第八章:近似贝叶斯计算
Contents
第八章:近似贝叶斯计算¶
在本章中,我们讨论 近似贝叶斯计算( Approximate Bayesian Computation , ABC )。近似贝叶斯计算中的 “近似” 指缺乏显式的似然函数,而非 MCMC 或变分推理等后验近似推断方法。近似贝叶斯计算方法的另一个常见并且更明确的名称是 无似然方法。尽管有很多学者认为这两个术语之间存在区别,不能作为可以互换的概念,但无似然方法这个名称还是更容易让初识的人理解。
当没有明确的似然表达式时,近似贝叶斯计算方法可能会非常有用,但需要有一个能够生成合成数据的参数化 模拟器。这个模拟器有一个或多个未知参数,我们想知道哪一组参数生成的合成数据 足够接近 观测数据,然后再计算这组参数的后验分布。
近似贝叶斯计算方法在生物科学中变得越来越普遍,特别是在系统生物学、流行病学、生态学和群体遗传学等子领域[84]。但其也可用于其他领域,因为近似贝叶斯计算能够提供一种解决许多实际问题的灵活方式。
应用的多样性也反映在近似贝叶斯计算的 Python 软件包中 [85, 86, 87] 。不过,额外的近似层也带来了一系列困难,主要是:在缺乏似然的情况下,足够接近到底指什么?如何能够实际计算一个近似的后验?
我们将在本章中从一般性角度讨论这些挑战。强烈建议有兴趣将近似贝叶斯计算方法应用于自身问题的读者,用自己领域知识中的例子来补充本章内容。
8.1 超越似然¶
根据贝叶斯定理( 公式 (1) ),要计算后验,需要两个基本成分:先验和似然。但是,对于某些特定问题,可能无法以封闭形式表达似然,或者计算似然的成本过高。这对于贝叶斯热爱者来说,似乎进入了一条死胡同。但如果能够以某种方式生成合成数据,情况可能就会有所不同。特别是当此类合成数据能够与真实观测数据足够相似时,似乎就能够用该数据生成过程来近似真实数据的似然。这种合成数据生成器通常被称为 模拟器。从近似贝叶斯计算方法角度来看,模拟器就是一个黑盒子,我们在一侧输入参数值,并从另一侧获取模拟数据。这里的复杂性在于:不确定哪些输入参数足以生成与观测数据相似的合成数据。
所有近似贝叶斯计算方法共有的基本概念是:用能够计算某种距离的 \(\delta\) 函数替换似然,或者更一般地说, 计算观测数据 \(Y\) 与合成数据 \(\hat Y\) (由参数化模拟器 \(Sim\) 生成)之间的某种差异。
我们的目标是使用函数 \(\delta\) 来获得足够好的近似似然:
我们需要引入了一个容差参数 \(\epsilon\),因为对于大多数问题,生成与观测数据 \(Y\) 相等的合成数据集 \(\hat Y\) 几乎不可能 1 。 \(\epsilon\) 值越大,我们对 \(Y\) 和 \(\hat Y\) 之间的近似程度就越能容忍。一般来说,对于给定问题,较大的 \(\epsilon\) 值意味着对后验更粗略的近似。
在实践中,随着数据样本量或维度的增加,找到足够小的 \(\delta\) 值将越来越困难 2 。一个简单的解决方案是增加 \(\epsilon\) 的值,但这意味着增加了近似误差。因此,更好的解决方案可能是计算一个或多个统计量 \(S\) 之间的距离,而不是合成数据集和真实数据集之间的距离。
当然,使用统计量会给近似贝叶斯计算带来额外的误差源,除非该统计量对于模型参数 \(\theta\) 来说是充分统计量。不幸的是,并非所有情况都能满足这种要求。尽管如此,不充分统计量在实践中仍然非常有用。
在本章中,我们将探讨一些不同的距离和统计量,重点关注经过验证的一些方法。但一定要清楚,近似贝叶斯计算涉及许多不同领域、不同类型的模拟数据,因此此类方法很难一概而论。此外,文献进展非常迅速,因此本书将专注于构建必要的知识、技能和工具。
充分统计量
如果除了某个统计量之外,从同一样本计算的其他统计量无法提供有关该样本的更多信息,则该统计量对于模型参数而言是充分的,被称为充分统计量。换句话说,该统计量 足以 总结你的样本而不会丢失信息。
例如,给定来自具有期望值 \(\mu\) 和已知有限方差的高斯分布的独立同分布样本,样本的均值对于参数 \(\mu\) 来说是一个 充分统计量。请注意,均值无法说明离散度,因此其仅对参数 \(\mu\) 是充分的。
众所周知,对于独立同分布数据,具有充分统计量且维度与 \(\theta\) 相同的唯一分布来自于 指数族分布 [88, 89, 90, 91] 。对于其他类型的分布,充分统计量的维度会随着样本量的增加而增加。
近似近似的后验
执行 ABC 计算的大多数基础方法是按照一定概率做拒绝采样。我们将用 Fig. 132 以及对算法的抽象描述来逐步解释,如下所示。
从先验分布中抽取 \(\theta\) 的值作为提议。
将该值传递给模拟器并生成合成数据。
如果合成数据的距离 \(\delta\) 较阈值 \(\epsilon\) 更近,则保存提议的 \(\theta\),否则拒绝它。
重复直到获得所需数量的样本。
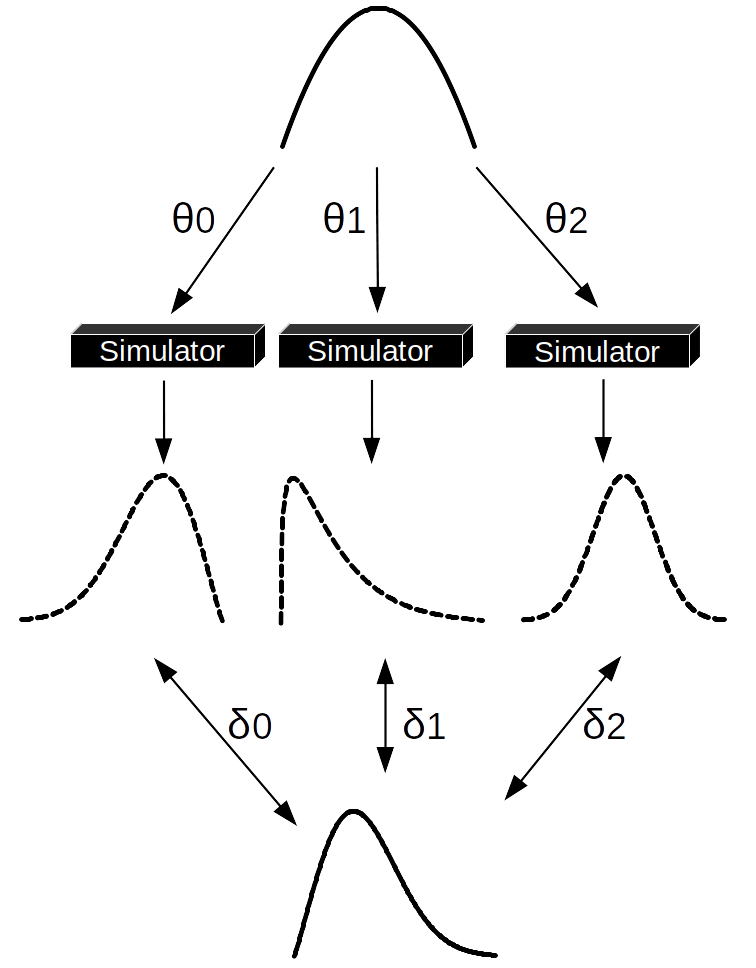
Fig. 132 近似贝叶斯计算拒绝采样器的一个步骤。¶
从先验分布(顶部)中抽取一组 \(\theta\) 值。将每个值都被传递给模拟器,模拟器生成合成数据集(虚线分布),然后比较合成数据与观测数据(底部)的分布。在这个例子中,只有 \(\theta_1\) 能够生成一个与观测数据足够接近的合成数据集,因此 \(\theta_0\) 和 \(\theta_2\) 被拒绝。请注意,如果仅使用统计量,则需要在第 \(2\) 步之后和第 \(3\) 步之前计算合成数据和观测数据的统计量信息。
ABC 拒绝采样器的主要缺点是:
如果先验分布与后验分布相差太大,我们会花费大部分时间提出将被拒绝的值。因此,更好的办法是从接近真实后验的分布中提出建议值。但通常来说,我们对后验的了解不够,无法手动执行此操作,但可以使用 序贯蒙特卡洛 (SMC) 方法来实现。
序贯蒙特卡洛是一种通用采样方法,就像 MCMC 方法一样。 但序贯蒙特卡洛也适用于执行近似贝叶斯计算,并被称为 “序贯蒙特卡洛-近似贝叶斯计算( SMC-ABC )” 。如果你想了解更多关于序贯蒙特卡洛方法的细节,可以参阅章节 11.9 推断方法,但要理解本章,暂时只需要知道序贯蒙特卡洛是通过在 \(s\) 个连续阶段中逐步增加辅助参数 \(\beta\) 的值 \(\{\beta_0=0 < \beta_1 < ... < \beta_s=1\}\) 实现的。其作法是:从先验( \(\beta = 0\) )开始采样,直到到达后验( \(\beta = 1\) )。因此,可以将 \(\beta\) 视为一个逐渐开启似然的参数。 \(\beta\) 的中间值序列由序贯蒙特卡洛方法自动计算。数据相对于先验的信息越多和(/或)后验几何形态越复杂,则序贯蒙特卡洛所采取的中间步骤就会越多。
Fig. 133 显示了一个假设的中间分布序列,从浅灰色的先验到蓝色的后验。
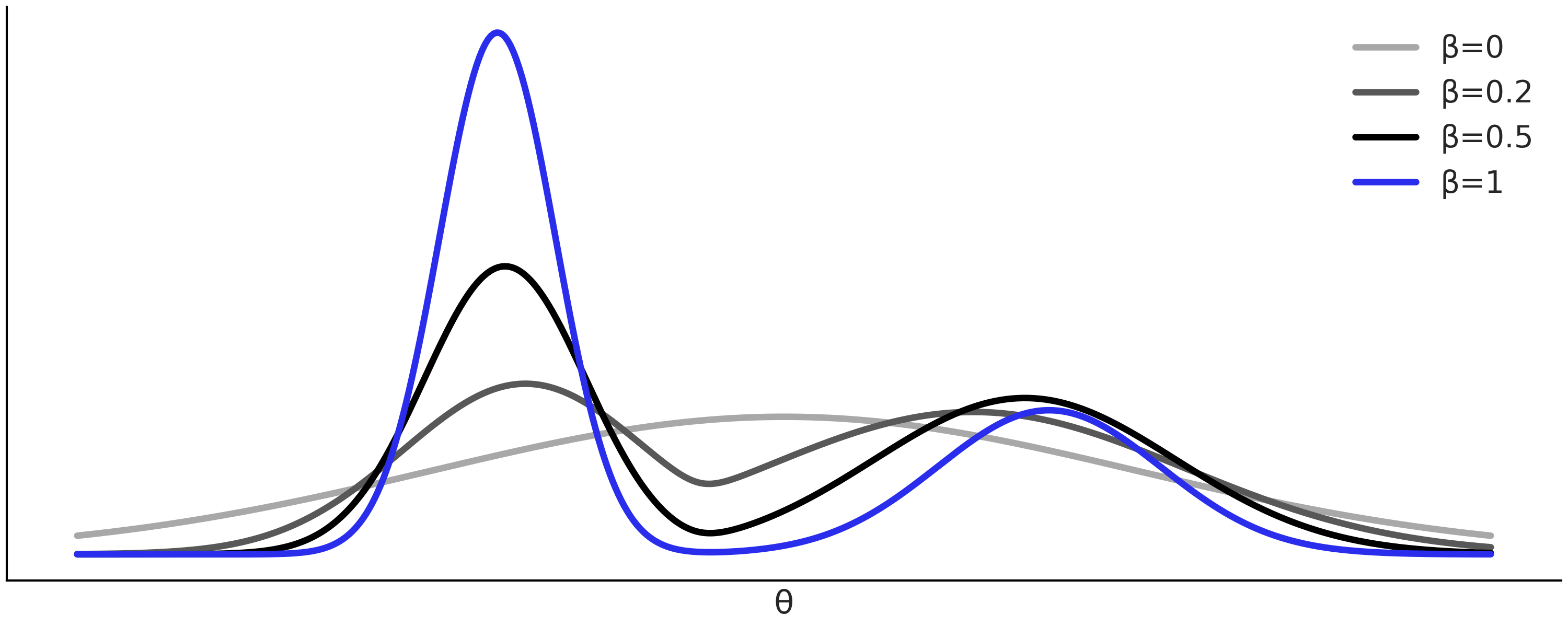
Fig. 133 序贯蒙特卡洛采样器探索的退火后验序列,从浅灰色的先验 ( \(\beta = 0\) ) 到蓝色的真实后验 ( \(\beta = 1\) )。开始时较低的 \(\beta\) 值有助于防止采样器卡在单一最值中。¶
8.3 用近似贝叶斯计算拟合一个高斯¶
让我们用一个简单的例子先热热身,从均值为 \(0\) 、标准差为 \(1\) 的高斯分布数据中估计均值和标准差。对于这个问题,我们可以拟合模型:
在 PYMC3 中编写此模型的方法见代码 gauss_nuts 。
with pm.Model() as gauss:
μ = pm.Normal("μ", mu=0, sigma=1)
σ = pm.HalfNormal("σ", sigma=1)
s = pm.Normal("s", μ, σ, observed=data)
trace_g = pm.sample()
使用 SMC-ABC 的等效模型见代码 gauss_abc 。
with pm.Model() as gauss:
μ = pm.Normal("μ", mu=0, sigma=1)
σ = pm.HalfNormal("σ", sigma=1)
s = pm.Simulator("s", normal_simulator, params=[μ, σ],
distance="gaussian", sum_stat="sort",
epsilon=1, observed=data)
trace_g = pm.sample_smc(kernel="ABC")
可以看到代码 gauss_nuts 和代码 gauss_abc 之间有两个重要的区别:
使用了
pm.Simulator分布使用
pm.sample_smc(kernel="ABC")代替了pm.sample()。
通过使用 pm.Simulator ,我们告诉 PyMC3,不会对似然使用封闭形式表达式,而是定义一个伪似然。此时需要传递一个生成合成数据的 Python 函数,本例中该函数为 normal_simulator 以及其参数 params=[μ, σ] 。代码 normal_simulator 给出了此函数的定义,样本大小为 \(1000\) ,未知参数为 \(\mu\) 和 \(\sigma\) 。
def normal_simulator(μ, σ):
return np.random.normal(μ, σ, 1000)
我们还需要向 pm.Simulator 传递其他可选参数,包括距离函数 distance、统计量信息 sum_stat 和阈值 epsilon 的值。此外,还要将观测数据以常规似然形式传递给 pm.Simulator 。
通过使用 pm.sample_smc(kernel="ABC")3 , 我们告诉 PYMC3 在模型中寻找 pm.Simulator 并使用它来定义伪似然,其余的采样过程与序贯蒙特卡洛算法中描述的相同。当 pm.Simulator 存在时,其他采样器将无法运行。
本例中的 normal_simulator 函数原则上可以是任何我们想要的 Python 函数,实际上甚至可以是经过封装的非 Python 代码,例如 Fortran 或 C 代码。这就是近似贝叶斯计算方法的灵活性所在。在本例中,模拟器只是一个 NumPy 随机生成器函数的包装器。
与其他采样器一样,建议运行多个链,以便诊断采样器是否无法正常工作,PyMC3 将尝试自动执行此操作。 Fig. 134 显示了使用两条链运行代码 gauss_abc 的结果。
可以看到,我们能够恢复真实参数,并且采样器没有出现任何明显的采样问题。
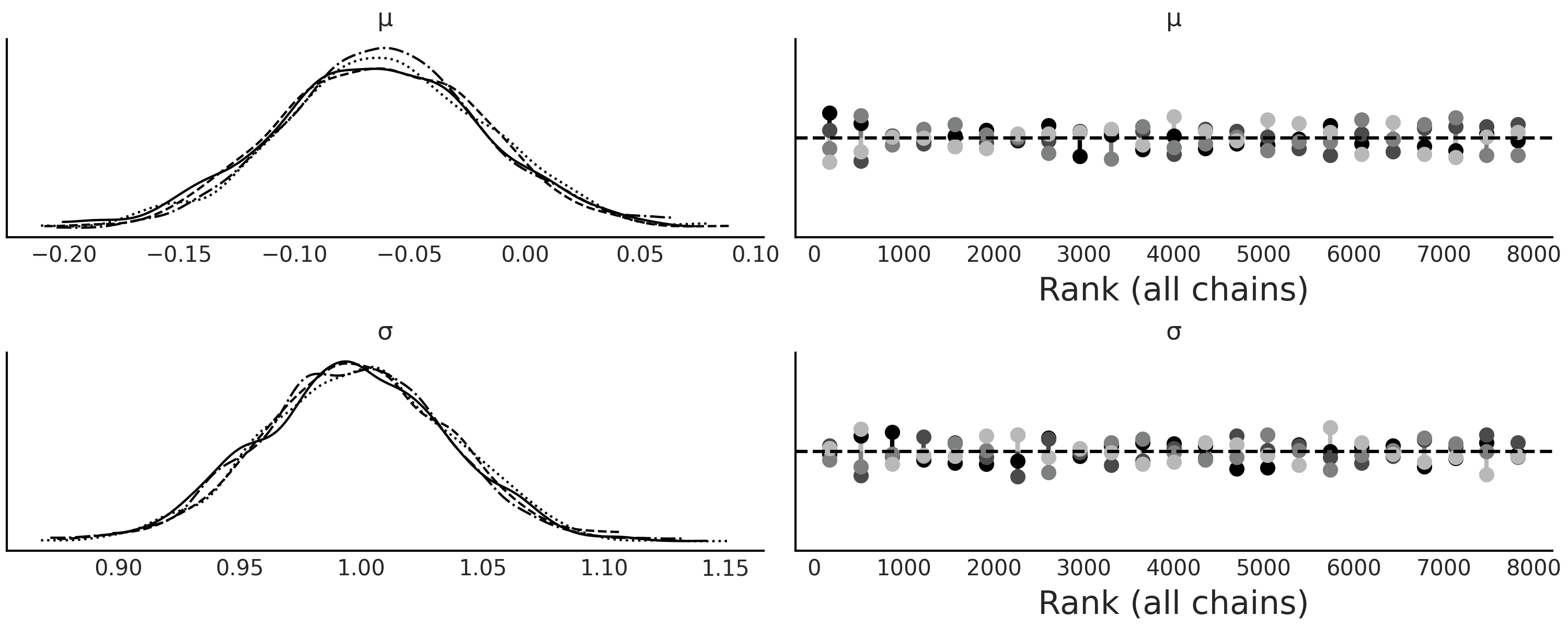
Fig. 134 正如预期的 \(\mu \approx 0\) 和 \(\sigma \approx 1\) 一样,两条链都支持核密度估计和秩图反映的后验。请注意,这两条链中都是通过运行 \(2000\) 个并行 SMC 链获得的,如 SMC 算法中所述。¶
8.4 选择距离函数、 阈值 \(\epsilon\) 和统计量¶
如何定义有效的距离度量、统计量和阈值 \(\epsilon\) 取决于待解决的问题。这意味着我们应该在获得结果之前进行一些试验和尝试,尤其是在遇到新问题时。像往常一样,事先对方案做充分思考有助于减少备选的数量;不过我们也应该习惯于运行实验,因为它总是有助于更好地理解问题,并对超参数做出更明智的抉择。
在接下来的部分中,我们将讨论一些比较通用的指南。
8.4.1 距离函数的选择¶
上例中,我们使用了默认距离函数 distance="gaussian" 来运行代码 gauss_abc,其定义为:
其中 \(X_{o}\) 是观测数据,\(X_{s}\) 是模拟数据,\(\epsilon\) 是其缩放参数。我们称 (74) 为高斯的,因为它在对数尺度上是高斯核 4。我们使用对数尺度来计算伪似然,就和在实际似然(和先验)中一样 5。 \(||X_{oi} - X_{si}||^2\) 是欧几里得距离(也称为 \(L2\) 范数),因此也可以将公式 (74) 描述为加权欧几里得距离。这是目前比较流行的选择,其他选项还有:在 PYMC3 中被称为拉普拉斯距离的 \(L1\) 范数(绝对差的和); \(L-\infty\) 范数(差的最大绝对值);马氏距离:\(\sqrt{(xo - xs )^{T}\Sigma(xo - xs)}\), \(\Sigma\) 为协方差矩阵。
高斯距离、拉普拉斯等可以应用于整个数据,或者应用于统计量。此外,还专门引入了一些能够避免统计量计算、但效果也很好的距离函数 [92, 93, 94]。我们将介绍其中的 Wasserstein 距离 和 KL 散度。
在代码 gauss_abc 中,我们使用了 sum_stat="sort" 6,这告诉 PYMC3 在计算公式 (74) 之前对数据进行排序。这相当于计算 一维 2-Wasserstein 距离,如果使用 \(L1\) 范数,则将得到 一维 1-Wasserstein 距离。当然,也可以为大于 \(1\) 的维度定义 Wasserstein 距离( [94] )。
在计算距离之前对数据排序,会使分布之间的比较更加公平。想象一下,如果有两个完全相等的样本,但是一个从低到高排序,另一个是高到低排序。此时应用公式 (74) 这样的度量,会得出“两个样本不同”的结论。但如果先排序而后计算距离,会得出“两个样本相同”结论。这是一个非常极端的场景,但有助于阐明数据排序背后的直觉。此外,对数据进行排序的前提,是假设我们只关心数据分布,不关心数据顺序;否则的话,做排序处理会破坏数据中本来存在的结构。最典型的例子 第 6 章 中的时间序列。
为了避免定义和计算统计量而引入的另一个距离是使用 KL 散度( 参见第 11.3 KL 散度 部分 )。通常使用以下表达式来近似计算 KL 散度 ( [92, 93] ):
其中 \(d\) 是数据集的维度(变量或特征的数量),\(n\) 是观测数据点的数量。 \(\nu_d\) 包含观测数据到模拟数据的 1-最近邻距离,\(\rho_d\) 包含观测数据到自身的 2-最近邻距离( 注意,如果你将数据集与其自身进行比较,则 1-最近邻距离 永远为零 )。由于该方法涉及最近邻搜索的 \(2n\) 次操作,因此通常使用 k-d 树 来实现 [95] 。
8.4.2 阈值 \(\epsilon\) 的选择¶
在许多近似贝叶斯计算方法中,\(\epsilon\) 参数用作硬阈值,生成距离大于 \(\epsilon\) 的样本的参数 \(\theta\) 值将被拒绝。此外,\(\epsilon\) 可以是用户必须设置的递减值列表,或者算法自适应找到的结果 7。
在 PYMC3 中,\(\epsilon\) 采用的是距离函数的尺度,就像在公式 (74) 中一样,所以不能用作硬阈值。我们可以根据需要设置 \(\epsilon\) 。我们可以选择一个标量值( 相当于将所有 \(i\) 的 \(\epsilon_i\) 设置为相等 )。这在评估数据上的距离而不是统计量上的距离时非常有用。在此情况下,合理猜测可能是数据的经验标准差。
如果我们改为使用统计量,那么可以将 \(\epsilon\) 设置为值列表。这通常是必要的,因为每个统计量可能具有不同的尺度。如果尺度差异太大,那么每个统计量的贡献将是不均衡的,甚至可能出现单个统计量主导距离计算的情况。在此情况下,\(\epsilon\) 的一个常用选择是在先验预测分布下的 \(i^{\text{th}}\) 个统计量的经验标准差,或中值绝对差,因为这样选择相对于异常值来说更为稳健。使用先验预测分布的问题之一是其可能比后验预测分布更宽,因此,为了找到一个合适的 \(\epsilon\) 值,我们可能希望将上述有依据的猜测作为上限,然后从这些值中尝试一些较低的值。然后我们可以根据计算成本、所需的精度/误差水平和采样器的效率等几个因素来选择 \(\epsilon\) 的最终值。一般来说,\(\epsilon\) 的值越低,近似值就越好。
Fig. 135 显示了 \(\mu\) 和 \(\sigma\) 的几个 \(\epsilon\) 阈值设置以及 NUTS 采样的森林图( 使用正常似然而不是模拟器 )。
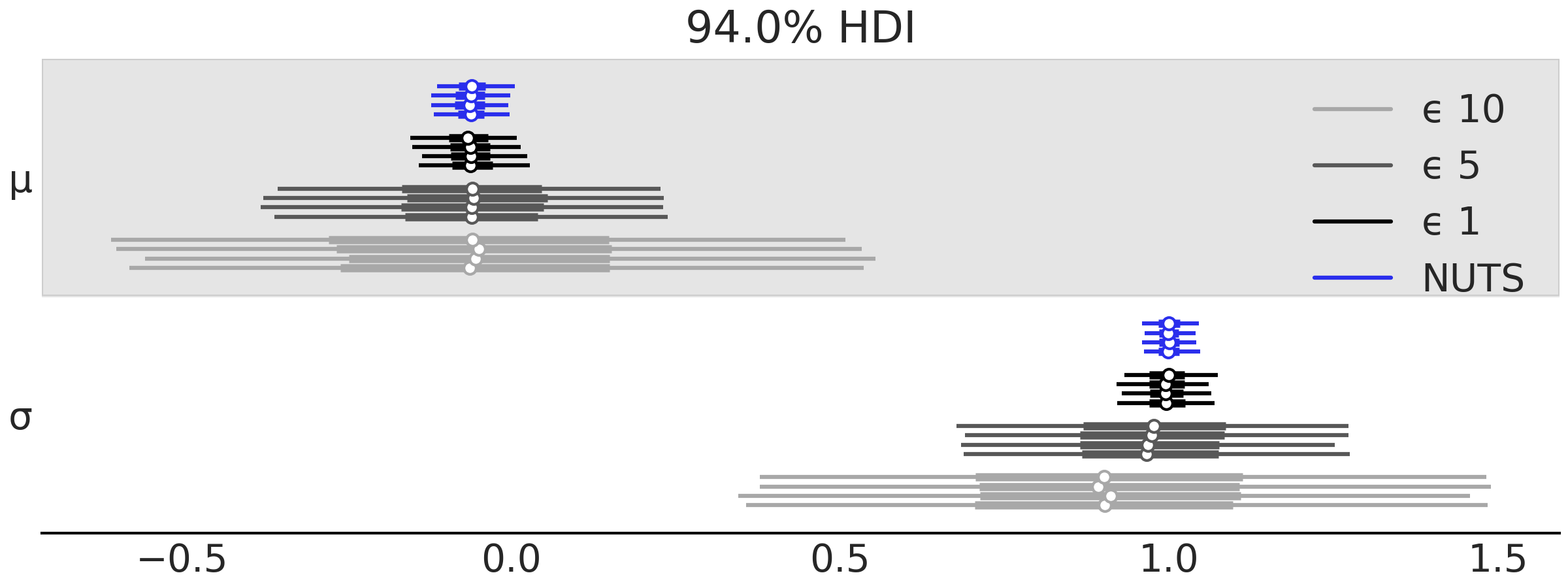
Fig. 135 \(\mu\) 和 \(\sigma\) 的森林图,使用 NUTS 或近似贝叶斯计算获得,\(\epsilon\) 为 \(1\) 、\(5\) 和 \(10\) 的递增值。¶
减小 \(\epsilon\) 的值并非毫无限制的,因为过低的值有时会使采样器非常低效,表明目标是一个没有太大意义的准确度水平。 Fig. 136 显示了当来自代码 gauss_abc 的模型以 epsilon=0.1 的值进行采样时,序贯蒙特卡洛采样器难以收敛,采样器非常失败。
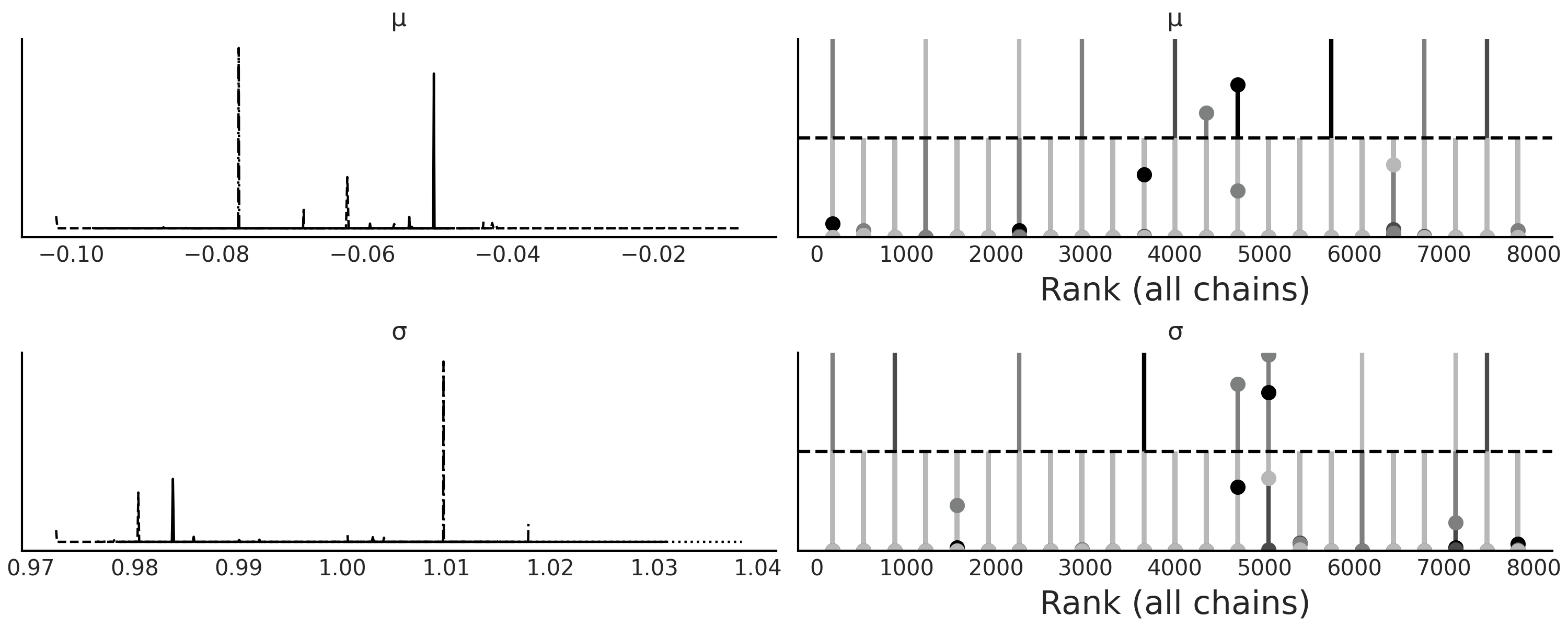
Fig. 136 模型trace_g_001的核密度估计和秩图,收敛失败表明 \(\epsilon=0.1\) 的取值对于该问题来说太苛刻了。¶
为了能够为 \(\epsilon\) 确定一个好的值,可以使用一些非近似贝叶斯计算方法中的模型评价工具,例如贝叶斯 \(p\) 值和后验预测检查,如图 Fig. 137、Fig. 138 和 Fig. 139。 Fig. 137 包含值 \(\epsilon=0.1\) ,主要是为了展示校准不佳的模型。但在实践中,如果获得像 Fig. 136 中的秩图,我们应该停止分析计算得到的后验,并重新检查模型定义。此外,对于近似贝叶斯计算方法,还应检查超参数 \(\epsilon\) 的值、统计量或距离函数。
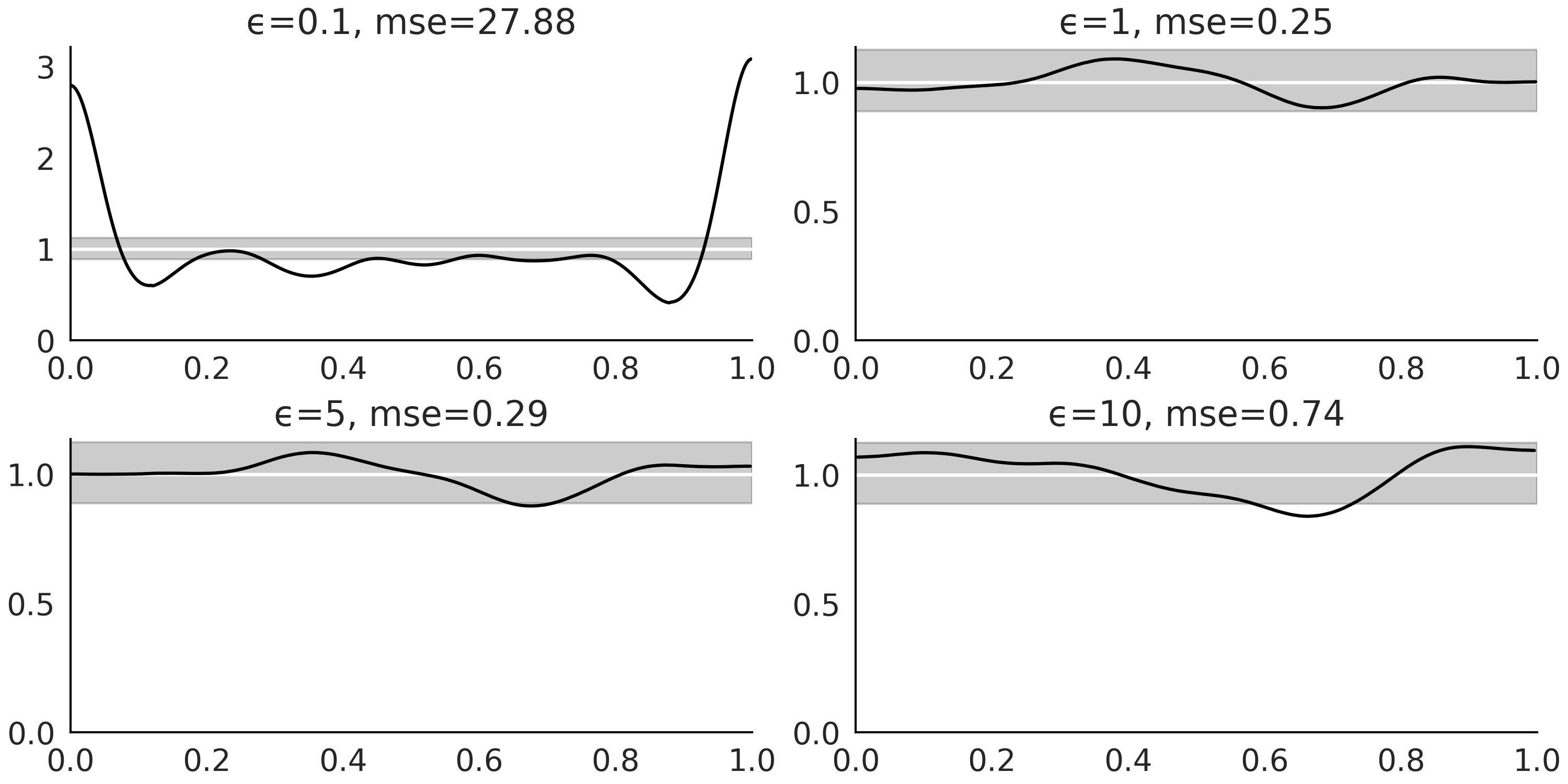
Fig. 137 \(\epsilon\) 值递增的边缘贝叶斯 \(p\) 值分布。对于一个校准良好的模型,我们应该预期一个均匀分布。可以看到 \(\epsilon=0.1\) 的校准很糟糕,因为 \(\epsilon\) 的值也是如此。对于 \(\epsilon\) 的所有其他值,分布看起来更加均匀,并且均匀性水平随着 \(\epsilon\) 的增加而降低。se 值是预期均匀分布和核密度估计之间的(缩放的)平方差。¶
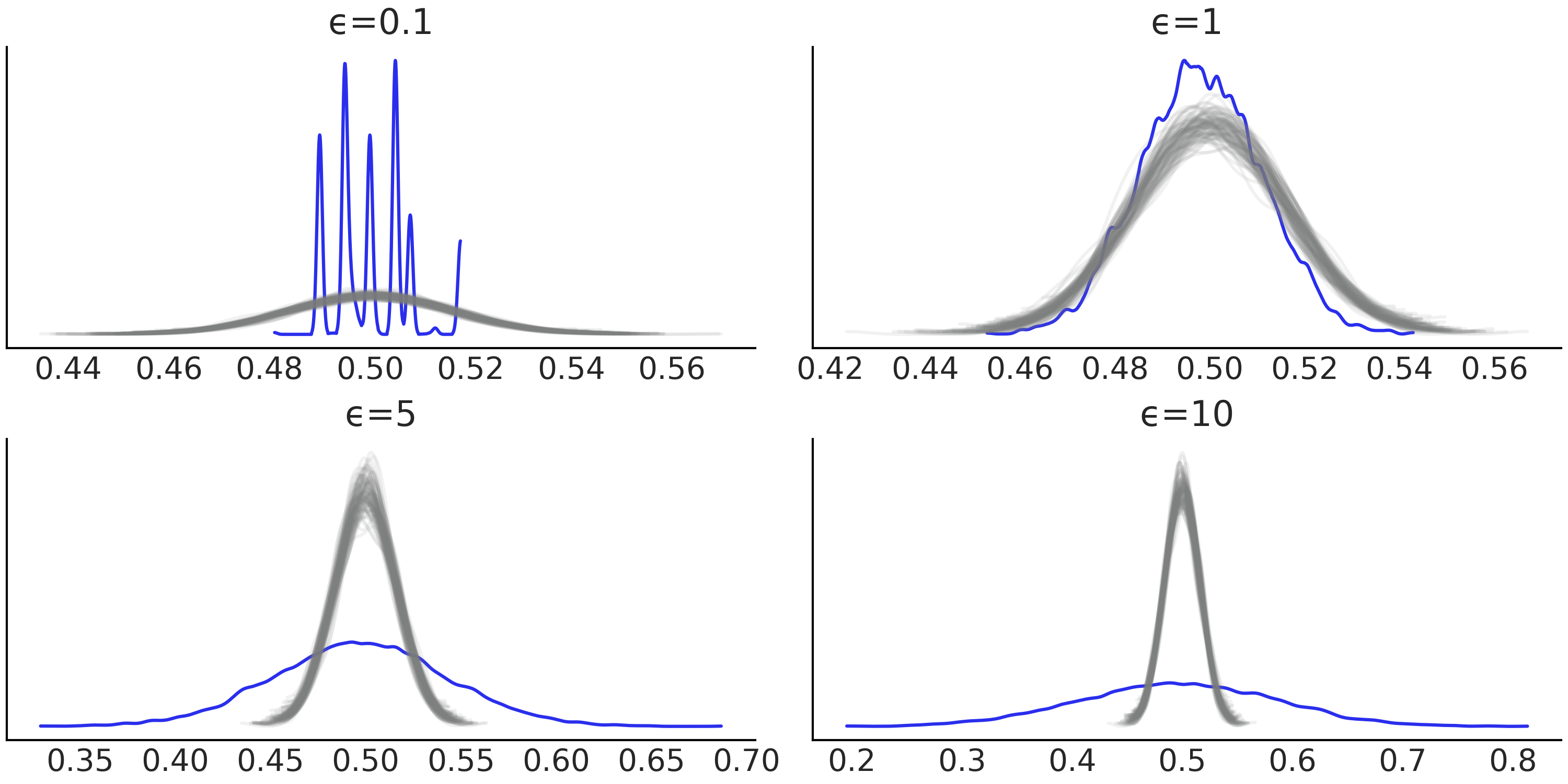
Fig. 138 增加 \(\epsilon\) 值的贝叶斯 \(p\) 值。蓝色曲线是观测分布,灰色曲线是预期分布。对于一个校准良好的模型,我们期望分布集中在 \(0.5\) 左右。可以看到 \(\epsilon=0.1\) 的校准很糟糕,因为 \(\epsilon\) 的值太低了。可以看到 \(\epsilon=1\) 提供了最好的结果。¶
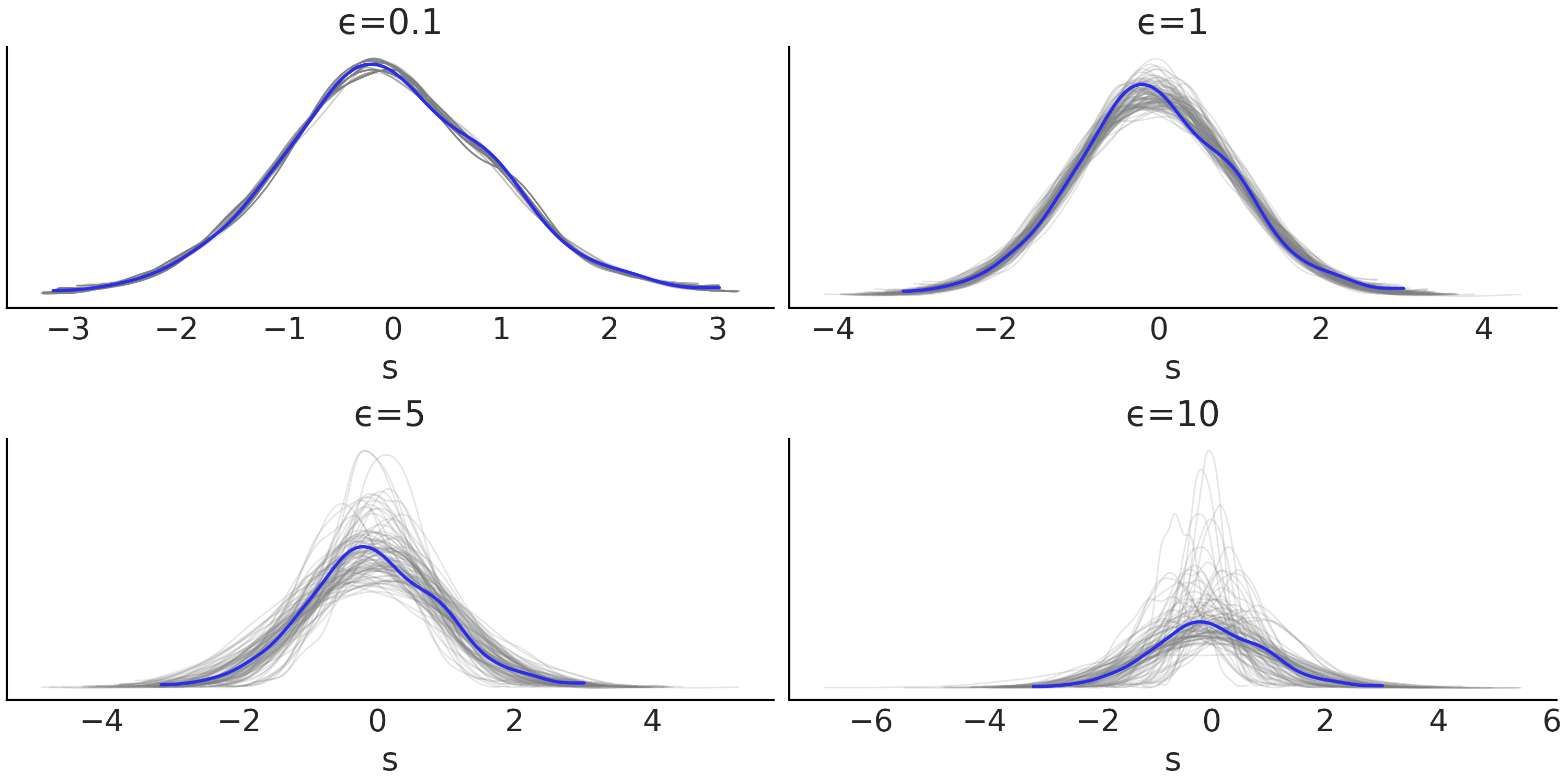
Fig. 139 \(\epsilon\) 递增时的后验预测检查。蓝色曲线是观测分布,灰色曲线是预期分布。令人惊讶的是,从 \(\epsilon=0.1\) 中似乎得到了一个很好的调整,即便我们知道来自该后验的样本不可信。这是一个非常简单的例子,我们完全靠运气得到了正确答案。这是一个 a too good to be true fit 的例子。实际上这是最糟糕的!如果我们只考虑具有看起来合理的后验样本的模型( 即不是 \(\epsilon=0.1\) ),则可以看到 \(\epsilon=1\) 提供了最好的结果。¶
8.4.3 统计量的选择¶
统计量的选择可能比距离函数的选择更难,并且会产生更大的影响。
出于此原因,许多研究都集中在这个主题上,从使用不需要统计量的距离 [93, 94] 到选择统计量的策略 [96]。
一个好的统计量提供了低维度和信息量之间的平衡。当我们没有足够统计量数据时,很容易通过添加大量统计量数据来进行过度补偿。直觉是信息越多越好。然而,增加统计量的数量实际上会降低近似后验 [96] 的质量。对此的一种解释是,我们从计算数据上的距离转移到计算摘要上的距离以减少维度,通过增加我们正在违背该目的的摘要统计数据的数量。
在一些领域,如群体遗传学,近似贝叶斯计算方法非常普遍,人们开发了大量有用的统计量数据 [97, 98, 99]。一般来说,查看你正在研究的应用领域的文献以了解其他人在做什么是一个好主意,因为他们已经尝试并测试了许多替代方案的机会很高。
如有疑问,我们可以遵循上一节中的相同建议来评估模型拟合,即秩图、贝叶斯 \(p\) 值、后验预测检查等,并在必要时尝试替代方案(参见图 Fig. 136, Fig. 137、Fig. 138 和 Fig. 139)。
8.5 g-and-k 分布¶
一氧化碳 ( \(CO\) ) 是一种无色、无味的气体,大量吸入有害甚至致命。当某物燃烧时会产生这种气体,尤其是在氧气含量低的情况下。世界上许多城市通常会监测一氧化碳和其他气体,如二氧化氮 ( \(NO_2\) ),以评估空气污染程度和空气质量。在城市中,一氧化碳的主要来源是汽车以及其他燃料化石车辆或机械。 Fig. 140 显示了 \(2010\) 年至 \(2018\) 年布宜诺斯艾利斯市一个站点测量的每日 \(CO\) 水平的直方图。
正如我们所见,数据似乎略微向右偏。此外,数据显示了一些具有非常高的观测值。
底部子图省略了 \(3\) 到 \(30\) 之间的 \(8\) 个观测值。
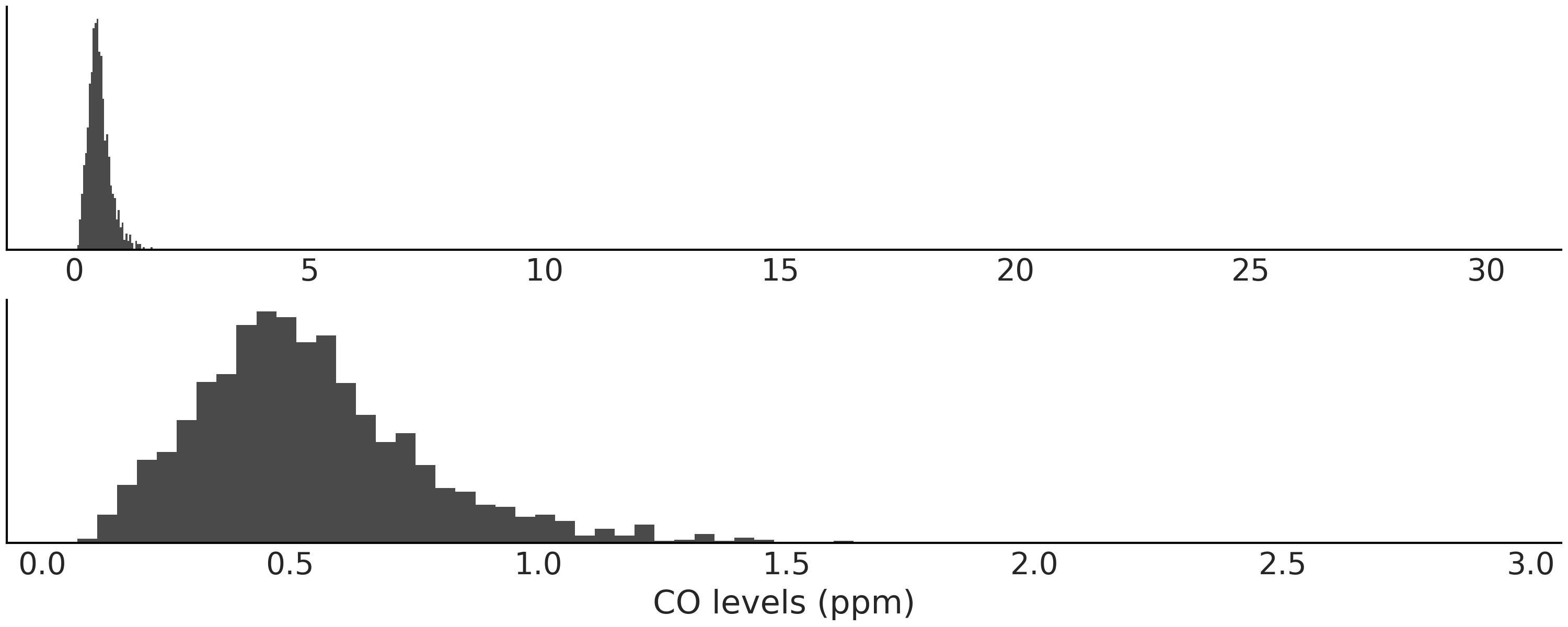
Fig. 140 \(CO\) 水平的直方图。顶部子图显示整个数据,底部子图忽略了大于 \(3\) 的值。¶
为了拟合这些数据,我们将引入单变量 g-and-k 分布。这是一个 \(4\) 参数的分布,能够描述具有高偏度和/或高峰度的数据 [100, 101]。g-and-k 分布的密度函数没有封闭形式的表达式,并且通过其分位数函数(即累积分布函数的逆函数)来进行定义:
其中 \(z\) 是标准高斯累积分布函数的逆函数,\(x \in (0,1)\)。
(1)参数 \(a\) 、 \(b\) 、 \(g\) 和 \(k\) 分别为位置、尺度、偏度和峰度参数。如果 \(g\) 和 \(k\) 均为 \(0\),则恢复了具有均值 \(a\) 和标准差 \(b\) 的高斯分布。
(2)\(g > 0\) 给出正(右)偏度,\(g < 0\) 给出负(左)偏度。参数 \(k \geqslant 0\) 给出的尾部比高斯分布长,而 \(k < 0\) 的尾部比高斯分布短。
(3)\(a\) 和 \(g\) 可以取任何实数值。通常将 \(b\) 限制为正数并且 \(k \geqslant -0.5\) 或有时 \(k \geqslant 0\) (即尾部与高斯分布中的尾部一样重或更重)。
(4)此外,通常固定 \(c=0.8\)。
有了所有这些限制,我们可以保证得到一个严格递增的分位数函数 [101],而这正是连续分布函数的标志。
代码 gk_quantile 定义了 g-and-k 分位数分布。我们省略了 cdf 和 pdf 的计算,因为涉及太多额外内容,而且在我们的例子中暂时用不到 8。
虽然 g-and-k 分布 的概率密度函数可以用数值方法推算 [101, 102],但使用反演方法从 g-and-k 模型 中进行模拟更直接和快捷 [102, 103]。
为了实现反演方法,我们对 \(x \sim \mathcal{U}(0, 1)\) 进行采样并替换公式 (76)。代码 gk_quantile 展示了如何在 Python 中执行此操作,Fig. 141 展示了 g-and-k 分布 的示例。
class g_and_k_quantile:
def __init__(self):
self.quantile_normal = stats.norm(0, 1).ppf
def ppf(self, x, a, b, g, k):
z = self.quantile_normal(x)
return a + b * (1 + 0.8 * np.tanh(g*z/2)) * ((1 + z**2)**k) * z
def rvs(self, samples, a, b, g, k):
x = np.random.normal(0, 1, samples)
return ppf(self, x, a, b, g, k)
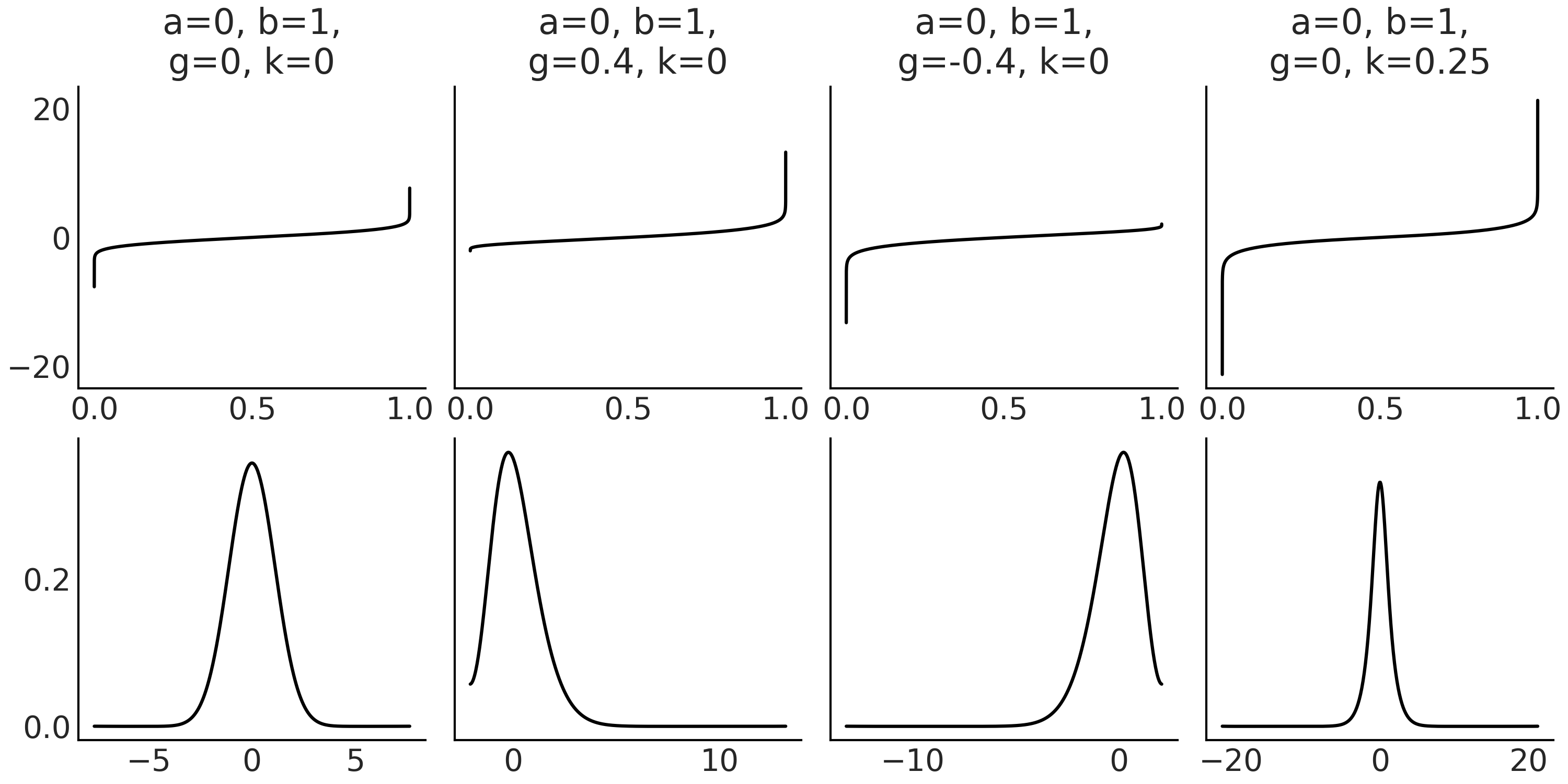
Fig. 141 第一行显示了分位数函数,也称为累积分布函数( CDF )的逆函数。给定一个分位数值,它会返回代表该分位数的变量值。例如,如果你有 \(P(X <= x_q) = q\),则将 \(q\) 传递给分位数函数可以得到 \(x_q\)。图中第二行显示了(近似的)概率密度函数。对于此示例,使用核密度估计可以直接从代码 gk_quantile 生成的随机样本中计算得到概率密度函数。¶
要使用 SMC-ABC 拟合 g-k 分布,可以使用高斯距离和 sum_stat="sort"。或者,也可以考虑为这个问题量身定制的统计量。参数 \(a\) 、\(b\) 、 \(g\) 和 \(k\) 分别与位置、尺度、偏度和峰度相关联。因此,可以用这些量的稳健估计来作为新的专用统计量 [103] :
其中 \(e1\) 到 \(e7\) 是八分位数,即将样本分成八个子集的分位数。
如果注意,可以看到 \(sa\) 是中位数,\(sb\) 是四分位数范围,它们分别作为位置和离散度的稳健估计量。 \(sg\) 和 \(sk\) 看起来有点模糊,但它们分别是偏度 [104] 和峰度 [105] 的稳健估计量。
对于对称分布,\(e6-e4\) 和 \(e2-e4\) 将具有相同的幅度但符号相反,此时 \(sg\) 将为零,而对于偏斜分布,\(e6-e4\) 将大于 \( e2-e4\) 或相反。
当 \(e6\) 和 \(e2\) 附近的概率质量减少时( 即当质量从分布的中心部分移动到尾部时 ),\(sk\) 的分子项在增加。而 \(sg\) 和 \(sk\) 中的分母都充当了归一化因子。
综合分析后,可以使用 Python 为问题创建新的统计量,如以下代码所示。
def octo_summary(x):
e1, e2, e3, e4, e5, e6, e7 = np.quantile(
x, [.125, .25, .375, .5, .625, .75, .875])
sa = e4
sb = e6 - e2
sg = (e6 + e2 - 2*e4)/sb
sk = (e7 - e5 + e3 - e1)/sb
return np.array([sa, sb, sg, sk])
现在我们需要定义一个模拟器,只需将之前在代码 gk_quantile 中定义的 g_and_k_quantile() 函数的 rvs 方法封装起来即可。
gk = g_and_k_quantile()
def gk_simulator(a, b, g, k):
return gk.rvs(len(bsas_co), a, b, g, k)
在定义了统计量和模拟器并导入数据之后,就可以定义模型了。
对于这个例子,基于所有参数都限制为正的事实,可以使用弱信息先验。 \(CO\) 水平不能取负值,因此 \(a\) 为正值; \(g\) 也预计为 \(0\) 或正值,因为大部分测量值预计为“low”,只有某些测量值值较大。我们也有理由假设参数很有可能低于 \(1\)。
with pm.Model() as gkm:
a = pm.HalfNormal("a", sigma=1)
b = pm.HalfNormal("b", sigma=1)
g = pm.HalfNormal("g", sigma=1)
k = pm.HalfNormal("k", sigma=1)
s = pm.Simulator("s", gk_simulator,
params=[a, b, g, k],
sum_stat=octo_summary,
epsilon=0.1,
observed=bsas_co)
trace_gk = pm.sample_smc(kernel="ABC", parallel=True)
Fig. 142 显示了拟合后 gkm 模型 的配对图。
Fig. 142 分布略微偏斜,并且具有一定程度的峰度,正如所预计的那样,少量的 \(CO\) 水平比其他大部分情况要高出一到两个数量级。可以看到 \(b\) 和 \(k\) (略微)相关。这也是可预期的,因为随着尾部密度(峰度)的增加,离散度会同时增加,但如果 \(k\) 增加,g-and-k 分布可以保持 \(b\) 较小。这就像 \(k\) 在吸收离散度一样,有点类似于在学生 \(t\) 分布中使用的尺度和 \(\nu\) 参数的情况。¶
8.6 移动平均模型的近似¶
移动平均 (MA) 模型是建模单变量时间序列的常用方法(参见 第 6 章 )。 \(MA(q)\) 模型指定输出变量线性依赖于随机项 \(\lambda\) 的当前值和 \(q\) 个历史值, \(q\) 被称为 MA 模型 的阶数。
其中 \(\lambda\) 是高斯白噪声误差项 9。
这里将使用 Marin et al. [106] 中的玩具模型。在该例中,使用均值为 \(0\) 的 \(MA(2)\) 模型( 即 \(\mu =0\) ),模型如下所示:
代码 ma2_simulator_abc 显示了此模型的 Python 模拟器,在 Fig. 143 中,可以看到 \(\theta1 = 0.6\) 、 \(\theta2=0.2\) 时该模拟器的两个实现。
def moving_average_2(θ1, θ2, n_obs=200):
λ = np.random.normal(0, 1, n_obs+2)
y = λ[2:] + θ1*λ[1:-1] + θ2*λ[:-2]
return y
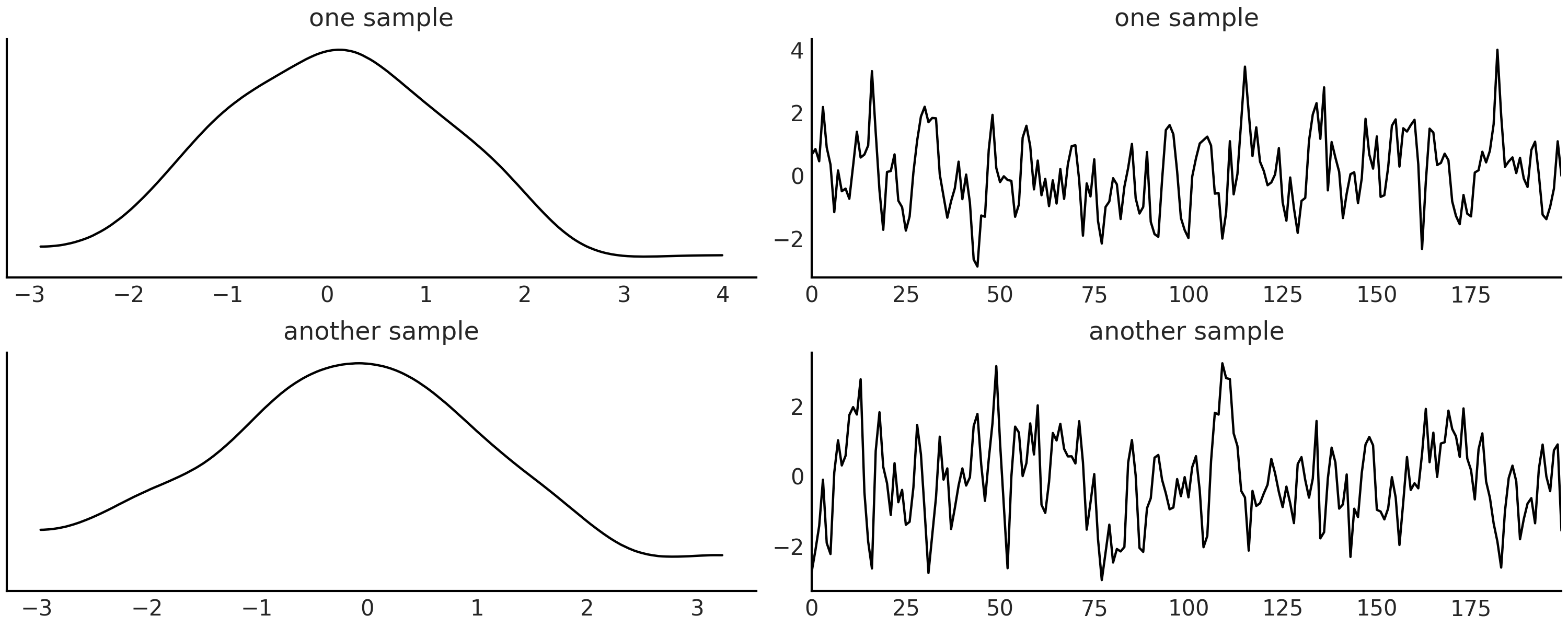
Fig. 143 \(MA(2)\) 模型的两种实现, \(\theta1=0.6\) , \(\theta2 =0.2\)。左列为核密度估计,右列为时间序列。¶
理论上,我们可以尝试想要的任何距离函数和/或统计量来拟合 \(MA(q)\) 模型,但此处我们不会这样做,而是使用 \(MA(q)\) 模型的一些属性作为牵引。时间序列的自相关性是 \(MA(q)\) 模型的一个重要属性。理论表明,对于 \(MA(q)\) 模型,大于 \(q\) 的滞后效应为零,因此对于 \(MA(2)\) ,使用滞后 \(1\) 和滞后 \(2\) 的自相关函数作为统计量似乎也是合理的。此外,为了避免计算数据的方差,我们将使用自协方差函数而不是自相关函数。
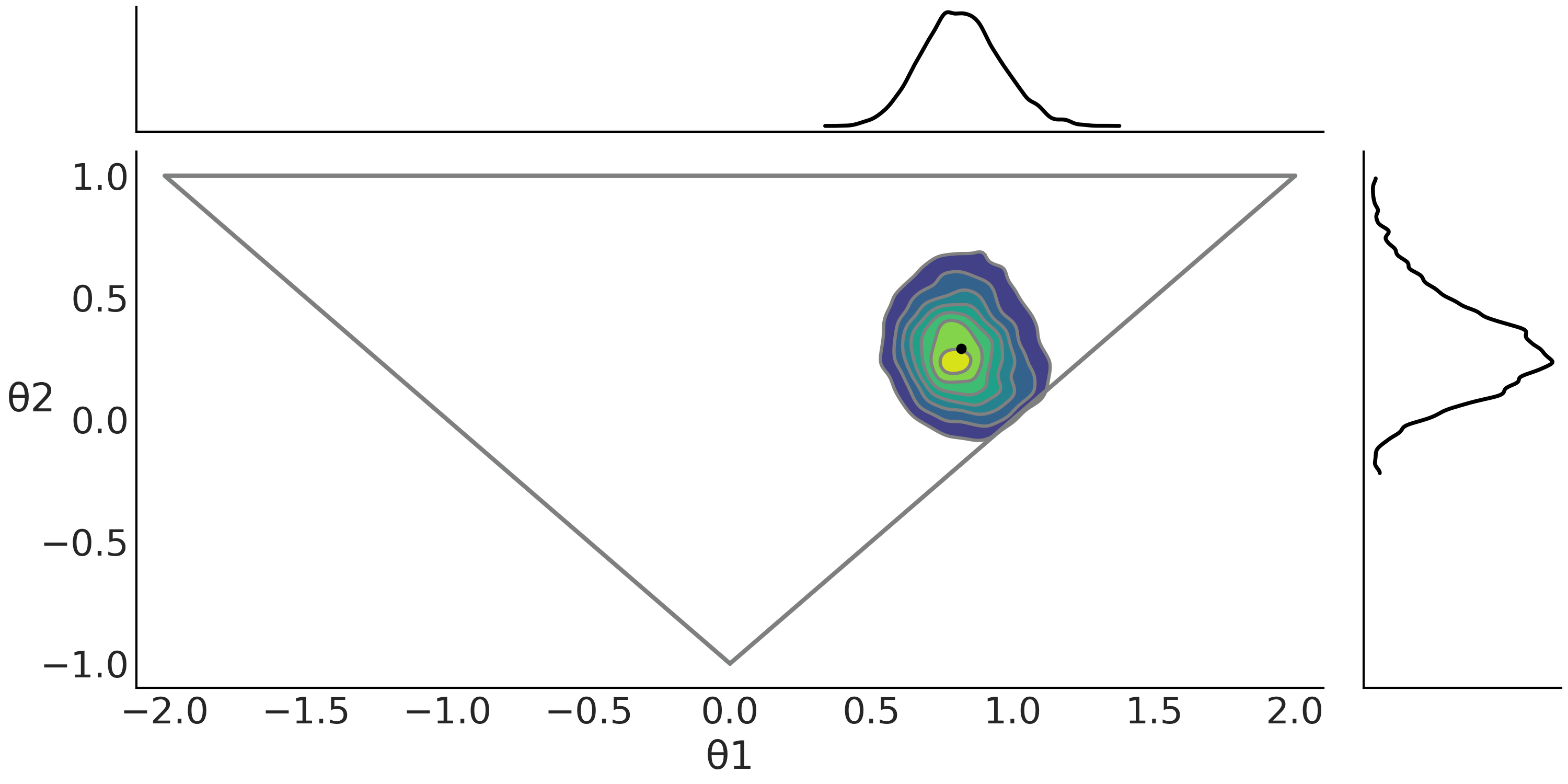
此外,除非引入一些约束,否则 \(MA(q)\) 模型是不可识别的。对于 $\(MA(1)\)\( 模型,约束为 \)-1<\theta_1<1\(。 对于 \)MA(2)\(, 约束为 \)-2<\theta_1<2\( 、 \)\theta_1 + \theta_2 > -1\( 和 \)\theta_1 - \theta_2 < 1$,这意味着需要从一个三角形中采样,如Fig. 145。
结合自定义的统计量和可识别约束的近似贝叶斯计算模型见代码 MA2_abc 。
with pm.Model() as m_ma2:
θ1 = pm.Uniform("θ1", -2, 2)
θ2 = pm.Uniform("θ2", -1, 1)
p1 = pm.Potential("p1", pm.math.switch(θ1+θ2 > -1, 0, -np.inf))
p2 = pm.Potential("p2", pm.math.switch(θ1-θ2 < 1, 0, -np.inf))
y = pm.Simulator("y", moving_average_2,
params=[θ1, θ2],
sum_stat=autocov,
epsilon=0.1,
observed=y_obs)
trace_ma2 = pm.sample_smc(3000, kernel="ABC")
pm.Potential 是一种无需向模型添加新变量,即可将任意项合并到(伪)似然的方法。引入约束特别有用。在代码 MA2_abc 中,如果 pm.math.switch 中的第一个参数为真,则我们将 \(0\) 与似然相加,否则为 \(-\infty\)。
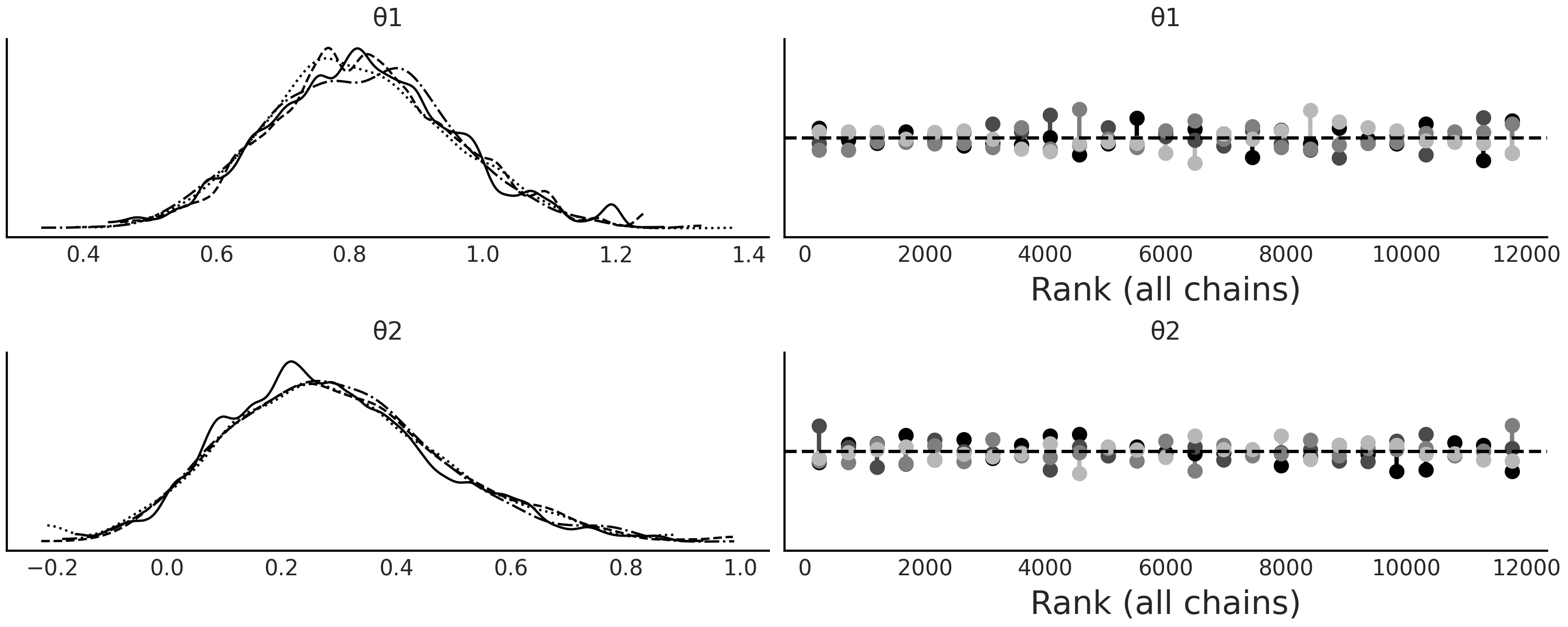
Fig. 144 \(MA(2)\) 模型的近似贝叶斯计算轨迹图。正如预计的那样,真实参数被恢复,秩图看起来非常平坦。¶
8.7 在近似贝叶斯计算的场景中做模型比较¶
近似贝叶斯计算方法经常用于模型选择。虽然已经提出了许多模型比较方法 [96, 107],但此处将重点讨论两种方法:贝叶斯因子法(包括与 LOO 的比较)和 随机森林法 [99]。
与参数推断一样,在模型比较中统计量的选择至关重要。当使用模型的预测结果来评估多个模型时,如果它们都做出了大致相同的预测,则我们无法偏爱其中任何一个模型。相同的思想可以应用于(含统计量的)近似贝叶斯计算场景下的模型比较和选择。如果使用均值作为统计量,而模型预测的均值相同,那么此统计量将不足以区分模型的优劣。
我们应该花更多时间来思考是什么让模型与众不同。
8.7.1 贝叶斯因子法¶
用于做模型比较的一个常见量是边缘似然。通常这种比较采用边缘似然比的形式,即贝叶斯因子。如果贝叶斯因子的值大于 \(1\) ,则分子中的模型优于分母中的模型,反之亦然。在 11.7.2 边缘似然与模型比较 中,我们讨论了有关贝叶斯因子的更多细节,包括其注意事项。其中一个警示是边缘似然通常难以计算。幸运的是,SMC 方法和扩展的 SMC-ABC 方法能够将边缘似然的计算转变成采样的副产品。 PYMC3 中的 SMC 计算并保存轨迹中的对数边缘似然,因此可以通过执行 trace.report.log_marginal_likelihood 来访问对数边缘似然的值。考虑到该值采用对数刻度,因此在计算贝叶斯因子时可以这样做:
ml1 = trace_1.report.log_marginal_likelihood
ml2 = trace_2.report.log_marginal_likelihood
np.exp(ml1 - ml2)
当使用统计量时,通常不能用近似贝叶斯计算方法得出的边缘似然来比较竞争中的模型 [108],除非统计量对于模型比较来说是充分的。这一点非常令人沮丧,因为除了一些形式化示例或特定模型之外,没有通用的指南来确保模型的充分性 [108] 。如果使用所有数据( 即不依赖统计量 )则不存在问题 10。这类似于 11.7.2 边缘似然与模型比较 中的讨论,即计算边缘似然通常是比计算后验困难得多的问题。即便我们设法找到了足以计算后验的统计量,也不能保证它对模型比较也有效。
为了更好地理解边缘似然在近似贝叶斯计算中的表现,现在将分析一个简短的实验。该实验中还包含 LOO,因为我们认为 LOO 是比边缘似然和贝叶斯因子更好的整体指标。
实验的基本方法是将具有显式似然的模型的对数边缘似然值、使用 LOO 计算的值、近似贝叶斯计算模型(采用含统计量和不含统计量的模拟器)的值进行比较。结果显示在图 Fig. 146 中,和代码 gauss_nuts 以及代码 gauss_abc 中的。边缘(伪)似然值由 SMC 和 LOO 值( 调用 az.loo() 函数 )的乘积计算得出。请注意,LOO 是在逐点的对数似然值上定义的,而在近似贝叶斯计算中,我们只能访问逐点的对数伪似然值。
从 Fig. 146 中可以看到,通常 LOO 和对数边缘似然的表现相似。从第一列中可以看到,model_1 始终被选为比 model_0 更好(这里越高越好)。模型之间的对数边缘似然的差(斜率)较 LOO 更大,这可以解释为 “边缘似然的计算明确考虑了先验,而 LOO 仅通过后验间接进行”,参见 11.7.2 边缘似然与模型比较 以了解详情。即使 LOO 值和边缘似然值因样本而异,它们也会存在比较一致的表现。我们可以从 model_0 和 model_1 之间线的斜率看到这一点。虽然线的斜率并不完全相同,但非常相似。这是模型选择方法的理想表现。如果我们比较model_1和model_2,可以得出类似结论。另外,注意两种模型对于 LOO 基本上无法区分,而边缘似然反映了更大的差异。再一次,原因是 LOO 仅从后验计算,而边缘似然直接考虑了先验。
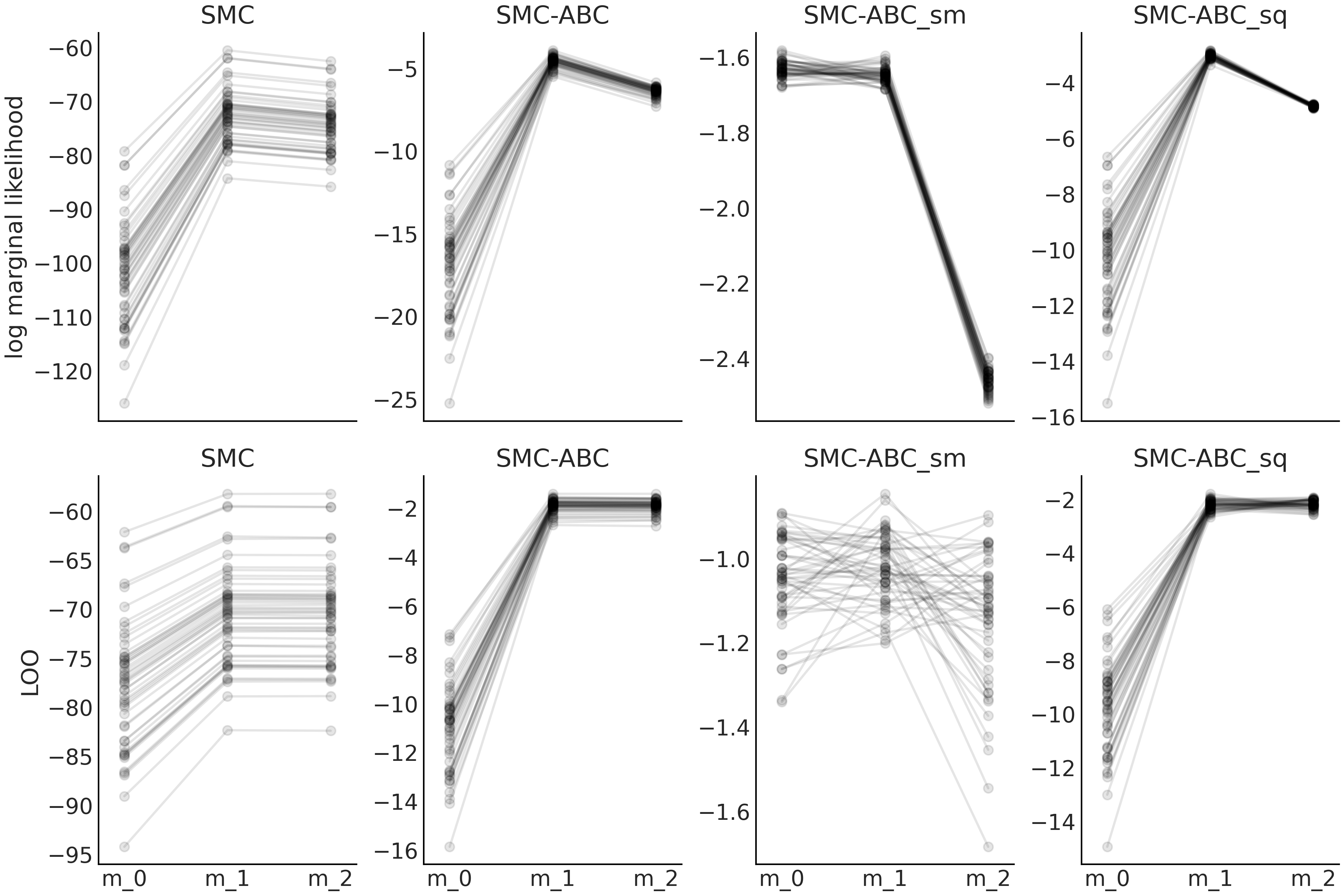
Fig. 146 模型 m_0 与公式 (73) 中描述的模型相似,但具有 \(\sigma \sim \mathcal{HN}(0.1)\)。 model_1 与公式 (73) 相同。 model_2 与公式 (73) 相同,但使用 \(\sigma \sim \mathcal{HN}(10)\)。¶
第一行对应于对数边缘似然值,第二行对应于 LOO 计算的值。
各列分别对应于序贯蒙特卡洛方法(SMC)、完整数据集的近似贝叶斯计算方法( SMC-ABC )、 使用均值统计量的近似贝叶斯计算方法( SMC-ABC_sm )、使用均值和标准差统计量的近似贝叶斯计算方法( SMC-ABC_sq )。我们共进行了 \(50\) 次实验,每次实验的样本量为 \(50\)。
图中第二列显示了近似贝叶斯计算方法的效果。我们仍然选择了 model_1 作为更好的模型,但现在 model_0 的离散度比 model_1 或 model_2 的离散度要大得多。此外,现在得到了相互交叉的线。综合起来,这两个观测似乎表明我们仍然可以使用 LOO 或对数边缘似然来选择最佳模型,但是相对值( 例如由 az.compare() 计算的值或贝叶斯因子),则具有较大的变化性。
第三列显示了使用均值作为统计量时的情况。现在模型 model_0 和 model_1 看起来差不多,但 model_2 看起来比较糟糕。它几乎就像前一列的镜面图。这表明当使用含统计量的近似贝叶斯计算方法时,对数边缘似然和 LOO 可能无法提供合理答案。
第四列显示了使均值和标准差作为统计量时的情况。我们看到,可以定性地恢复第二列时观测到的表现。
关于伪似然的尺度
请注意 \(y\) 轴上的比例是不同的,尤其是跨列时。原因有两个:
(1)当使用近似贝叶斯计算时,我们使用按 \(\epsilon\) 缩放的核函数来逼近似然;
(2)当使用统计量时,我们正在减小数据的大小。另请注意,如果增加均值或分位数等统计量的样本量,则该大小将保持不变,即无论从 \(10\) 次还是 \(1000\) 次观测中计算均值,结果都是相同的数字。
Fig. 147 可以帮助我们理解 Fig. 146 中讨论的内容,建议你自己分析这两个图。
当前我们将重点关注两个结果:
首先,在执行 SMC-ABC_sm 时,我们有充分的均值统计量,但没有数据离散度的信息,因此参数 a 和 σ 的后验不确定性基本上由先验控制。注意 model_0 和 model_1 对于 μ 的估计值非常相似,而 model_2 的不确定性非常大。
其次,关于参数 σ ,model_0 的不确定性非常小,model_1 的不确定性应该更大,model_2 的不确定性大得离谱。
综上所述,我们可以看到为什么对数边缘似然和 LOO 表明 model_0 和 model_1 差不多,但 model_2 却非常不同。而基本上,SMC-ABC_sm 无法很好地拟合!因此使用 SMC-ABC_sm 计算的对数边缘似然和 LOO 与使用 SMC 或 SMC-ABC 计算的结果相矛盾。如果使用均值和标准差作为统计量( SMC-ABC_sq ),我们可以部分恢复使用完整数据集的 SMC-ABC 时的表现。
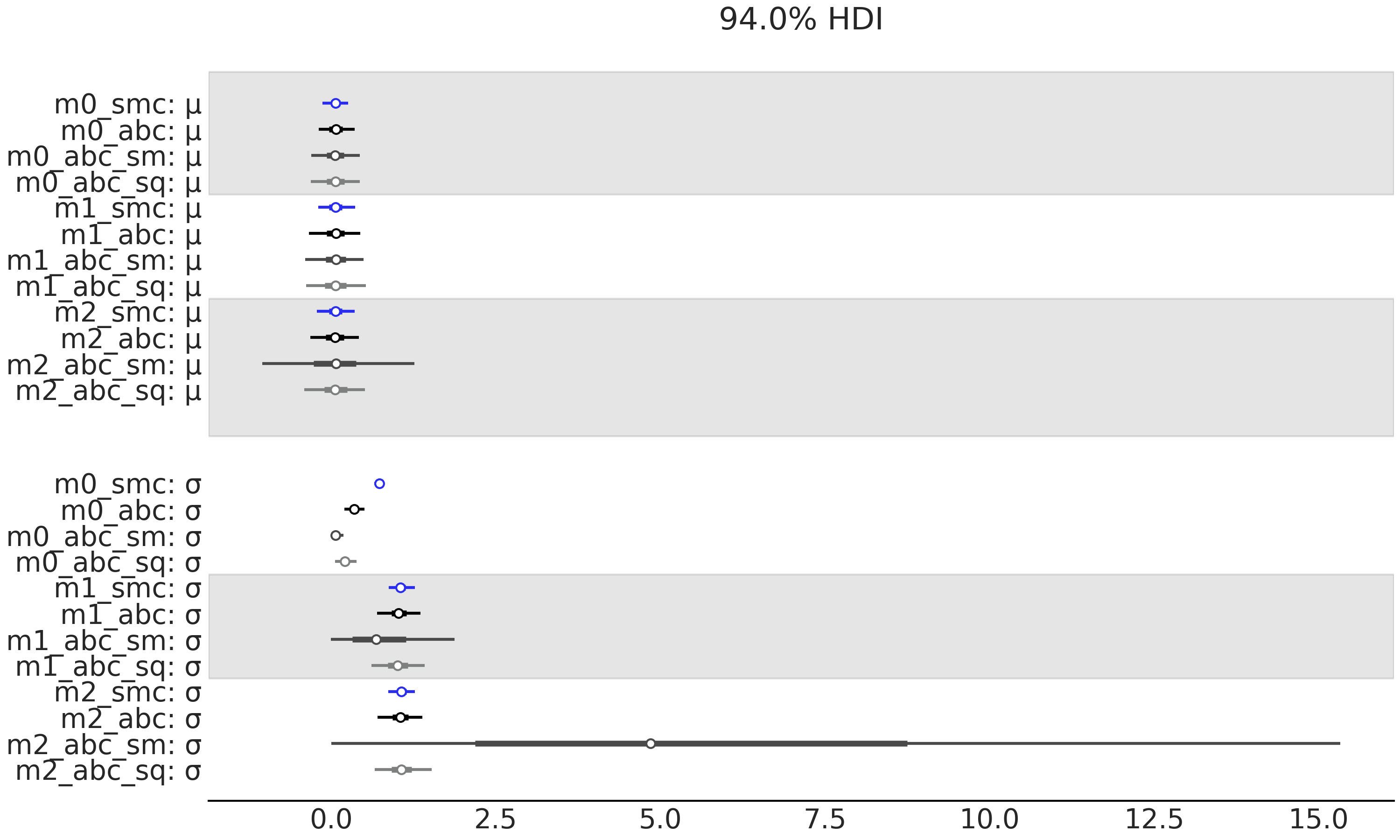
Fig. 147 模型 m_0 与公式 (73) 中描述的模型相似,但具有 \(\sigma \sim \mathcal{HN}(0.1)\)。 model_1 与公式 (73) 相同。 model_2 与公式 (73) 相同,但使用 \(\sigma \sim \mathcal{HN}(10)\)。¶
第一行包含边缘似然值,第二行包含 LOO 值。图中的列表示计算这些值的不同方法,分别是:序贯蒙特卡洛(SMC)、使用整个数据集的近似贝叶斯计算(SMC-ABC)、 使用均值作为统计量的近似贝叶斯计算(SMC-ABC_sm)、使用均值和标准差统计量的近似贝叶斯计算(SMC-ABC_sq )。我们进行了 \(50\) 次实验,每次实验的样本量为 \(50\)。
图 Fig. 148 和 Fig. 149 显示了类似的分析,但 model_0 是几何模型,而 model_1 是泊松模型。数据服从移位的泊松分布 \(\mu \sim 1 + \text{Pois}(2.5)\) 。我们将这些图的分析留给读者作为练习。
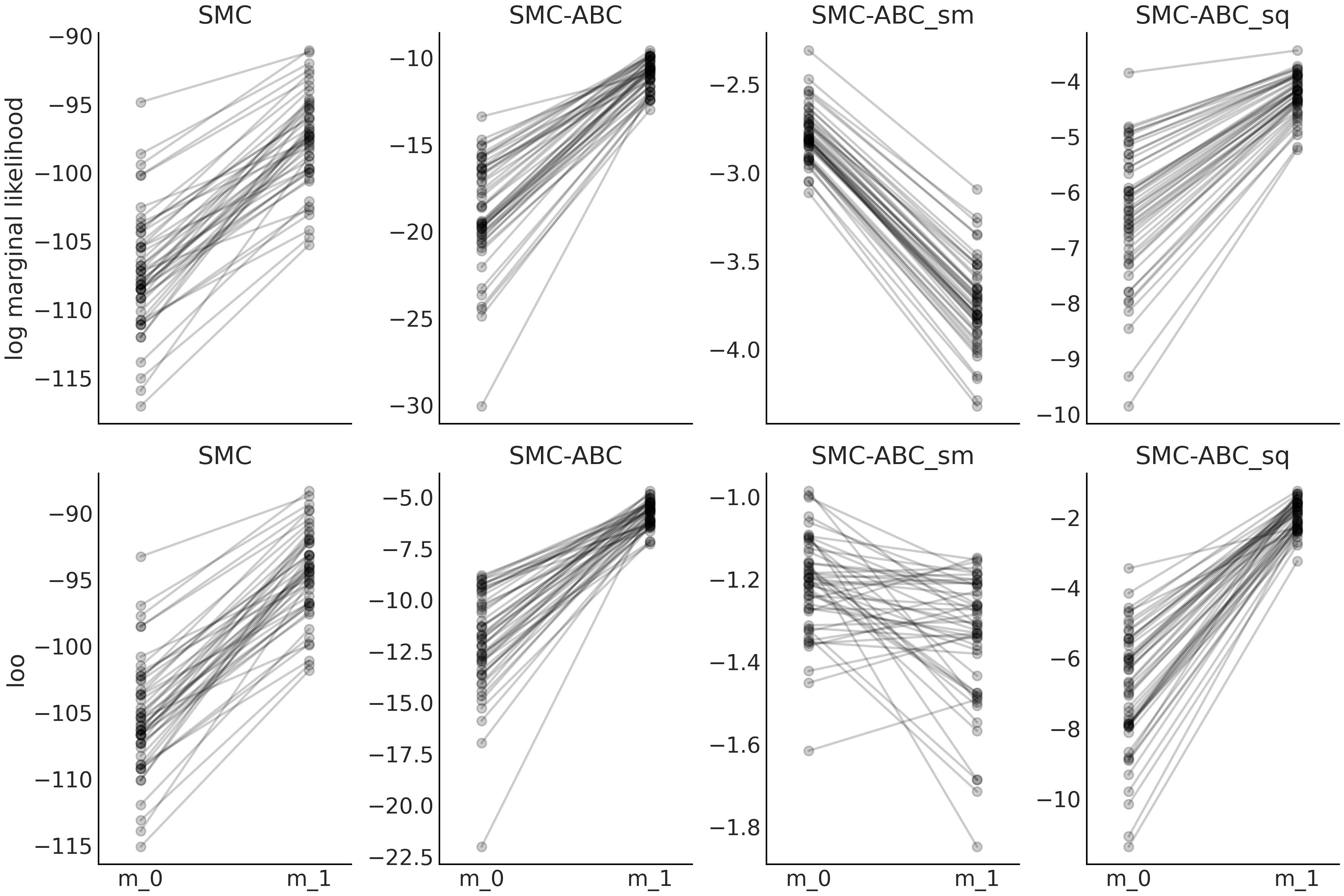
Fig. 148 模型 m_0 是先验为 \(p \sim \mathcal{U}(0, 1)\) 的几何分布,而 model_1 是先验为 \(\mu \sim \mathcal{E}(1)\) 的泊松分布。数据服从移位的泊松分布 \(\mu \sim 1 + \text{Pois}(2.5)\)。序贯蒙特卡洛( SMC )、完整数据集的近似贝叶斯计算( SMC-ABC )、 使用均值作为统计量的近似贝叶斯计算(SMC-ABC_sm)、使用均值和标准差统计量的近似贝叶斯计算(SMC-ABC_sq )。 我们进行了 \(50\) 次实验,每次实验的样本量为 \(50\)。¶
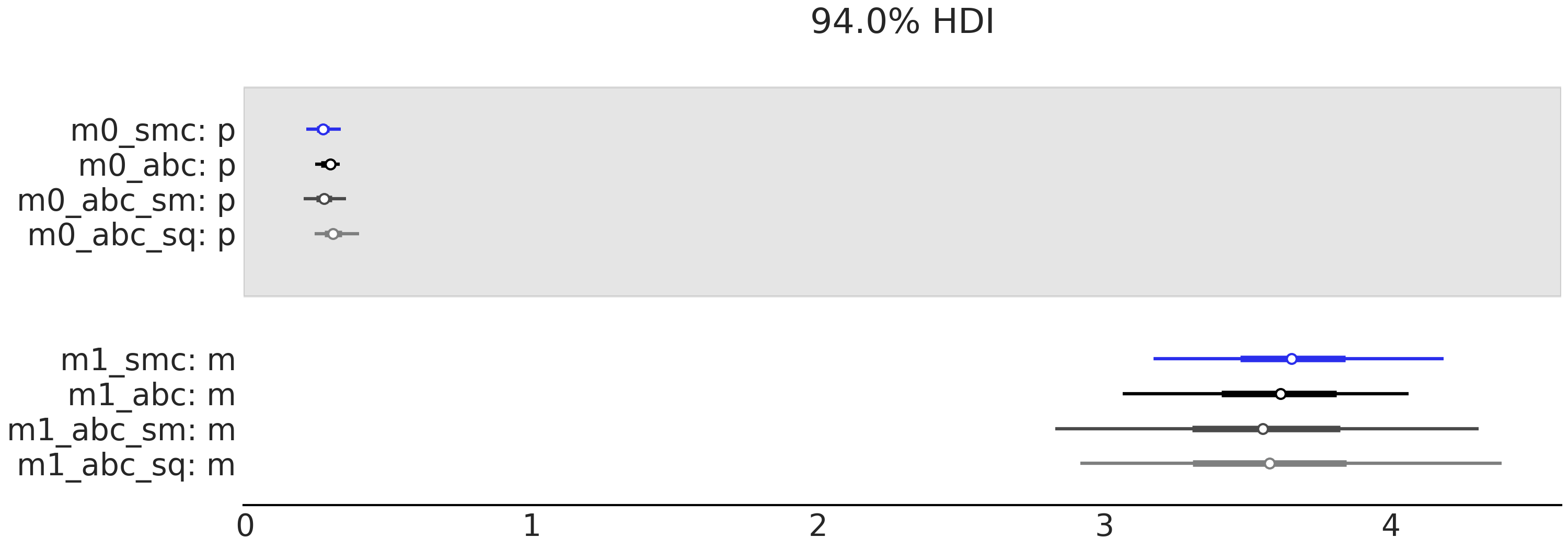
Fig. 149 model_0 是先验为 \(p \sim \mathcal{U}(0, 1)\) 的几何模型/模拟器 model_1 是先验为 \(p \sim \text{Expo}(1)\) 的泊松模型/模拟器。第一行包含边缘似然值,第二行包含 LOO 值。各列表示计算这些值的不同方法:序贯蒙特卡洛( SMC )、完整数据集的近似贝叶斯计算( SMC-ABC )、 使用均值作为统计量的近似贝叶斯计算(SMC-ABC_sm)、使用均值和标准差统计量的近似贝叶斯计算(SMC-ABC_sq )。 我们进行了 \(50\) 次实验,每次实验的样本量为 \(50\)。¶
在近似贝叶斯计算的文献中,常使用贝叶斯因子来尝试将相对概率分配给模型,而这在某些领域是有价值的。所以我们想提醒那些从业者,在近似贝叶斯计算框架下这种做法存在一些潜在问题,特别是在实际应用中使用统计量比不使用统计量的情况要普遍得多。
模型比较仍然有用,主要是如果采用更具探索性的方法以及在模型比较之前执行模型批判以改进或丢弃明显错误指定的模型。这是在本书中为非近似贝叶斯计算方法采用的一般方法,因此我们认为将其扩展到近似贝叶斯计算框架也很自然。本书中也偏爱 LOO 而不是边缘似然,尽管目前尚缺少有关近似贝叶斯计算方法中 LOO 优缺点的研究,但我们认为 LOO 也可能对近似贝叶斯计算方法有用。请大家继续关注未来的消息!
模型批判和模型比较
虽然总是会出现一些错误指定,但模型比较可以帮助我们更好地理解模型及其错误指定。只有在我们证明模型对数据提供了合理的拟合之后,才应该进行模型比较。比较明显未拟合的模型没有太大意义。
8.7.2 随机森林法¶
我们在上一节中讨论的一些注意事项促进了近似贝叶斯计算框架下模型选择新方法的研究。其中一种替代方法是将模型选择问题定义为随机森林分类问题 [99] 11。随机森林是一种基于许多决策树的组合分类和回归方法,它与 第 7 章 中的 BART 密切相关。
该方法的主要思想是:最可能的模型可以从先验或后验预测分布的模拟样本中通过构建随机森林分类器获得。在原始论文中,作者使用了先验预测分布,但也提到对于更高级的近似贝叶斯计算方法,可以使用其他分布。在这里,我们将使用后验预测分布。对于 \(m\) 个模型,模拟数据在参考表中进行了排序,参见 Table 15 。
其中每一行是来自后验预测分布的一个样本,每一列是 \(n\) 个统计量之一。我们使用这个参考表来训练分类器,其任务是在给定统计量值的情况下,正确分类模型。重要的是要注意,用于模型选择的统计量和用于计算后验的统计量不一定相同。事实上,建议包括更多的统计量信息。一旦分类器训练完成,我们就使用和参考表中相同的 \(n\) 个统计量作为其输入,不过这次统计量的值来自于观测数据。分类器预测的模型将是最佳模型。
Model |
\(\mathbf{S^{0}}\) |
\(\mathbf{S^{1}}\) |
… |
\(\mathbf{S^{n}}\) |
0 |
… |
|||
0 |
… |
|||
… |
… |
… |
… |
… |
1 |
… |
|||
1 |
… |
|||
m |
… |
此外,还可以计算最佳模型相对于其他模型的近似后验概率。再一次,可以使用随机森林来实现,但这次使用回归,将错误分类的错误率作为结果变量,将参考表中的统计量作为自变量 [99]。
8.7.3 移动平均模型的模型选择¶
让我们回到移动平均的例子,这次将重点关注以下问题。 \(MA(1)\) 或 \(MA(2)\) 是更好的选择吗?为了回答这个问题,我们将使用 LOO(基于逐点伪似然值)和随机森林法。 \(MA(1)\) 模型看起来像这样:
with pm.Model() as m_ma1:
θ1 = pm.Uniform("θ1", -1, 1)
y = pm.Simulator("y", moving_average_1,
params=[θ1], sum_stat=autocov, epsilon=0.1, observed=y_obs)
trace_ma1 = pm.sample_smc(2000, kernel="ABC")
为了比较使用 LOO 的近似贝叶斯计算模型,不能直接使用 az.compare 函数。我们需要首先创建一个带有 log_likelihood 组的 InferenceData 对象,详见代码 idata_pseudo 12。此比较的结果汇总在 Table 16 中,可以看到 \(MA(2)\) 模型是首选。
idata_ma1 = az.from_pymc3(trace_ma1)
lpll = {"s": trace_ma2.report.log_pseudolikelihood}
idata_ma1.log_likelihood = az.data.base.dict_to_dataset(lpll)
idata_ma2 = az.from_pymc3(trace_ma2)
lpll = {"s": trace_ma2.report.log_pseudolikelihood}
idata_ma2.log_likelihood = az.data.base.dict_to_dataset(lpll)
az.compare({"m_ma1":idata_ma1, "m_ma2":idata_ma2})
rank |
loo |
p_loo |
d_loo |
weight |
se |
dse |
warning |
loo_scale |
|
model_ma2 |
0 |
-2.22 |
1.52 |
0.00 |
1.0 |
0.08 |
0.00 |
False |
log |
model_ma1 |
1 |
-3.53 |
2.04 |
1.31 |
0.0 |
1.50 |
1.43 |
False |
log |
要使用随机森林法,可以使用本书随附代码中包含的 select_model 函数。为了使该函数工作,我们需要传递一个包含模型名称和轨迹的元组列表、一个统计量列表和观测数据。作为统计量,我们将使用前六个自相关。选择这些统计量有两个原因:第一个表明我们可以使用一组不同于拟合数据的统计量;第二个表明我们可以混合有用的统计量(前两个自相关)和不是非常有用的统计量(其余的)。请记住,理论说,对于一个 \(MA(q)\) 过程,最多有 \(q\) 个自相关。对于复杂问题,例如群体遗传学问题,使用数百甚至数万个统计量数据的情况并不少见 [109]。
from functools import partial
select_model([(m_ma1, trace_ma1), (m_ma2, trace_ma2)],
statistics=[partial(autocov, n=6)],
n_samples=5000,
observations=y_obs)
select_model 返回最佳模型的索引值(从 \(0\) 开始)和估计得出的模型后验概率。对于示例,我们得到模型 \(0\) 的概率为 \(0.68\) 。在这个例子中,LOO 和随机森林法都同意模型选择结论,甚至模型间的相对权重,这让人比较放心。
8.8 为近似贝叶斯计算选择先验¶
没有封闭形式的似然使得好模型更加难以得到,因此近似贝叶斯计算方法通常比其他近似解更脆弱。因此,我们应格外小心一些建模的选择,包括先验的选择和比有明确似然时更严谨的模型评估。这些都是为获得近似似然而必须付出的成本。
与其他方法相比,在近似贝叶斯计算方法中更仔细的选择先验,可能比在其他方法中更有价值。如果在近似似然时会丢失信息,那我们希望通过包含更多信息的先验来进行部分补偿。此外,更好的先验通常会使我们免于浪费计算资源和时间。对于近似贝叶斯计算拒绝方法,我们使用先验作为采样分布,这是显而易见的。但 SMC 方法也是如此,特别是模拟器对输入参数比较敏感时。例如,当使用近似贝叶斯计算推断常微分方程时,某些参数组合可能难以进行数值模拟,从而导致模拟速度极慢。在 SMC 和 SMC-ABC 的加权采样过程中出现了使用模糊先验的另一个问题,因为在对退火后验进行评估时,除了少数先验样本外,几乎所有样本的权重都非常小。这导致 SMC 粒子在几个步骤后变得奇异( 因为只选择了少数重量较大的样本 )。这种现象称为权重崩塌,这也是粒子方法的一个众所周知的问题 [110] 。
良好的先验可以降低计算成本,从而在一定程度上允许我们使用 SMC 和 SMC-ABC 拟合更复杂的模型。除了提供信息性更强的先验和在本书中讨论过的有关先验选择/评估的内容之外,我们暂时没有针对近似贝叶斯计算方法的进一步推荐。
习题¶
8E1. In your words explain how 近似贝叶斯计算 is approximate? What object or quantity is approximated and how.
8E2. In the context of 近似贝叶斯计算,what is the problem that SMC is trying to solve compared to rejection sampling?
8E3. Write a Python function to compute the Gaussian kernel as in Equation (74), but without the summation.
Generate two random samples of size 100 from the same distribution. Use the implemented function to compute the distances between those two random samples. You will get two distributions each of size 100. Show the differences using a KDE plot, the mean and the standard deviation.
8E4. What do you expect to the results to be in terms of accuracy and convergence of the sampler if in model gauss model from Code Block gauss_abc we would have used sum_stat="identity". Justify.
8E5. Refit the gauss model from Code Block gauss_abc using sum_stat="identity".
Evaluate the results using:
Trace Plot
Rank Plot
\(\hat R\)
The mean and HDI for the parameters \(\mu\) and \(\sigma\).
Compare the results with those from the example in the book (i.e. using sum_stat="sort").
8E6. Refit the gauss model from Code Block gauss_abc using quintiles as summary statistics.
How the results compare with the example in the book?
Try other values for
epsilon. Is 1 a good choice?
8E7. Use the g_and_k_quantile class to generate a sample (n=500) from a g-and-k distribution with parameters a=0,b=1,g=0.4,k=0. Then use the gkm model to fit it using 3 different values of \(\epsilon\) (0.05, 0.1, 0.5). Which value of \(\epsilon\) do you think is the best for this problem? Use diagnostics tools to help you answer this question.
8E8. Use the sample from the previous exercise and the gkm model. Fit the using the summary statistics octo_summary, the octile-vector (i.e. the quantiles 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875) and sum_stat="sorted". Compare the results with the known parameter values, which option provides higher accuracy and lower uncertainty?
8M9. In the GitHub repository you will find a dataset of the distribution of citations of scientific papers. Use SMC-ABC to fit a g-and-k distribution to this dataset. Perform all the necessary steps to find a suitable value for "epsilon" and ensuring the model converge and results provides a suitable fit.
8M10. The Lotka-Volterra is well-know biological model describing how the number of individuals of two species change when there is a predator-prey interaction [111]. Basically, as the population of prey increase there is more food for the predator which leads to an increase in the predator population. But a large number of predators produce a decline in the number of pray which in turn produce a decline in the predator as food becomes scarce. Under certain conditions this leads to an stable cyclic pattern for both populations.
In the GitHub repository you will find a Lotka-Volterra simulator with unknown parameters and the data set Lotka-Volterra_00. Assume the unknown parameters are positive. Use a SMC-ABC model to find the posterior distribution of the parameters.
8H11. Following with the Lotka-Volterra example. The dataset Lotka-Volterra_01 includes data for a predator prey with the twist that at some point a disease suddenly decimate the prey population. Expand the model to allow for a “switchpoint”, i.e. a point that marks two different predator-prey dynamics (and hence two different set of parameters).
8H12. This exercise is based in the sock problem formulated by Rasmus Bååth. The problem goes like this. We get 11 socks out of the laundry and to our surprise we find that they are all unique, that is we can not pair them. What is the total number of socks that we laundry? Let assume that the laundry contains both paired and unpaired socks, we do not have more than two socks of the same kind. That is we either have 1 or 2 socks of each kind.
Assume the number of socks follows a \(\text{NB}(30, 4.5)\). And that the proportion of unpaired socks follows a \(\text{Beta}(15, 2)\)
Generate a simulator suitable for this problem and create a SMC-ABC model to compute the posterior distribution of the number of socks, the proportion of unpaired socks, and the number of pairs.
参考文献¶
- 1
It can work for discrete variables, especially if they take only a few possible values.
- 2
This is another manifestation of the curse of dimensionality. See Section 11.8 走出平地 for a full explanation.
- 3
The default SMC
kernelis"metropolis". See 11.9 推断方法 for details.- 4
Is similar to the Gaussian distribution but without the normalization term \(\frac{1}{\sigma\sqrt{2\pi}}\).
- 5
This is something PyMC3 does, other packages could be different
- 6
Even when PyMC3 uses
sum_stat="sort"as summary statistic, sorting is not a true summary as we are still using the whole data- 7
In a similar fashion as the \(\beta\) parameters in the description of the SMC/ SMC-ABC algorithm explained before
- 8
In Prangle [102] you will find a description of an R package with a lot of functions to work with g-and-k distributions.
- 9
In the literature is common to use \(\varepsilon\) to denote these terms, but we want to avoid confusion with the \(\epsilon\) parameter in the SMC-ABC sampler
- 10
Good moment to remember that
sum_stat="sort"is not actually a summary statistic as we are using the entire dataset- 11
Other classifiers could have been chosen, but the authors decided to use a random forest.
- 12
In future versions of PyMC
pm.sample_smcwill return and InferenceData object with the proper groups.