}_m := \{ \boldsymbol{η}_{j_1,\ldots ,j_l} : j_1,\ldots , j_l = 1,\ldots , J; l = 0,\ldots , m \} E m := { η j 1 , … , j l : j 1 , … , j l = 1 , … , J ; l = 0 , … , m } m = 0 , … , M − 1 m = 0,\ldots , M − 1 m = 0 , … , M − 1 m m m E − 1 = ∅ \mathcal{E}_{-1} = \emptyset E − 1 = ∅ 第 3.3 节 )和获得空间预测( 第 3.4 节 )。通过利用权重的先验和后验精度矩阵的块稀疏多多分辨率 “结点”构,我们获得了具有出色时间和内存复杂度的推断( 第 3.6 节 ),可以充分利用具有大量的分布式内存系统节点( 第 3.5 节 ),因此可扩展到海量空间数据集。
3.1 计算先验
令 S j 1 , … , j m \mathcal{S}_{j_1,\ldots ,j_m} S j 1 , … , j m D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m
B j 1 , … , j m l : = b j 1 , … , j l ( S j 1 , … , j m ) , l = 0 , 1 , … , m , Σ j 1 , … , j m : = var ( y M ( S j 1 , … , j m ) ∣ E m − 1 ) = B j 1 , … , j m m K j 1 , … , j m B j 1 , … , j m m ′ + V j 1 , … , j m V j 1 , … , j m : = var ( y M ( S j 1 , … , j m ) ∣ E m ) = blockdiag { Σ j 1 , … , j m , 1 , … , Σ j 1 , … , j m , J } (5) \begin{align*}
\mathbf{B}^l_{j_1,\ldots ,j_m} &:= \mathbf{b}_{j_1,\ldots ,j_l}(\mathcal{S}_{j_1,\ldots , j_m}), l = 0, 1,\ldots , m,\\
\boldsymbol{\Sigma}_{j_1,\ldots ,j_m} &:= \operatorname{var}(\mathbf{y}_M(\mathcal{S}_{j_1,\ldots ,j_m} ) | \mathcal{E}_{m−1}) = \mathbf{B}^m_{j_1,\ldots ,j_m} \mathbf{K}_{j_1,\ldots ,j_m} {\mathbf{B}^{m}_{j_1,\ldots ,j_m}}^{\prime} + \mathbf{V}_{j_1,\ldots ,j_m} \\
\mathbf{V}_{j_1,\ldots ,j_m} &:= \operatorname{var}(\mathbf{y}_M(\mathcal{S}_{j_1,\ldots ,j_m}) | \mathcal{E}_m) = \operatorname{blockdiag}\{ \boldsymbol{\Sigma}_{j_1,\ldots ,j_m,1},\ldots , \boldsymbol{\Sigma}_{j_1,\ldots ,j_m,J} \}
\end{align*} \tag{5}
B j 1 , … , j m l Σ j 1 , … , j m V j 1 , … , j m := b j 1 , … , j l ( S j 1 , … , j m ) , l = 0 , 1 , … , m , := var ( y M ( S j 1 , … , j m ) ∣ E m − 1 ) = B j 1 , … , j m m K j 1 , … , j m B j 1 , … , j m m ′ + V j 1 , … , j m := var ( y M ( S j 1 , … , j m ) ∣ E m ) = blockdiag { Σ j 1 , … , j m , 1 , … , Σ j 1 , … , j m , J } ( 5 )
对于 m = 0 , 1 , … , M − 1 m = 0, 1,\ldots , M − 1 m = 0 , 1 , … , M − 1 Σ j 1 , … , j M : = v M ( S j 1 , … , j M , S j 1 , … , j M ) \boldsymbol{\Sigma}_{j_1,\ldots ,j_M} := v_M (\mathcal{S}_{j_1,\ldots ,j_M} , \mathcal{S}_{j_1,\ldots ,j_M} ) Σ j 1 , … , j M := v M ( S j 1 , … , j M , S j 1 , … , j M )
对于推断,我们明确需要计算矩阵 { K j 1 , … , j m − 1 : j 1 , … , j m = 1 , … , J ; m = 0 , … , M − 1 } \{\mathbf{K}^{-1}_{j_1,\ldots ,j_m}: j_1,\ldots , j_m = 1,\ldots , J ; m = 0,\ldots , M −1\} { K j 1 , … , j m − 1 : j 1 , … , j m = 1 , … , J ; m = 0 , … , M − 1 } { B j 1 , … , j M l : j 1 , … , j M = 1 , … , J ; l = 0 , … , M − 1 } \{\mathbb{B}^l_{j_1,\ldots ,j_M}: j_1,\ldots , j_M = 1,\ldots , J ; l = 0,\ldots , M −1 \} { B j 1 , … , j M l : j 1 , … , j M = 1 , … , J ; l = 0 , … , M − 1 } { Σ j 1 , … , j M : j 1 , … , j M = 1 , … , J } \{\boldsymbol{\Sigma}_{j_1,\ldots ,j_M}: j_1,\ldots , j_M = 1,\ldots , J \} { Σ j 1 , … , j M : j 1 , … , j M = 1 , … , J } W j 1 , … , j m l : = v l ( Q j 1 , … , j m , Q j 1 , … , j l ) \mathbf{W}^l_{j_1,\ldots ,j_m} := v_l(\mathcal{Q}_{j_1,\ldots ,j_m} , \mathcal{Q}_{j_1,\ldots ,j_l} ) W j 1 , … , j m l := v l ( Q j 1 , … , j m , Q j 1 , … , j l )
W j 1 , … , j m l = C 0 ( Q j 1 , … , j m , Q j 1 , … , j l ) − ∑ k = 0 l − 1 W j 1 , … , j m k K j 1 , … , j k W j 1 , … , j l k ′ (6) \mathbf{W}^l_{j_1,\ldots ,j_m} = C_0(\mathcal{Q}_{j_1,\ldots ,j_m} , \mathcal{Q}_{j_1,\ldots ,j_l} ) − \sum^{l-1}_{k=0} \mathbf{W}^k_{j_1,\ldots ,j_m} \mathbf{K}_{j_1,\ldots ,j_k} {\mathbf{W}^k_{j_1,\ldots ,j_l}}^{\prime} \tag{6}
W j 1 , … , j m l = C 0 ( Q j 1 , … , j m , Q j 1 , … , j l ) − k = 0 ∑ l − 1 W j 1 , … , j m k K j 1 , … , j k W j 1 , … , j l k ′ ( 6 )
对于 m = 0 , … , M m = 0,\ldots , M m = 0 , … , M j 1 , … , j m = 1 , … , J j_1,\ldots , j_m = 1,\ldots,J j 1 , … , j m = 1 , … , J l = 0 , … , m l = 0,\ldots,m l = 0 , … , m K j 1 , … , j m − 1 = W j 1 , … , j m m \mathbf{K}^{-1}_{j_1,\ldots ,j_m} = \mathbf{W}^m_{j_1,\ldots ,j_m} K j 1 , … , j m − 1 = W j 1 , … , j m m m < M m < M m < M B j 1 , … , j M l = W j 1 , … , j M l \mathbb{B}^l_{j_1,\ldots ,j_M} = \mathbf{W}^l_{j_1,\ldots ,j_M} B j 1 , … , j M l = W j 1 , … , j M l l < M l < M l < M Σ j 1 , … , j M = W j 1 , … , j M M \boldsymbol{\Sigma}_{j_1,\ldots ,j_M} = \mathbf{W}^M_{j_1,\ldots ,j_M} Σ j 1 , … , j M = W j 1 , … , j M M
顺便说一句,这些矩阵的其他参数化(以及 式(3) 中的数量)也是可能的,并且将导致类似的推断算法,如下所述,只要权重向量是先验独立的并且基函数具有相同的限制支持。
3.2 基函数权重的后验分布
式 (3) 中 M-RA 的定义,连同 式(5) 中的定义,意味着
y M ( S j 1 , … , j m ) ∣ E m ∼ N ( ∑ l = 0 m B j 1 , … , j m l η j 1 , … , j l , V j 1 , … , j m ) \mathbf{y}_M(\mathcal{S}_{j_1,\ldots ,j_m}) | \mathcal{E}_m \sim \mathcal{N}(\sum^{m}_{l=0} \mathbb{B}^l_{j_1,\ldots ,j_m} \boldsymbol{η}_{j_1,\ldots ,j_l} , \mathbf{V}_{j_1,\ldots ,j_m})
y M ( S j 1 , … , j m ) ∣ E m ∼ N ( l = 0 ∑ m B j 1 , … , j m l η j 1 , … , j l , V j 1 , … , j m )
使用 Katzfuss 和 Hammerling(2014 年, 第 3 节 )中的结果,可以证明所有 m = 0 , … , M − 1 m = 0,\ldots , M − 1 m = 0 , … , M − 1
η j 1 , … , j m ∣ y M ( S ) , E m − 1 ∼ i n d . N r ( ν ~ j 1 , … , j m , K ~ j 1 , … , j m ) , j 1 , … , j m = 1 , … J (7) \mathbf{η}_{j_1,\ldots ,j_m} | \mathbf{y}_M(\mathcal{S}), \mathcal{E}_{m−1} \stackrel{ind.} \sim \mathcal{N}_r(\tilde{\boldsymbol{ν}}_{j_1,\ldots ,j_m} ,\tilde{\mathbf{K}}_{j_1,\ldots ,j_m}), j_1,\ldots , j_m = 1,\ldots J \tag{7}
η j 1 , … , j m ∣ y M ( S ) , E m − 1 ∼ in d . N r ( ν ~ j 1 , … , j m , K ~ j 1 , … , j m ) , j 1 , … , j m = 1 , … J ( 7 )
具有后验精度和均值分别为:
K ~ j 1 , … , j m − 1 = K j 1 , … , j m − 1 + B j 1 , … , j m m ′ V j 1 , … , j m − 1 B j 1 , … , j m m = K j 1 , … , j m − 1 + A j 1 , … , j m m , m ν ~ j 1 , … , j m = K ~ j 1 , … , j m ( B j 1 , … , j m m ′ V j 1 , … , j m − 1 ( y M ( S j 1 , … , j m ) − ∑ l = 0 m − 1 B j 1 , … , j m l η j 1 , … , j l ) ) = K ~ j 1 , … , j m ω j 1 , … , j m m − ∑ l = 0 m − 1 K j 1 , … , j m A j 1 , … , j m m , l η j 1 , … , j l (8) \begin{align*}
\tilde{\mathbf{K}}^{-1}_{j_1,\ldots ,j_m} = \mathbf{K}^{-1}_{j_1,\ldots ,j_m} + {\mathbf{B}^m_{j_1,\ldots ,j_m}}^{\prime} \mathbf{V}^{−1}_{j_1,\ldots ,j_m} \mathbf{B}^m_{j_1,\ldots ,j_m} = \mathbf{K}^{-1}_{j_1,\ldots ,j_m} + \mathbf{A}^{m,m}_{j_1,\ldots ,j_m}\\
\tilde{\boldsymbol{ν}}_{j_1,\ldots ,j_m} = \tilde{\mathbf{K}}_{j_1,\ldots ,j_m} ({\mathbf{B}^m_{j_1,\ldots ,j_m}}^{\prime} \mathbf{V}^{−1}_{j_1,\ldots ,j_m} (\mathbf{y}_M(\mathcal{S}_{j_1,\ldots ,j_m} ) − \sum^{m-1}_{l=0} \mathbb{B}^l_{j_1,\ldots ,j_m} \boldsymbol{η}_{j_1,\ldots ,j_l})) \\
= \tilde{\mathbf{K}}_{j_1,\ldots ,j_m} \boldsymbol{ω}^m_{j_1,\ldots ,j_m} − \sum^{m-1}_{l=0} \mathbf{K}_{j_1,\ldots ,j_m} \mathbf{A}^{m,l}_{j_1,\ldots ,j_m} \boldsymbol{η}_{j_1,\ldots ,j_l}
\end{align*} \tag{8}
K ~ j 1 , … , j m − 1 = K j 1 , … , j m − 1 + B j 1 , … , j m m ′ V j 1 , … , j m − 1 B j 1 , … , j m m = K j 1 , … , j m − 1 + A j 1 , … , j m m , m ν ~ j 1 , … , j m = K ~ j 1 , … , j m ( B j 1 , … , j m m ′ V j 1 , … , j m − 1 ( y M ( S j 1 , … , j m ) − l = 0 ∑ m − 1 B j 1 , … , j m l η j 1 , … , j l )) = K ~ j 1 , … , j m ω j 1 , … , j m m − l = 0 ∑ m − 1 K j 1 , … , j m A j 1 , … , j m m , l η j 1 , … , j l ( 8 )
其中:
A j 1 , … , j m k , l : = B j 1 , … , j m k ′ V j 1 , … , j m − 1 B j 1 , … , j m l = ∑ j m + 1 = 1 J A ~ j 1 , … , j m + 1 k , l ω j 1 , … , j m k : = B j 1 , … , j m k ′ V j 1 , … , j m − 1 y M ( S j 1 , … , j m ) = ∑ j m + 1 = 1 J ω ~ j 1 , … , j m + 1 k k ≤ l = 0 , … , m (9) \begin{align*}
\mathbf{A}^{k,l}_{j_1,\ldots ,j_m} &:= {\mathbf{B}^k_{j_1,\ldots ,j_m}}^{\prime} \mathbf{V}^{-1}_{j_1,\ldots ,j_m} \mathbb{B}^l_{j_1,\ldots ,j_m} = \sum^{J}_{j_{m+1}=1} \tilde{\mathbf{A}}^{k,l}_{j_1,\ldots ,j_{m+1}} \\
\boldsymbol{ω}^k_{j_1,\ldots ,j_m} &:= {\mathbf{B}^k_{j_1,\ldots ,j_m}}^{\prime} \mathbf{V}^{-1}_{j_1,\ldots ,j_m} \mathbf{y}_M(\mathcal{S}_{j_1,\ldots ,j_m}) = \sum^{J}_{j_{m+1}=1} \tilde{\boldsymbol{ω}}^k_{j_1,\ldots ,j_{m+1}}\\
&k \leq l = 0,\ldots , m
\end{align*} \tag{9}
A j 1 , … , j m k , l ω j 1 , … , j m k := B j 1 , … , j m k ′ V j 1 , … , j m − 1 B j 1 , … , j m l = j m + 1 = 1 ∑ J A ~ j 1 , … , j m + 1 k , l := B j 1 , … , j m k ′ V j 1 , … , j m − 1 y M ( S j 1 , … , j m ) = j m + 1 = 1 ∑ J ω ~ j 1 , … , j m + 1 k k ≤ l = 0 , … , m ( 9 )
对于 m = M − 1 , M − 2 , … , 0 m = M − 1, M − 2,\ldots , 0 m = M − 1 , M − 2 , … , 0
A ~ j 1 , … , j m k , l : = B j 1 , … , j m k ′ Σ j 1 , … , j m − 1 B j 1 , … , j m l = A j 1 , … , j m k , l − A j 1 , … , j m k , m K ~ j 1 , … , j m A j 1 , … , j m m , l ω ~ j 1 , … , j m k : = B j 1 , … , j m k ′ Σ j 1 , … , j m − 1 y ( S j 1 , … , j m ) = ω j 1 , … , j m k − A j 1 , … , j m k , m K ~ j 1 , … , j m ω j 1 , … , j m m (10) \begin{align*}
&\tilde{\mathbf{A}}^{k,l}_{j_1,\ldots ,j_m} := {\mathbf{B}^k_{j_1,\ldots ,j_m}}^{\prime} \boldsymbol{\Sigma}^{−1}_{j_1,\ldots ,j_m} \mathbb{B}^l_{j_1,\ldots ,j_m} = \mathbf{A}^{k,l}_{j_1,\ldots ,j_m} − \mathbf{A}^{k,m}_{j_1,\ldots ,j_m} \tilde{\mathbf{K}}_{j_1,\ldots ,j_m} \mathbf{A}^{m,l}_{j_1,\ldots ,j_m}\\
&\tilde{\boldsymbol{ω}}^k_{j_1,\ldots ,j_m} := {\mathbf{B}^k_{j_1,\ldots ,j_m}}^{\prime} \boldsymbol{\Sigma}^{-1}_{j_1,\ldots ,j_m} \mathbf{y}(\mathcal{S}_{j_1,\ldots ,j_m} ) = \boldsymbol{ω}^k_{j_1,\ldots ,j_m} − \mathbf{A}^{k,m}_{j_1,\ldots ,j_m} \tilde{\mathbf{K}}_{j_1,\ldots ,j_m} \boldsymbol{ω}^m_{j_1,\ldots ,j_m}
\end{align*} \tag{10}
A ~ j 1 , … , j m k , l := B j 1 , … , j m k ′ Σ j 1 , … , j m − 1 B j 1 , … , j m l = A j 1 , … , j m k , l − A j 1 , … , j m k , m K ~ j 1 , … , j m A j 1 , … , j m m , l ω ~ j 1 , … , j m k := B j 1 , … , j m k ′ Σ j 1 , … , j m − 1 y ( S j 1 , … , j m ) = ω j 1 , … , j m k − A j 1 , … , j m k , m K ~ j 1 , … , j m ω j 1 , … , j m m ( 10 )
在实践中,式 (10) 中的数量直接根据 m = M m = M m = M m = M − 1 , … , 0 m = M − 1,\ldots , 0 m = M − 1 , … , 0 式 (9)–(10) 的证明使用 Sherman-Morrison-Woodbury 公式 很简单(Sherman 和 Morrison,1950;Woodbury,1950;Henderson 和 Searle,1981):
Σ j 1 , … , j m − 1 = V j 1 , … , j m − 1 − V j 1 , … , j m − 1 B j 1 , … , j m m K ~ j 1 , … , j m B j 1 , … , j m m ′ V j 1 , … , j m − 1 (11) \boldsymbol{\Sigma}^{-1}_{j_1,\ldots ,j_m} = \mathbf{V}^{-1}_{j_1,\ldots ,j_m} − \mathbf{V}^{-1}_{j_1,\ldots ,j_m} \mathbf{B}^m_{j_1,\ldots ,j_m} \tilde{\mathbf{K}}_{j_1,\ldots ,j_m} {\mathbf{B}^m_{j_1,\ldots ,j_m}}^{\prime} \mathbf{V}^{-1}_{j_1,\ldots ,j_m} \tag{11}
Σ j 1 , … , j m − 1 = V j 1 , … , j m − 1 − V j 1 , … , j m − 1 B j 1 , … , j m m K ~ j 1 , … , j m B j 1 , … , j m m ′ V j 1 , … , j m − 1 ( 11 )
3.3 参数推断
M-RA 的推断基于 L M ( θ ) L_M(\boldsymbol{\theta}) L M ( θ ) y M ( S ) ∼ N n ( 0 , Σ ) \mathbf{y}_M(\mathcal{S}) \sim \mathcal{N}_n(\mathbf{0}, \boldsymbol{\Sigma}) y M ( S ) ∼ N n ( 0 , Σ ) Σ = Σ ( θ ) \boldsymbol{\Sigma} = \boldsymbol{\Sigma}(\boldsymbol{\theta}) Σ = Σ ( θ ) 式 (5) 中给出的 M-RA 协方差矩阵 m = 0 m = 0 m = 0 θ \boldsymbol{\theta} θ
− 2 log L M ( θ ) = log ∣ Σ ∣ + y M ( S ) ′ Σ − 1 y M ( S ) −2 \log L_M(\boldsymbol{\theta}) = \log |\boldsymbol{\Sigma}| + {\mathbf{y}_M(\mathcal{S})}^{\prime} \boldsymbol{\Sigma}^{-1} \mathbf{y}_M(\mathcal{S})
− 2 log L M ( θ ) = log ∣ Σ ∣ + y M ( S ) ′ Σ − 1 y M ( S )
这种可能性可以使用 第 3.2 节 中的数量来计算。我们有 − 2 log L M ( θ ) = d + u −2 \log L_M(\boldsymbol{\theta}) = d + u − 2 log L M ( θ ) = d + u
d j 1 , … , j m : = log ∣ Σ j 1 , … , j m ∣ u j 1 , … , j m : = y M ( S j 1 , … , j m ) ′ Σ j 1 , … , j m − 1 y M ( S j 1 , … , j m ) m = 0 , 1 , … , M \begin{align*}
&d_{j_1,\ldots ,j_m} := \log |\boldsymbol{\Sigma}_{j_1,\ldots ,j_m} |\\
&u_{j_1,\ldots ,j_m} := \mathbf{y}_M(\mathcal{S}_{j_1,\ldots ,j_m})^{\prime} \boldsymbol{\Sigma}^{-1}_{j_1,\ldots ,j_m} \mathbf{y}_M(\mathcal{S}_{j_1,\ldots ,j_m})\\
&m = 0, 1,\ldots , M
\end{align*}
d j 1 , … , j m := log ∣ Σ j 1 , … , j m ∣ u j 1 , … , j m := y M ( S j 1 , … , j m ) ′ Σ j 1 , … , j m − 1 y M ( S j 1 , … , j m ) m = 0 , 1 , … , M
对于 m = M m = M m = M m = M − 1 , … , 0 m = M − 1,\ldots , 0 m = M − 1 , … , 0
d j 1 , … , j m = log ∣ K ~ j 1 , … , j m − 1 ∣ − log ∣ K j 1 , … , j m − 1 ∣ + ∑ j m + 1 = 1 J d j 1 , … , j m + 1 u j 1 , … , j m = − ω j 1 , … , j m m ′ K ~ j 1 , … , j m ω j 1 , … , j m m + ∑ j m + 1 = 1 J u j 1 , … , j m + 1 \begin{align*}
&d_{j_1,\ldots ,j_m} = \log |\tilde{\mathbf{K}}^{-1}_{j_1,\ldots ,j_m} | − \log |\mathbf{K}^{-1}_{j_1,\ldots ,j_m} | + \sum^{J}_{j_{m+1}=1} d_{j_1,\ldots ,j_{m+1}} \\
&u_{j_1,\ldots ,j_m} = − {\boldsymbol{ω}^m_{j_1,\ldots ,j_m}}^{\prime} \tilde{\mathbf{K}}_{j_1,\ldots ,j_m} \boldsymbol{ω}^m_{j_1,\ldots ,j_m} + \sum^{J}_{j_{m+1}=1} u_{j_1,\ldots ,j_{m+1}}
\end{align*}
d j 1 , … , j m = log ∣ K ~ j 1 , … , j m − 1 ∣ − log ∣ K j 1 , … , j m − 1 ∣ + j m + 1 = 1 ∑ J d j 1 , … , j m + 1 u j 1 , … , j m = − ω j 1 , … , j m m ′ K ~ j 1 , … , j m ω j 1 , … , j m m + j m + 1 = 1 ∑ J u j 1 , … , j m + 1
可以使用矩阵行列式引理(例如,Harville, 1997, Thm. 18.1.1)和 Sherman-Morrison-Woodbury 公式导出 式(11)。
总之,M-RA 对数似然可以写成对数行列式和仅涉及 r × r r\times r r × r θ \boldsymbol{\theta} θ
3.4 空间预测
空间预测可以在参数推断完成后单独进行。在频率论者的背景下,预测只需要进行一次,就可以得到最终的参数估计值。在贝叶斯框架中,只能对细化的 MCMC 链进行参数推断,或者在粒子采样器的情况下对具有相当大重量的粒子进行参数推断。
隐式调节参数向量 θ \boldsymbol{\theta} θ S P \mathcal{S}^P S P y M ( S P ) ∣ y M ( S ) \mathbf{y}_M(\mathcal{S}^P) | \mathbf{y}_M(\mathcal{S}) y M ( S P ) ∣ y M ( S ) S j 1 , … , j M P \mathcal{S}^P_{j_1,\ldots ,j_M} S j 1 , … , j M P D j 1 , … , j M \mathcal{D}_{j_1,\ldots ,j_M} D j 1 , … , j M 式(6) 的先验预测量,
U j 1 , … , j M l : = v l ( S j 1 , … , j M P , Q j 1 , … , j l ) = C 0 ( S j 1 , … , j M P , Q j 1 , … , j l ) − ∑ k = 0 l − 1 U j 1 , … , j M k K j 1 , … , j k W j 1 , … , j l k ′ \mathbf{U}^l_{j_1,\ldots ,j_M} := v_l(\mathcal{S}^P_{j_1,\ldots ,j_M}, \mathcal{Q}_{j_1,\ldots ,j_l} ) = C_0(\mathcal{S}^P_{j_1,\ldots ,j_M}, \mathcal{Q}_{j_1,\ldots ,j_l}) − \sum^{l-1}_{k=0} \mathbf{U}^k_{j_1,\ldots ,j_M} \mathbf{K}_{j_1,\ldots ,j_k} {\mathbf{W}^k_{j_1,\ldots ,j_l}}^{\prime}
U j 1 , … , j M l := v l ( S j 1 , … , j M P , Q j 1 , … , j l ) = C 0 ( S j 1 , … , j M P , Q j 1 , … , j l ) − k = 0 ∑ l − 1 U j 1 , … , j M k K j 1 , … , j k W j 1 , … , j l k ′
对于 l = 0 , … , M l = 0,\ldots , M l = 0 , … , M L j 1 , … , j M M : = v M ( S j 1 , … , j M P , S j 1 , … , j M ) = U j 1 , … , j M M L^M_{j_1,\ldots ,j_M} := v_M (\mathcal{S}^P_{j_1,\ldots ,j_M} , \mathcal{S}_{j_1,\ldots ,j_M} ) = \mathbf{U}^M_{j_1,\ldots ,j_M} L j 1 , … , j M M := v M ( S j 1 , … , j M P , S j 1 , … , j M ) = U j 1 , … , j M M
V j 1 , … , j M P : = v M ( S j 1 , … , j M P , S j 1 , … , j M P ) = C 0 ( S j 1 , … , j M P , S j 1 , … , j M P ) − ∑ k = 0 l − 1 U j 1 , … , j M k K j 1 , … , j k U j 1 , … , j M k ′ \mathbf{V}^P_{j_1,\ldots,j_M} := v_M (\mathcal{S}^P_{j_1,\ldots ,j_M} , \mathcal{S}^P_{j_1,\ldots ,j_M} ) = C_0(\mathcal{S}^P_{j_1,\ldots ,j_M} , \mathcal{S}^P_{j_1,\ldots ,j_M}) − \sum^{l −1}_{k=0} \mathbf{U}^k_{j_1,\ldots ,j_M} \mathbf{K}_{j_1,\ldots ,j_k} {\mathbf{U}^k_{j_1,\ldots ,j_M}}^{\prime}
V j 1 , … , j M P := v M ( S j 1 , … , j M P , S j 1 , … , j M P ) = C 0 ( S j 1 , … , j M P , S j 1 , … , j M P ) − k = 0 ∑ l − 1 U j 1 , … , j M k K j 1 , … , j k U j 1 , … , j M k ′
然后可以使用以下命题获得空间预测。
【命题 2】 后验预测分布可以写成:
y M ( S j 1 , … , j M P ) ∣ y M ( S ) = ∑ m = 0 M − 1 B ~ j 1 , … , j M m + 1 , m η ~ j 1 , … , j m + δ ~ j 1 , … , j M (12) \mathbf{y}_M(\mathcal{S}^P_{j_1,\ldots ,j_M}) | \mathbf{y}_M(\mathcal{S}) = \sum^{M-1}_{m=0} \tilde{\mathbf{B}}^{m+1,m}_{j_1,\ldots ,j_M} \tilde{\boldsymbol{η}}_{j_1,\ldots ,j_m} + \tilde{\boldsymbol{\delta}}_{j_1,\ldots ,j_M} \tag{12}
y M ( S j 1 , … , j M P ) ∣ y M ( S ) = m = 0 ∑ M − 1 B ~ j 1 , … , j M m + 1 , m η ~ j 1 , … , j m + δ ~ j 1 , … , j M ( 12 )
其中
η ~ j 1 , … , j m ∼ i n d . N r ( K ~ j 1 , … , j m ω j 1 , … , j m m , K ~ j 1 , … , j m ) δ ~ j 1 , … , j M ∼ i n d . N ( L j 1 , … , j M M Σ j 1 , … , j M − 1 y M ( S j 1 , … , j M ) , V j 1 , … , j M P − L j 1 , … , j M M Σ j 1 , … , j M − 1 L j 1 , … , j M M ′ ) \begin{align*}
&\tilde{\boldsymbol{η}}_{j_1,\ldots ,j_m} \stackrel{ind.} \sim \mathcal{N}_r(\tilde{\mathbf{K}}_{j_1,\ldots ,j_m} \boldsymbol{ω}^m_{j_1,\ldots ,j_m}, \tilde{\mathbf{K}}_{j_1,\ldots ,j_m})\\
&\tilde{\boldsymbol{\delta}}_{j_1,\ldots ,j_M} \stackrel{ind.} \sim \mathcal{N}(\mathbf{L}^M_{j_1,\ldots ,j_M} \boldsymbol{\Sigma}^{-1}_{j_1,\ldots ,j_M} \mathbf{y}_M(\mathcal{S}_{j_1,\ldots ,j_M}), \mathbf{V}^P_{j_1,\ldots ,j_M} − \mathbf{L}^M_{j_1,\ldots ,j_M} \boldsymbol{\Sigma}^{-1}_{j_1,\ldots ,j_M} {\mathbf{L}^M_{j_1,\ldots ,j_M}}^{\prime})
\end{align*}
η ~ j 1 , … , j m ∼ in d . N r ( K ~ j 1 , … , j m ω j 1 , … , j m m , K ~ j 1 , … , j m ) δ ~ j 1 , … , j M ∼ in d . N ( L j 1 , … , j M M Σ j 1 , … , j M − 1 y M ( S j 1 , … , j M ) , V j 1 , … , j M P − L j 1 , … , j M M Σ j 1 , … , j M − 1 L j 1 , … , j M M ′ )
and the “posterior basis-function matrices” are given by
B ~ j 1 , … , j M l , k : = b j 1 , … , j k ( S j 1 , … , j M P ) − L j 1 , … , j M l Σ j 1 , … , j l − 1 B j 1 , … , j l k = B ~ j 1 , … , j M l + 1 , k − B ~ j 1 , … , j M l + 1 , l K ~ j 1 , … , j l A j 1 , … , j l l , k (13) \tilde{\mathbf{B}}^{l,k}_{j_1,\ldots ,j_M} := \mathbf{b}_{j_1,\ldots ,j_k} (\mathcal{S}^P_{j_1,\ldots ,j_M}) − \mathbf{L}^l_{j_1,\ldots ,j_M} \boldsymbol{\Sigma}^{-1}_{j_1,\ldots ,j_l} \mathbf{B}^k_{j_1,\ldots ,j_l} = \tilde{\mathbf{B}}^{l+1,k}_{j_1,\ldots ,j_M} − \tilde{\mathbf{B}}^{l+1,l}_{j_1,\ldots ,j_M} \tilde{\mathbf{K}}_{j_1,\ldots ,j_l} \mathbf{A}^{l,k}_{j_1,\ldots ,j_l} \tag{13}
B ~ j 1 , … , j M l , k := b j 1 , … , j k ( S j 1 , … , j M P ) − L j 1 , … , j M l Σ j 1 , … , j l − 1 B j 1 , … , j l k = B ~ j 1 , … , j M l + 1 , k − B ~ j 1 , … , j M l + 1 , l K ~ j 1 , … , j l A j 1 , … , j l l , k ( 13 )
对于 k = 0 , 1 , … , l − 1 k = 0, 1,\ldots , l − 1 k = 0 , 1 , … , l − 1
因此,式 (12) 中的后验预测分布与 式 (3) 中的(先验)M-RA 过程具有相同的形式。这允许计算和存储联合后验预测分布。通常,人们感兴趣的是这种联合后验预测分布的摘要,例如每个预测位置的边际后验预测分布。实际上,式 (13) 中的后验基函数矩阵直接根据 l = M l = M l = M l = M − 1 , … , 0 l = M − 1, \ldots,0 l = M − 1 , … , 0
3.5 分布式计算
M-RA 的一个主要优点是它非常适合现代计算环境,因为计算可以以分布式方式进行,在大量节点上几乎没有通信开销,每个节点只处理一小部分数据。
更具体地说,假设我们有节点 { N j 1 , … , j m : j 1 , … , j m = 1 , … , J ; m = 0 , 1 , … , M } \{\mathcal{N}_{j_1,\ldots ,j_m} : j_1,\ldots , j_m = 1,\ldots , J; m = 0, 1,\ldots , M \} { N j 1 , … , j m : j 1 , … , j m = 1 , … , J ; m = 0 , 1 , … , M } 图 3 所示。每个节点 N j 1 , … , j m \mathcal{N}_{j_1,\ldots ,j_m} N j 1 , … , j m r r r Q j 1 , … , j m \mathcal{Q}_{j_1,\ldots ,j_m} Q j 1 , … , j m D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m r × r r \times r r × r N j 1 , … , j m \mathcal{N}_{j_1,\ldots ,j_m} N j 1 , … , j m r × r r \times r r × r K ~ j 1 , … , j m \tilde{\mathbf{K}}_{j_1,\ldots ,j_m} K ~ j 1 , … , j m 式 (10) 中的数量,后者可以并行化,如果该节点有多个核心。与每个节点 N j 1 , … , j m \mathcal{N}_{j_1,\ldots ,j_m} N j 1 , … , j m O ( J m 2 r 2 ) \mathcal{O}(Jm^2r^2) O ( J m 2 r 2 ) 式 (9) 中的数量。每个分辨率的节点/子区域的计算可以完全并行进行。
对于位置 S P \mathcal{S}^P S P N j 1 , … , j M \mathcal{N}_{j_1,\ldots ,j_M} N j 1 , … , j M S j 1 , … , j M P \mathcal{S}^P_{j_1,\ldots ,j_M} S j 1 , … , j M P D j 1 , … , j M \mathcal{D}_{j_1,\ldots ,j_M} D j 1 , … , j M 式(13) 中的 “后验基函数矩阵”。
图 3:J = 2 J = 2 J = 2 r = 5 r = 5 r = 5 N j 1 , … , j m \mathcal{N}_{j_1,\ldots,j_m} N j 1 , … , j m Q j 1 , … , j m Q_{j_1,\ldots,j_m} Q j 1 , … , j m j m = 1 , 2 j_m = 1, 2 j m = 1 , 2 m = 0 , 1 , 2 m = 0, 1, 2 m = 0 , 1 , 2
3.6 计算复杂度
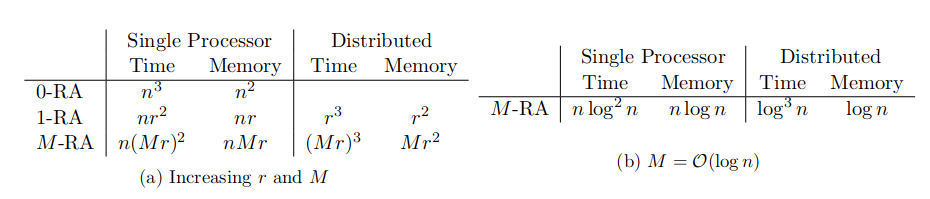
请记住,为了简单起见,我们在此假设每个区域 D j 1 , … , j m \mathcal{D}_{j_1,\ldots ,j_m} D j 1 , … , j m r = n J M r = \frac{n}{J^M} r = J M n J J J ∑ m = 0 M J m < 2 J M \sum^{M}_{m=0} J^m < 2J^M ∑ m = 0 M J m < 2 J M 式 (10) 中获得矩阵 A ~ j 1 , … , j m k , l \tilde{\mathbf{A}}^{k,l}_{j_1,\ldots ,j_m} A ~ j 1 , … , j m k , l r × r r \times r r × r K ~ j 1 , … , j m \tilde{\mathbf{K}}_{j_1,\ldots ,j_m} K ~ j 1 , … , j m r × r r \times r r × r O ( m 2 ) \mathcal{O}(m^2) O ( m 2 ) O ( J M M 2 r 3 ) = O ( n r 2 M 2 ) \mathcal{O}(J^M M^2r^3) = \mathcal{O}(nr^2M^2) O ( J M M 2 r 3 ) = O ( n r 2 M 2 ) O ( n r M ) \mathcal{O}(nrM) O ( n r M )
当 M-RA 在具有大量节点的分布式环境中实现时(如上文 第 3.5 节),整体时间复杂度为 O ( M 3 r 3 ) \mathcal{O}(M^3r^3) O ( M 3 r 3 ) O ( M r 2 ) \mathcal{O}(M r2) O ( M r 2 ) O ( M 2 r 2 ) \mathcal{O}(M^2r^2) O ( M 2 r 2 )
因此,具有 r r r M r M r M r 图 1 )。正如下面 第 4.1 节 中进一步探讨的那样,随着 n n n r r r n n n r r r M M M n n n M = O ( log J n ) M = \mathcal{O}(\log_J n) M = O ( log J n ) J J J M M M J J J O ( n log 2 n ) \mathcal{O}(n \log^2 n) O ( n log 2 n ) O ( n log n ) \mathcal{O}(n \log n) O ( n log n ) O ( log 3 n ) \mathcal{O}(\log^3 n) O ( log 3 n ) O ( log n ) \mathcal{O}(\log n) O ( log n ) O ( log 2 n ) \mathcal{O}(\log^2 n) O ( log 2 n )
只要每个终端区域的预测位置数量与观测到的位置数量(即 ∣ S j 1 , … , j M P ∣ = O ( r ) |\mathcal{S}^P_{j_1,\ldots ,j_M} | = \mathcal{O}(r) ∣ S j 1 , … , j M P ∣ = O ( r ) O ( M r 2 J M ) = O ( n M r ) \mathcal{O}(M r^2J^M ) = \mathcal{O}(nM r) O ( M r 2 J M ) = O ( n M r ) O ( M r 2 ) \mathcal{O}(M r^2) O ( M r 2 ) M = O ( log n ) M = \mathcal{O}(\log n) M = O ( log n ) O ( n log n ) \mathcal{O}(n \log n) O ( n log n ) O ( log n ) \mathcal{O}(\log n) O ( log n )
如 表 1(b) 中总结的那样,如果我们让 M M M log n \log n log n n n n
表 1:M -RA 的时间和内存复杂度及其特殊情况、常规克里金法 (0-RA) 和全尺度近似 (1-RA),在单台计算机和第 3.5 节的分布式设置中
4 数值比较与说明
4.1 模拟研究
4.2 总可降水量分析
5 结论和未来工作
我们提出了多分辨率近似 (M-RA),这是一种用任何协方差函数近似高斯过程的新技术。 M-RA 本质上是多种分辨率下许多空间基函数的线性组合。基函数权重的精度矩阵具有多分辨率块稀疏结构,允许可扩展的推断和分布式计算。因为我们的方法中的基函数是针对给定的协方差函数最佳选择的,所以这可以提供对其他多分辨率方法的进一步了解,在这些方法中,基函数是以更特别的方式选择的。
M-RA 与 Sang 等 (2011 [38]
我们正计划提供用户友好的软件,为 M-RA 提供良好的默认选择,并且可以在台式计算机和高性能计算环境中运行。利用后者的分布式内存架构,原则上应该允许将 M-RA 应用于具有数亿个观测值的数据集,因为许多卫星仪器现在能够每天生成。
M-RA 不仅近似于数据协方差矩阵,而且它本身就是一个有效的高斯过程。因此,通过将 M-RA 过程嵌入分层模型中,可以扩展到更复杂的场景(例如,Cressie 和 Wikle,2011 [7]
同样令人感兴趣的是 M-RA 的时空版本。因为可以存储和传播整个联合后验预测分布,所以可以扩展 M-RA 以允许在大规模时空状态空间模型中进行卡尔曼滤波器类型的推断(这对其他稀疏精度方法具有挑战性,例如正如 Lindgren 等,2011 年 [32] [10] [28]
参考文献
[1] Banerjee, S., Gelfand, A. E., Finley, A. O., and Sang, H. (2008). Gaussian predictive process models for large spatial data sets. Journal of the Royal Statistical Society, Series B, 70(4):825–848. [2] Bevilacqua, M., Gaetan, C., Mateu, J., and Porcu, E. (2012). Estimating space and space-time covariance functions for large data sets: A weighted composite likelihood approach. Journal of the American Statistical Association, 107(497):268–280. [3] Calder, C. A. (2007). Dynamic factor process convolution models for multivariate space-time data with application to air quality assessment. Environmental and Ecological Statistics, 14(3):229–247. [4] Caragea, P. C. and Smith, R. L. (2007). Asymptotic properties of computationally efficient alternative estimators for a class of multivariate normal models. Journal of Multivariate Analysis, 98(7):1417–1440. [5] Chui, C. (1992). An Introduction to Wavelets. Academic Press. [6] Cressie, N. and Johannesson, G. (2008). Fixed rank kriging for very large spatial data sets. Journal of the Royal Statistical Society, Series B, 70(1):209–226. [7] Cressie, N. and Wikle, C. K. (2011). Statistics for Spatio-Temporal Data. Wiley, Hoboken, NJ. [8] Curriero, F. and Lele, S. (1999). A composite likelihood approach to semivariogram estimation. Journal of Agricultural, Biological, and Environmental Statistics, 4(1):9–28. [9] Eidsvik, J., Shaby, B. A., Reich, B. J., Wheeler, M., and Niemi, J. (2014). Estimation and prediction in spatial models with block composite likelihoods using parallel computing. Journal of Computational and Graphical Statistics, 23(2):295–315. [10] Evensen, G. (1994). Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. Journal of Geophysical Research, 99(C5):10143–10162. [11] Forsythe, J. M., Dodson, J. B., Partain, P. T., Kidder, S. Q., and Haar, T. H. V. (2012). How total precipitable water vapor anomalies relate to cloud vertical structure. Journal of Hydrometeorology, 13(2):709721. [12] Fuentes, M. (2007). Approximate likelihood for large irregularly spaced spatial data. Journal of the American Statistical Association, 102(477):321–331. [13] Furrer, R., Genton, M. G., and Nychka, D. W. (2006). Covariance tapering for interpolation of large spatial datasets. Journal of Computational and Graphical Statistics, 15(3):502–523. [14] Gneiting, T. and Katzfuss, M. (2014). Probabilistic forecasting. Annual Review of Statistics and Its Application, 1(1):125–151. [15] Golub, G. H. and Van Loan, C. F. (2012). Matrix Computations. JHU Press, 4th edition. [16] Gramacy, R. and Lee, H. (2008). Bayesian treed Gaussian process models with an application to computer modeling. Journal of the American Statistical Association, 103(483):1119–1130. [17] Halko, N., Martinsson, P., and Tropp, J. (2011). Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM Review, 53(2):217–288. [18] Harville, D. A. (1997). Matrix Algebra From a Statistician’s Perspective. Springer, New York, NY. [19] Henderson, H. and Searle, S. (1981). On deriving the inverse of a sum of matrices. SIAM Review, 23(1):53–60. [20] Higdon, D. (1998). A process-convolution approach to modelling temperatures in the North Atlantic Ocean. Environmental and Ecological Statistics, 5(2):173–190. [21] Hoeting, J. A., Madigan, D., Raftery, A. E., and Volinsky, C. T. (1999). Bayesian model averaging: A tutorial. Statistical Science, 14(4):382–417. [22] Johannesson, G., Cressie, N., and Huang, H.-C. (2007). Dynamic multi-resolution spatial models. Environmental and Ecological Statistics, 14(1):5–25. [23] Katzfuss, M. (2013). Bayesian nonstationary spatial modeling for very large datasets. Environmetrics, 24(3):189–200. [24] Katzfuss, M. and Cressie, N. (2009). Maximum likelihood estimation of covariance parameters in the spatialrandom-effects model. In Proceedings of the Joint Statistical Meetings, pages 3378–3390, Alexandria, VA. American Statistical Association. [25] Katzfuss, M. and Cressie, N. (2011). Spatio-temporal smoothing and EM estimation for massive remotesensing data sets. Journal of Time Series Analysis, 32(4):430–446. [26] Katzfuss, M. and Cressie, N. (2012). Bayesian hierarchical spatio-temporal smoothing for very large datasets. Environmetrics, 23(1):94–107. [27] Katzfuss, M. and Hammerling, D. (2014). Parallel inference for massive distributed spatial data using low-rank models. arXiv:1402.1472. [28] Katzfuss, M., Stroud, J. R., and Wikle, C. K. (2015). Understanding the ensemble Kalman filter. The American Statistician, forthcoming. [29] Kaufman, C. G., Schervish, M., and Nychka, D. W. (2008). Covariance tapering for likelihood-based estimation in large spatial data sets. Journal of the American Statistical Association, 103(484):1545–1555. [30] Kidder, S. Q. and Jones, A. S. (2007). A blended satellite total precipitable water product for operational forecasting. Journal of Atmospheric and Oceanic Technology, 24(1):74–81. [31] Lemos, R. T. and Sans ́o, B. (2009). A spatio-temporal model for mean, anomaly, and trend fields of North Atlantic sea surface temperature. Journal of the American Statistical Association, 104(485):5–18. [32] Lindgren, F., Rue, H., and Lindstr ̈om, J. (2011). An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach. Journal of the Royal Statistical Society, Series B, 73(4):423–498. [33] Mardia, K., Goodall, C., Redfern, E., and Alonso, F. (1998). The kriged Kalman filter. Test, 7(2):217–282. [34] McLeod, A. I., Yu, H., and Krougly, Z. (2007). Algorithms for linear time series analysis: With R package. Journal of Statistical Software, 23(5). [35] Nychka, D. W., Bandyopadhyay, S., Hammerling, D., Lindgren, F., and Sain, S. R. (2015). A multi-resolution Gaussian process model for the analysis of large spatial data sets. Journal of Computational and Graphical Statistics, in press. [36] Quinonero Candela, J. and Rasmussen, C. (2005). A unifying view of sparse approximate Gaussian process regression. Journal of Machine Learning Research, 6:1939–1959. [37] Sang, H. and Huang, J. Z. (2012). A full scale approximation of covariance functions. Journal of the Royal Statistical Society, Series B, 74(1):111–132. [38] Sang, H., Jun, M., and Huang, J. Z. (2011). Covariance approximation for large multivariate spatial datasets with an application to multiple climate model errors. Annals of Applied Statistics, 5(4):2519–2548. [39] Schlather, M., Malinowski, A., Menck, P. J., Oesting, M., and Strokorb, K. (2015). Analysis, simulation and prediction of multivariate random fields with package RandomFields. Journal of Statistical Software, 63(8):1–25. [40] Shaby, B. A. and Ruppert, D. (2012). Tapered Covariance: Bayesian Estimation and Asymptotics. Journal of Computational and Graphical Statistics, 21(2):433–452. [41] Sherman, J. and Morrison, W. (1950). Adjustment of an inverse matrix corresponding to a change in one element of a given matrix. Annals of Mathematical Statistics, 21(1):124–127. [42] Snelson, E. and Ghahramani, Z. (2007). Local and global sparse Gaussian process approximations. In Artificial Intelligence and Statistics 11 (AISTATS). [43] Stein, M. L. (2011). 2010 Rietz lecture: When does the screening effect hold? Annals of Statistics, 39(6):2795–2819. [44] Stein, M. L. (2014). Limitations on low rank approximations for covariance matrices of spatial data. Spatial Statistics, 8:1–19. [45] Stein, M. L., Chen, J., and Anitescu, M. (2013). Stochastic approximation of score functions for Gaussian processes. The Annals of Applied Statistics, 7(2):1162–1191. [46] Stein, M. L., Chi, Z., and Welty, L. (2004). Approximating likelihoods for large spatial data sets. Journal of the Royal Statistical Society: Series B, 66(2):275–296. [47] Vecchia, A. (1988). Estimation and model identification for continuous spatial processes. Journal of the Royal Statistical Society, Series B, 50(2):297–312. [48] Woodbury, M. (1950). Inverting modified matrices. Memorandum Report 42, Statistical Research Group, Princeton University.