4.4 逻辑斯蒂回归
Contents
4.4 逻辑斯蒂回归¶
逻辑斯蒂回归来自用 \(x\) 的线性函数来建立 \(K\) 个类别后验概率模型的需要,同时保证后验概率的和为 1 且每一个都落在 \([0,1]\)。模型有如下形式
模型由 \(K-1\) 个 log-odds 或 logit 变换来确定(反映了概率之和为 1 的约束)。虽然模型采用最后一类来作为 odds-ratios 的分母,但分母的选择其实是任意的,因为在这个选择下估计值是等价的。简单地计算可以得到
显然它们相加等于 1。为了强调对参数集 \(\theta=\\{\beta_{10},\beta_1^T,\ldots,\beta_{(K-1)0},\beta_{K-1}^T\\}\) 的依赖,我们将概率记为 \(p_k(x,\theta)\)。
note “weiya 注:” 与从 式( 4.17 ) 中的两两比较出发得到 式( 4.18 ) 式不同的是,PRML 中 4.3.4 节直接定义 \(\mathrm{Pr}(G=k\mid X=x)\),
\[ \mathrm{Pr}(G=k\mid X=x) = \frac{\exp(\beta_k^Tx)}{\sum_\ell \exp(\beta_\ell^Tx)}\,, >\]这样会得到 \(K\) 个系数向量,比 式( 4.18 ) 多一个。
对于多类别
multi_class = 'multinomial',sklearn.linear_model.LogisticRegression采用这种形式,因而其系数矩阵维度为 \(K\times p\). 另外也可以采用One-vs-Rest的思路multi_class = 'ovr',即 \(K\) 个二分类问题,依次将所考虑的类视为类别 1,而其余类为类别 0。
当 \(K=2\) 时,模型非常简单,因为只有一个单线性函数。在生物统计应用中应用很广,因为经常会有二进制(两个类别)的响应变量。举个例子,病人获救或死亡,患心脏病和不患心脏病,或者某个条件存在与否。
( 1 )拟合逻辑斯蒂回归模型¶
逻辑斯蒂回归经常通过极大似然法求解,采用在给定 \(X\) 时 \(G\) 的条件概率。因为 \(\mathrm{Pr}(G\mid X)\) 完全明确了条件分布,选择 多项式分布 (multinomial) 是合适的。
note “weiya 注:多项式分布的合理性” 因为条件概率之和等于 1,而各个条件概率可以看成是互斥事件的概率,满足多项式分布的条件。
\(N\) 个观测的对数似然为
其中,\(p_k(x_i;\theta)=\mathrm{Pr}(G=k\mid X=x_i;\theta)\)
我们将详细讨论两个类别的情形,因为此时算法可以非常简化。我们可以用 0/1 来对两个类别 \(g_i\) 的响应变量 \(y_i\) 进行编码,当 \(g_i=1\) 时 \(y_i=1\),当 \(g_i=2\) 时 \(y_i=0\)。令 \(p_1(x;\theta)=p(x,\theta)\),\(p_2(x;\theta)=1-p(x;\theta)\),对数似然为
这里 \(\beta=\\{\beta_{10},\beta_1\\}\),而且我们假设输入向量 \(x_i\) 包含表示截距的项 \(1\)。
为了最大化对数似然,令微分为 0,得到
这是关于 \(\beta\) 的 \(p+1\) 个非线性等式。注意到因为 \(x_i\) 的第一个组分为 1,第一个组分满足的等式为 \(\sum_{i=1}^Ny_i=\sum_{i=1}^Np(x_i;\beta)\);这表明类别一概率的期望值与观测值一致(也因此类别二概率的期望值与观测值一致)。
为了求解 式( 4.21 ) 的得分等式,我们采用 Newton-Raphson 算法,需要 Hessian 矩阵
以 \(\beta^{old}\) 开始,新的 Newton 更新为
其中微分值由 \(\beta^{old}\) 处的值得到。
把得分和 Hessian 写成矩阵形式是很方便的。记 \(\mathbf y\) 为 \(y_i\) 的值,\(\mathbf X\) 是 \(x_i\) 的 \(N\times (p+1)\) 矩阵,\(\mathbf p\) 是拟合概率的向量且第 \(i\) 个元素为 \(p(x_i;\beta^{old})\),\(\mathbf W\) 是第 \(i\) 个对角元为 \(p(x_i;\beta^{old})(1-p(x_i;\beta^{old}))\) 的 \(N\times N\) 的对角矩阵。则我们有
牛顿迭代为
在第二和第三行我们已经重新把牛顿迭代表达成最小二乘迭代,响应变量为
有时也被称作 调整后的响应变量 (adjusted response)。重复地进行求解这些方程,每一次迭代时,\(\mathbf p\) 改变,因此 \(\mathbf W\) 和 \(\mathbf z\) 也改变。这个算法被称作 加权迭代最小二乘 (iteratively reweighted least squares) 或者 IRLS,因为每次迭代求解加权最小二乘问题:
note “weiya注:IRLS” Github: xqwen/IRLS用C++实现IRLS。
似乎\(\beta=0\)是迭代过程一个很好的初始值,尽管不会保证收敛性。一般地,算法确实是收敛的,因为对数似然是 凹的 (concave),但是可能出现过收敛的情况。如果在罕见的情形下对数似然值下降,对步长进行折半会保证收敛性。
note “weiya 注:” 首先对于凸函数 (convex function),其局部最优点即为全局最优点,所以总是 (?) 可以收敛到最优点的,除非数值不稳定,比如矩阵的条件数过大。而凹函数取负号就变成了凸函数。 步长折半 (step size halving):
对于多类别的情况 \(K\ge 3\),牛顿算法也可以表达成加权迭代最小二乘,只是对于每一个观测用一个 \(K-1\) 的响应向量和非对角系数矩阵。后者阻碍了算法的简化,在这种情况下直接使用展开向量 \(\theta\) 数值上会更加方便(练习 4.4)。另一种是坐标下降方法(3.8.6 节)也可以有效地最大化对数似然。R语言的 glmnet 包 (Friedman et al., 20101) 可以有效地拟合 \(N\) 和 \(p\) 都非常大时的逻辑斯蒂回归。尽管是为了拟合正则化模型设计的,但是也适用于非正则化的拟合。
逻辑斯蒂回归经常被用作一种数据分析和推断的工具,目标就是理解在解释输出时输入变量的角色。一般地,拟合时要寻找变量的**最简洁 (parsimonious)**的模型,很可能还有一些交互项。下面的例子说明了涉及到的一些问题。
( 2 )例子:南非心脏病¶
这里我们展示一个用二值数据分析去说明逻辑斯蒂回归的传统统计学应用。图4.12中的数据取自CORIS调查的部分数据,这个调查在南非Western Cape的三个乡村进行(Rousseauw et al., 19832)。调查的目标是建立在高发生率的地区中缺血性心脏病影响因子的强度模型。数据中有15到64岁的白人男性,响应变量是MI的存在或者缺失(该地区整个 MI 流行程度为5.1%)。在我们数据集中有160个案例,以及302个控制个体。数据在Hastie and Tibshirani(1987)3中有详细描述。
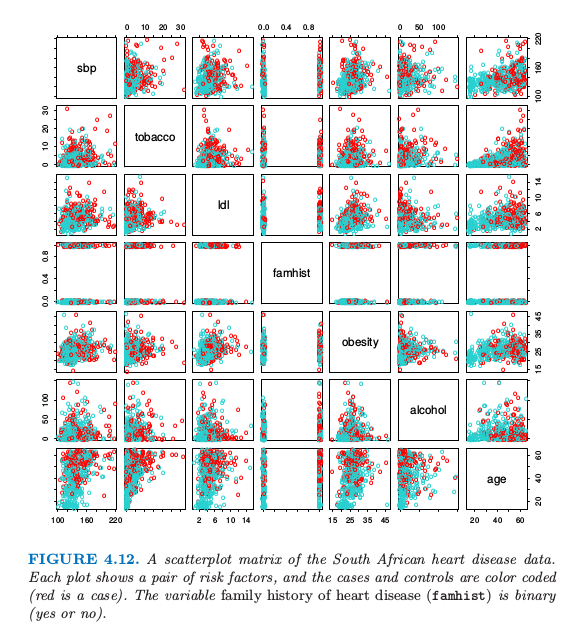
图4.12. 南非心脏病数据的散点图。每张图片是一对影响因子,案例集和控制集用不同颜色区分(红色的为案例)。家族心脏病史(famhist)是二值变量(是或否)
我们通过极大似然法拟合了逻辑斯蒂回归模型,给出了如表 4.2 所示的结果。结果概要包含了模型中每一个系数的 \(Z\) 分数(系数除以他们的标准差);不重要的 \(Z\) 分数表明该系数可以从模型中剔除。这对应着检验该系数为 0 而其它系数不为 0 的零假设(也被称作 Wald 检验)。\(Z\) 分数的绝对值大于 2 表明在 \(5\%\) 的水平下是显著的。
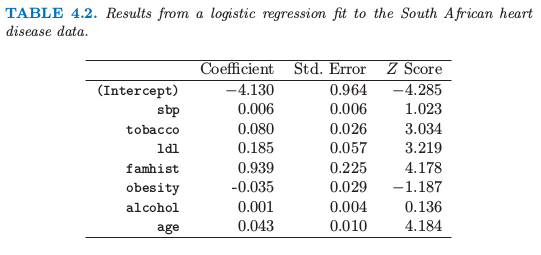
表4.2. 南非心脏病数据的逻辑斯蒂回归结果。
在系数表中有一些比较奇怪的结果,这必须认真对待。收缩压 sbp 竟然不显著!肥胖 (obesity) 也不显著,它的符号是负的。这个混乱是因为预测变量之间的相关关系。单独地来看,sbp 和 obesity 都是显著的,而且都是正号。然而,当有其它相关变量时它们便不再需要了(甚至可以得到一个负号)。
这时分析者可能会做一些模型选择;寻找能够充分解释他们在 chd 上联合影响的子集变量。一种方式是删掉显著性最低的系数然后重新拟合模型。这个可以重复做下去直到没有更多的项可以从模型中剔除。这样得到了表 4.3 所示例的模型。
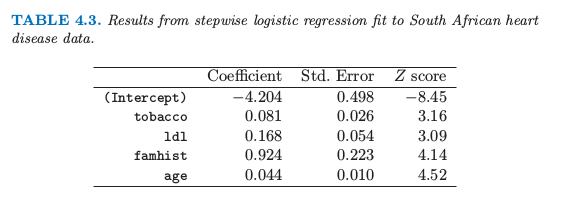
表4.3. 对南非心脏病数据逐步逻辑斯蒂回归的结果
一个更好但是需要花费更多时间的策略是对每一个剔除一个变量后的模型进行重新拟合,然后进行 偏差分析 (analysis of deviance) 确定哪个变量需要剔除。拟合模型的**残偏差 (residual deviance)**是负的两倍的对数似然,两个模型的偏差是它们个体残偏差的差别(类似于平方和),这个策略给出了上面同样的最终结果。
举个例子,怎么解释 tobacco 的系数 0.081(标准偏差为 0.026)?tobacco 是整个时间段中使用的烟草总千克数,控制集 (controls) 中位数为 1.0kg,而这个案例集 (cases) 为 4.1kg。因此每增加 1kg 的烟草使用量意味着冠状心脏病的几率为 \(\exp(0.081)=1.084\)(或者 8.4%)。结合标准差我们得到 95%的置信区间 \(\exp(0.081\pm 2\times 0.026)=(1.03,1.14)\)
我们将在第 5 章再次用到这些数据,我们将会看到一些变量会有非线性影响,当进行合适的建模后不会被剔除模型。
( 3 )二次拟合和推断¶
极大似然法的参数估计 \(\hat\beta\) 满足 自一致性 (self-consistency) 关系:它们是加权最小二乘拟合的系数,其中响应变量为
系数为 \(w_i=\hat p_i(1-\hat p_i)\),都依赖 \(\hat\beta\) 自身。除了提供了一个方便的算法,这与最小二乘的联系还有其它用处:
加权的残差平方和是熟悉的 Pearson 卡方统计量
这是对偏差的二次近似。
极限概率理论表明如果模型是正确的,则 \(\hat\beta\) 为常数(即收缩到真实的 \(\beta\))
中心极限定理证明 \(\hat \beta\) 的分布收敛到 \(N(\beta,\mathbf{(X^TWX)^{-1}})\)。这个可以模仿正态理论推断直接从加权最小二乘得到。
对于逻辑斯蒂回归建立模型计算量比较大,因为每个模型拟合需要迭代。受欢迎的方法是 Rao score 检验来检验是否包含某一项,以及 Wald 检验来检验是否剔除某一项。这些都不需要迭代拟合,而且都是基于当前模型的极大似然拟合。结果是两者都代表在加权最小二乘拟合中运用相同的系数加上或剔除某一项。这些计算可以高效地进行,不需要重新计算整个加权最小二乘拟合。
软件实现可以利用这些联系。举个例子,R 中的广义线性模型(包括作为二项式模型族中的逻辑斯蒂回归)充分运用了他们。**GLM(广义线性模型)**对象可以当作线性模型对象来处理,而且所有对于线性模型可用的工具都可以自动应用起来。
( 4 )\(L_1\)正则化逻辑斯蒂回归¶
Lasso 中使用的 \(L_1\) 惩罚(3.4.2节)可以应用到任意线性回归模型的变量选择和收缩上面。对于逻辑斯蒂回归,我们最大化 式( 4.20 ) 带惩罚项的版本:
对于 lasso,我们一般不对截距项进行惩罚,对预测变量标准化后加惩罚才有意义。准则 式( 4.31 ) 是凹的,而且运用非线性规划方法可以找到一个解(举个例子,Koh et al., 20074)。另外,运用我们在 4.4.1 节运用的 Netwon 算法的二次逼近,我们可以通过重复应用加权的 lasso 算法求解 式( 4.31 )。有趣的是非零系数变量的得分等式(式( 4.24 ))有如下形式
这一般化了 3.4.4 节 中的 式( 3.58 );活跃变量再与残差的一般化相关性结合在一起。
回顾
\[ \mathbf x_j^T(\mathbf y-\mathbf X\beta)=\lambda\cdot \mathrm{sign}(\beta_j),\forall j\in {\mathcal B}\tag{3.58} >\]
路径算法(比如 lasso 的 LAR 算法)变得更加困难,因为系数曲线是逐段光滑而不是线性的。然而,可以通过二次逼近来实现。
图 4.13 显示了 4.4.2 节南非心脏病数据的 \(L_1\) 正则化路径。这是通过 R 语言glmpath包 (Park and Hastie, 20074) 实现的,运用了凸优化的 predictor-corrector 方法确定了 \(\lambda\) 在哪个非零活跃集值发生改变(图中的垂直线)。这里直线看似线性的,但在其它的例子中曲率将会更加明显。
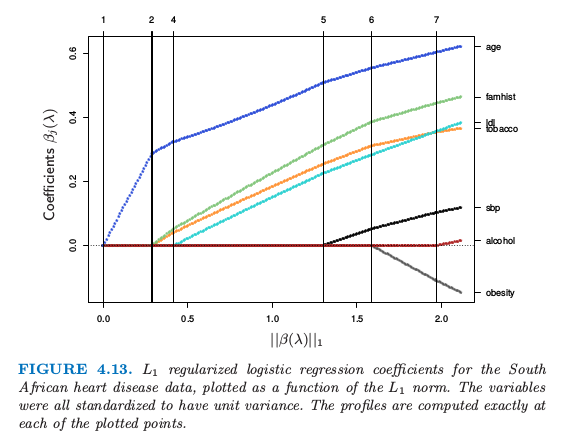
图 4.13. 南非心脏病数据的 \(L_1\) 正则化逻辑斯蒂回归系数,画出了作为 \(L_1\) 范数函数的曲线。这些变量都标准化后得到单位方差。在图像每一个点处都精确算出来了。
坐标下降方法(3.8.6 节)对于计算 \(\lambda\) 网格上的值的系数曲线是很有效的。R 语言 glmnet 包 (Friedman et al., 20101) 对于非常大的逻辑斯蒂回归问题拟合系数路径是非常有效的(\(N\) 或 \(p\) 很大时)。他们的算法可以利用预测变量矩阵 \(X\) 的稀疏性,以至于对于大规模问题也适用。18.4 节有更详细的解释,而且将会讨论 \(L_1\) 正则多项分布模型。
( 5 )逻辑斯蒂回归或者 LDA?¶
info 基于本小节内容,回答了Logistic回归模型和判别分析之间的关系? - 知乎。
在 4.3 节我们发现类别 \(k\) 和 \(K\) 类关于 \(x\) 线性函数的后验概率 odds 的对数 式( 4.9 ):
回顾
$$
$$
线性是因为对类别的概率密度函数做了正态性假设及协方差矩阵相等的假设。通过构造线性逻辑斯蒂模型 式( 4.17 ) 有线性 logits:
看起来模型似乎是一样的。尽管它们确实有相同的形式,区别在于它们系数估计的方式。逻辑斯蒂回归模型更加一般,因为它做了更少的假设。我们可以把 \(X\) 和 \(G\) 的联合概率密度写成
其中 \(\mathrm{Pr}(X)\) 为 \(X\) 的边缘概率密度。对于 LDA 和逻辑斯蒂回归,右边的第二项有线性 logit 形式
我们再一次任意地选择最后一类作为标准。
逻辑斯蒂回归模型中,\(X\) 的边缘概率密度可以取任意的边界密度函数 \(\mathrm{Pr}(X)\),然后通过最大化条件概率(\(\mathrm{Pr}(G=k\mid X)\)的多项式概率)来拟合 \(\mathrm{Pr}(G\mid X)\) 的参数。尽管可以完全忽略掉 \(\mathrm{Pr}(X)\),但我们可以把边缘密度看成在全非参和无约束情形下的估计,即采用在每个观测值上权重为 \(1/N\) 的经验分布。
进行 LDA 时,我们通过基于下面的联合密度来最大化对数似然进行拟合参数
其中 \(\phi\) 是高斯密度函数。用标准正态的理论可以很容易估计 4.3 节的 \(\hat\mu_k,\hat\Sigma\) 和 \(\hat\pi_k\)。因为 式( 4.33 ) 形式的逻辑斯蒂回归的线性参数是高斯分布参数的函数,我们通过插入对应的估计得到它们的极大似然估计。然而,与条件概率密度不同,边缘密度 \(\mathrm{Pr}(X)\) 起着重要作用。它是一个混合密度
同样涉及到参数。
这个额外的组分(约束条件)起着什么作用呢?通过依赖额外的模型假设,我们可以得到更多的参数信息,因此可以更加有效地估计它们(低方差)。事实上,如果 \(f_k(x)\) 的真实分布为高斯分布,则在最坏的情形下忽略密度的边缘项会在误差率上有近 \(30\%\) 的效率损失 (Efron, 19756)。换句话说:当再有 \(30\%\) 的数据,条件概率才会达到一样的效果。
举个例子,远离判别边界的观测点(权重被逻辑斯蒂回归 低估 (down-weighted))在估计斜方差阵中起着作用。这完全不是一个好消息,因为这意味着当有许多的边界点时,LDA 不够稳健。
从混合模型的组成来看,很显然没有类别标签的观测甚至都有参数的信息。产生类别标签经常是不划算的,但是产生未分类的观测值是容易的。通过依赖对模型强的假设,正如这里的一样,我们可以同时运用两种类型的信息。
边缘似然 (marginal likelihood) 可以认为是一个正则器,从边缘角度来看在某种程度上类别密度是已知的。举个例子,如果在两个类别的逻辑斯蒂回归模型中,数据可以很好地被超平面分隔开,则参数的极大似然估计是没有定义的(比如说无穷,见练习 4.5)。而对于同样的数据 LDA 的系数有很好的定义,因为边缘密度函数不会允许这些退化。
实际应用中这些假设从不正确,而且 \(X\) 的有些组分是定性变量。一般感觉逻辑斯蒂回归更加安全,比 LDA 模型更稳健,因为它依赖更少的假设。从我们经验来看,即便不恰当地运用 LDA,比如说对定性预测变量应用 LDA,两个模型都会得到非常相似的结果。
- 1(1,2)
Friedman, J., Hastie, T. and Tibshirani, R. (2010). Regularization paths for generalized linear models via coordinate descent, Journal of Statistical Software 33(1): 1–22.
- 2
Rousseauw, J., du Plessis, J., Benade, A., Jordaan, P., Kotze, J., Jooste, P. and Ferreira, J. (1983). Coronary risk factor screening in three rural communities, South African Medical Journal 64: 430–436.
- 3
Hastie, T. and Tibshirani, R. (1987). Nonparametric logistic and proportional odds regression, Applied Statistics 36: 260–276.
- 4(1,2)
Park, M. Y. and Hastie, T. (2007). l1-regularization path algorithm for generalized linear models, Journal of the Royal Statistical Society Series B 69: 659–677.
- 6
Efron, B. (1975). The efficiency of logistic regression compared to normal discriminant analysis, Journal of the American Statistical Association 70: 892–898.