10.1 boosting方法
Contents
10.1 boosting方法¶
note “更新笔记” @2017.08.26 很早以前,略读了杨灿学长的《统计学习那些事》,但其实没什么感受,因为当时也没看到 boosting,对 lasso 了解也不多。而当我早早完成 boosting 的翻译后,又一直搁着没有再次阅读学长的文章。杨灿学长用风趣的笔墨从 lasso 和 boosting 的发展来看统计学习的那些事,个人觉得对于了解统计大佬们开创这些“绝世武功”的历史进程是很有帮助的。杨灿学长的《昔日因,今日意》和《那些年,我们一起追的 EB》,我也是非常喜欢的,相信看了这么有趣的标题,不去拜读都不行啊hhh:grinning:在今年北京 R 会议上还听了杨灿学长的汇报,报告的主题也是跟 boosting 有关,当时还激动地跟他互动了一下,提了几个问题 :raised_hand:。也是从那时候才知道,杨灿学长原来还是校友。
Boosting 是最近 20 年内提出的最有力的学习方法。最初是为了分类问题而设计的,但是我们将在这章中看到,它也可以很好地扩展到回归问题上。Boosting的动机是集合许多弱学习的结果来得到有用的“committee”。从这点看 boosting 与 bagging 以及其他的基于 committee 的方式(8.8 节)类似。然而,我们应该看到这种联系最多是表面上的,boosting 在根本上存在不同。
我们以最流行的被称为 “AdaBoost.M1” 的 boosting 算法开始,这归功于 Freund and Schapire (1997)1。考虑两个类别的分类问题,输出变量编码为 \(Y\in\\{-1,1\\}\)。给定预报向量 \(X\),分类器 \(G(X)\) 在二值 \(\\{-1,1\\}\) 中取一个值得到一个预测。在训练样本上的误差率是
在未来预测值上的期望误差率为 \(E_{XY}I(Y\neq G(X))\)
弱分类器是误差率仅仅比随机猜测要好一点的分类器。Boosting 的目的是依次对反复修改的数据应用弱分类器算法,因此得到弱分类器序列 \(G_m(x),m=1,2,\ldots,M\) 根据它们得到的预测再通过一个加权来得到最终的预测
\( G(x)=\mathrm {sign}\left(\sum\limits_{m=1}^M\alpha_mG_m(x)\right)\tag{10.1} \)$
这里 \(\alpha_1,\alpha_2,\ldots,\alpha_M\) 通过 boosting 算法进行计算,它们对每个单独的 \(G_m(x)\) 的贡献度赋予权重。它们的作用是赋予分类器序列中更精确的分类器更大的影响力。图 10.1 显示了 AdaBoost 过程的概要图。
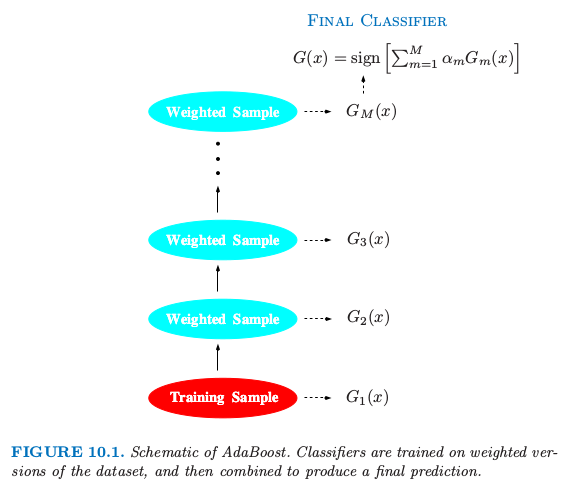
图 10.1. AdaBoost 的概要图。分类器在加权的数据集上进行训练,接着结合起来产生最终的预测。
在每步 boosting 的数据修改时,对每个训练观测 \((x_i,y_i),i=1,2,\ldots,N\) 赋予权重 \(w_1,w_2,\ldots,w_N\)。初始化所有的权重设为 \(w_i=1/N\),使得第一步以通常的方式对数据进行训练分类器。对每个接下来的迭代 \(m=2,3,\ldots,M\),单独修改观测的权重,然后将分类算法重新应用到加权观测值上。在第 \(m\) 步,上一步中被分类器 \(G_{m-1}(x)\) 的误分类的观测值增大了权重,而正确分类的观测值权重降低了。因此当迭代继续,很难正确分类的观测受到越来越大的影响。每个相继的分类器因此被强制集中在上一步误分类的训练数据上。
算法 10.1 展示了 AdaBoost.M1 算法的详细细节。当前的分类器 \(G_m(x)\) 由第 2(a) 行的加权观测值得到。在第 2(b) 行计算加权误差率。第 2(c) 行计算赋予 \(G_m(x)\) 的权重 \(\alpha_m\) 来得到最终的分类器 \(G(x)\)(第 3 行)。每个观测的个体权重在第 2(d) 行进行更新。在导出序列中下一个分类器 \(G_{m+1}(x)\) 时,被分类器 \(G(x)\) 错误分类的观测值的权重被因子 \(\exp(\alpha_m)\) 进行缩放以提高它们的相对影响。

在 Firedman et al.(2000)2 的工作中,AdaBoost.M1 算法也称作“离散 AdaBoost”,因为基分类器 \(G_m(x)\) 返回一个离散的类别标签。如果基分类器返回实值预测(如映射到 \([-1,1]\) 的概率),AdaBoost 可以合适地修改(见Firedman et al. (2000)2 的“Real AdaBoost”)
AdaBoost 显著提高非常弱的分类器的效果的能力展现在图 10.2 中。特征 \(X_1,\ldots,X_{10}\) 是标准独立高斯分布,目标 \(Y\) 定义如下
这里 \(\chi_{10}^2(0.5)=9.34\) 是自由度为 10 的卡方随机变量的中位数(10 个标准的高斯分布的平方和)。有 2000 个训练样本,每个类别大概有 1000 个样本,以及 10000 个测试观测。这里的弱分类器仅仅是一个“stump”:含两个终止结点的分类树。仅仅对训练数据应用分类器会得到非常差的测试集误差率(45.8%),与 50% 的随机猜测相差不多。然而,当不断进行 boosting 迭代,误差率将稳定下降,直到 400 次迭代之后达到 5.8%。因此,对这一简单的非常弱的分类器进行boosting,其预测误差率可以几乎降低四分之一。它也比单个的大规模分类树(误差率为 24.7%)表现得要好。自从它的提出,有很多理论来解释 AdaBoost 能成功得到正确分类器。很多工作集中在用分类树作为“基学习者(base learner)”\(G(x)\),改善经常是非常显著的。事实上,Breiman(NIPS Workshop,1996) 将树的 AdaBoost 称为“世界上最好的现成分类器”(best off-the-shelf classifier in the world)。这对于数据挖掘方面的应用尤其如此,本章的后面将更全面地讨论。
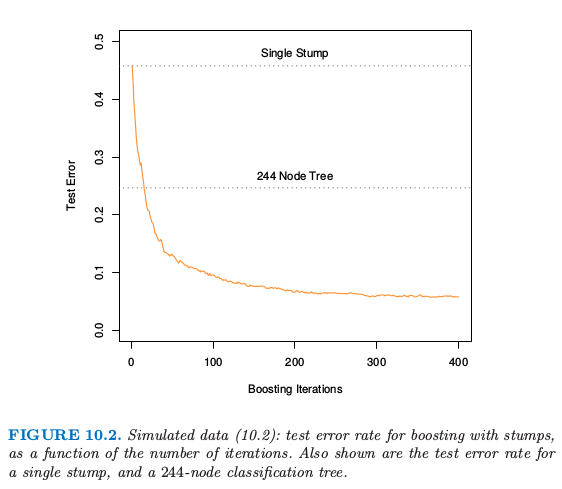
图 10.2. 式( 10.2 ) 的模拟数据:对 stumps 进行 boosting 的测试误差率作为迭代次数的函数。图中也显示了单个 stump 和 244 个结点的分类树的测试误差率。
note “weiya注” 笔记模拟:Eq. 10.2记录了用Julia和R实现的模拟过程。
()本章概要¶
下面是本章的概要:
我们展示 AdaBoost 通过优化一个新的指数损失函数用基学习器拟合加性模型。这个损失函数与(负)二项分布对数似然(见 10.2-10.4 节)非常相似
指数损失函数的总体最小值点(population minimizer)被证明是类别概率 odds 的对数(10.5 节)
我们讨论用于回归与分类的损失函数比平方误差或者指数损失更加稳定(10.6 节)
有人认为决策树是 boosting 是数据挖掘应用中理想的基学习器。(10.7 和 10.9 节)
我们发展一类梯度增强模型(GBMs),用于提升具有任何损失函数的树。(10.10 节)
强调“慢学习”的重要性,并且通过对每个新加进模型的项进行收缩而实现(10.12 节),以及随机化(10.12.2 节)。
描述拟合模型的解释工具(10.13 节)
- 1
Freund, Y. and Schapire, R. (1997). A decision-theoretic generalization of online learning and an application to boosting, Journal of Computer and System Sciences 55: 119–139.
- 2(1,2)
Friedman, J., Hastie, T. and Tibshirani, R. (2000). Additive logistic regression: a statistical view of boosting (with discussion), Annals of Statistics 28: 337–307.