14.7 独立成分分析和探索投影寻踪
Contents
14.7 独立成分分析和探索投影寻踪¶
多元数据经常被看成是从未知来源多次间接测量的数据,一般不能被直接测量。例子有:
在教育或心理学测试中,采用问卷调查来衡量潜在的智商以及其他的心理特征。
EEG 脑扫描通过放置在头部不同位置的感受器的电子信号来间接衡量脑的不同部分的神经元活性。
股票交易价格随着时间持续变化,并且反映了各种各样的未测量的因素,如 市场信心 (market confidence),外部影响以及其他很难识别和测量的推动力。
因子分析(Factor Analysis) 是统计学领域为了识别潜在因素的一个经典方法。因子分析模型通常是用在高斯分布中,所以某种程度上阻碍了它的适用性。最近,独立成分分析(Independent Component Analysis) 成为了因子分析强劲的对手,我们将会看到,它的成功归功于潜在源信号的非高斯特征。
()潜变量和因子分析¶
note “weiya 注:Recall”
奇异值分解 式( 14.54 ) \(\mathbf X=\mathbf{UDV}^T\) 可以表示成潜变量的形式。记 \(\mathbf S=\sqrt{N}\mathbf U\),以及 \(\mathbf A^T=\mathbf{DV}^T/\sqrt{N}\),我们有 \(\mathbf{X=SA}^T\),因此 \(\mathbf X\) 的每一列是 \(\mathbf S\) 的列的线性组合。现在因为 \(\mathbf U\) 是正交的,并且和之前一样假设 \(\mathbf X\) 的列均值为 0(因此 \(\mathbf U\) 也是),这意味着 \(\mathbf S\) 列均值为 0,而且不相关,有单位方差。
note “weiya 注:” 对 \(\mathbf X\) 进行列中心化相当于左乘 \(\mathbf{I - M}\),其中 \(\mathbf M = 11^T/N\),进行 SVD 分解
再左乘 $\mathbf{I-M}$,
注意到 $\mathbf{I-M}$ 为幂等矩阵,即 $\mathbf{(I-M)^2 = (I-M)}$,则
右乘 $\mathbf{VD}^{-1}$ 可以得到 $\mathbf{U = (I-M)U}$,即 $\mathbf U$ 列均值为 0.
用随机变量表示,我们可以把 SVD 或者对应的主成分分析看成是下列潜变量模型的一个估计
或者简单地写成 \(X=\A S\)。相关的 (correlated) \(X_j\) 都表示成 不相关的 (uncorrected)、单位方差的变量 \(S_\ell\) 的线性展开。尽管这不是太满意,因为对于任意给定的 \(p\times p\) 的正交矩阵 \(\R\),我们可以写出
并且 \(\mathrm{Cov} (S^*)=\R\mathrm{Cov}(S)\R^T=\I\)。因此存在许多这样的分解,也因此不可能将任意特定的潜变量作为唯一的潜在来源。SVD 分解确实能以最优的方式得到任意秩为 \(q < p\) 的截断分解。
经典的因子分析模型,主要由 心理测量学 (psychometrics) 的研究者发展而来。某种程度上缓解了这个问题;举个例子,Mardia et al. (1979)1。当 \(q < p\),因子分析模型有如下形式
或者写成 \(X=\A S+\epsilon\)。这里 \(S\) 是 \(q < p\)个揭示潜变量或者因子的向量,\(\A\) 是 \(p\times q\) 的 载荷 (loadings) 矩阵, \(\varepsilon_j\) 是零均值不相关的扰动。想法是潜变量 \(S_\ell\) 是 \(X_j\) 公共方差的来源,表明了它们之间的相关性结构,而 \(\varepsilon_j\) 对每个 \(X_j\) 是唯一的,并且解释了剩下的方差。一般地,\(S_\ell\) 和 \(\varepsilon_j\) 假设为高斯随机变量,并且采用极大似然法来拟合模型。参数都存在于下面的协方差阵中
其中 \(\D_\varepsilon = \mathrm{diag}[\mathrm{Var}(\varepsilon_1),\ldots, \mathrm{Var}(\varepsilon_p)]\)。\(S_\ell\) 为高斯并且不相关,这使得它们在统计上是独立随机变量。因此一系列的教育考试成绩可以认为是有潜在独立的因子,比如 智力 (intelligence),动机 (drive) 等等所决定的。 \(\A\) 的列被称为因子载荷(factor loadings),而且用来命名因子和解释因子。
不幸的是, 唯一性问题 \(式( 14.79 )\) 仍然存在, 因为在式 \(式( 14.81 )\) 中, 对于任意 \(q\times q\) 的正交矩阵 \(\R\), \(\A\) 和 \(\A\R^T\) 是等价的。这导致了因子分析中的主观性, 因为用户可以寻找因子更易解释的旋转版本. 这点使得许多分析学家对因子分析表示怀疑, 而且这可能是它在当代统计中不受欢迎的原因。尽管我们这里不继续讨论细节,但是 SVD 分解在 式( 14.81 ) 的估计上发挥重要作用。举个例子,假设 \(\mathrm{Var}(\varepsilon_j)\) 相等,SVD 的前 \(q\) 个成分确定了由 \(\A\) 张成的子空间。
因为每个 \(X_j\) 独立的扰动 \(\varepsilon_j\),因子分析可以看成是对 \(X_j\) 的相关性结构进行建模,而非对协方差结构建模。这个可以通过对 \(式( 14.81 )\) 的协方差结构进行标准化后得到(练习 14.14)。
note “weiya 注: Ex. 14.14” 练习 14.14 表明,因子分析实质上是对相关矩阵进行分解。详见解答见Issue 51: Ex. 14.14
这是因子分析与 PCA 的重要区别,尽管这不是我们讨论的重点。练习 14.15 讨论了一个简单的例子,因为这个差异,因子分析和主成分的解完全不同。
note “weiya 注: Ex. 14.15” 练习 14.15 用一个实际例子说明了,因子分析和主成分得到的第一因子和第一主成分完全不同。详细解答见 Issue 50: Ex. 14.15
()独立成分分析¶
**独立成分分析 (ICA)**模型与 \(式( 14.78 )\) 有相同的形式, 除了假设 \(S_\ell\) 是统计上独立而非不相关。
note “weiya 注: 独立与不相关” 统计上, 连续型随机变量 \(X\) 与 \(Y\) 独立的定义为
而不相关的定义为
独立意味着不相关,但反之不对。对于二元正态随机变量,两者等价。
直观上, 不相关确定了多元变量分布的二阶交互矩(协方差), 而一般地, 统计独立确定了所有的交互矩。 这些额外的矩条件能让我们找到唯一的 \(\A\)。 因为多元正态分布只要二阶矩就可以确定, 所以这是一个特例, 在忽略一个旋转的情况下任意高斯独立成分可以像之前被确定。 因此如果假设 \(S_\ell\) 是独立且非高斯的, 则可以避免 \(式( 14.78 )\) 和 \(式( 14.80 )\) 的唯一性问题.
这里我们将要讨论 \(式( 14.78 )\) 中全 \(p\) 个成分的模型, 其中 \(S_\ell\) 是独立的且有单位方差; 因子分析模型 \(式( 14.80 )\) 的 ICA 版本也同样存在。 我们的处理是基于 Hyvärinen and Oja (2000)2 的综述文章.
我们希望恢复 \(X=\A S\) 中的混合矩阵 \(\A\)。 不失一般性, 我们假设 \(X\) 已经 白化 (whitened) 使得 \(\mathrm{Cov}(X)=\I\); 这一般可以通过前面描述的 SVD 实现。
note “weiya 注:白化 (whitened)” 根据维基百科,因为白噪声的协方差矩阵为单位阵,所以称这一过程为白化。白化矩阵 \(W\) 使得 \(WX\) 协方差为单位阵(此处 \(X\) 表示为随机向量,若作用在矩阵上,则右乘),则 \(W^TW = \Sigma^{-1}\). 根据求解 \(W\) 的算法,可以分类为
- Mahalanobis or ZCA whitening: $W = \Sigma^{-1/2}$
- Cholesky whitening: 取 Cholesky 分解 $\Sigma^{-1} = LL^T$ 中的 $L^T$,则 $\Sigma = (L^{T})^{-1}L^{-1}$,因而 $W\Sigma W^T=L^T (L^{T})^{-1}L^{-1} L = \I$.
- PCA whitening: 特征分解
而这里提到 SVD,大概是通过
得到
然后取 $W = D^{-1}V$.
反过来, 因为 \(S\) 的协方差也为 \(\I\), 这意味着 \(\A\) 是正交的。 所以求解 ICA 问题等价于寻找正交的 \(\A\) 使得随机变量向量 \(S=\A^T X\) 的组分是独立(且是非高斯的)。
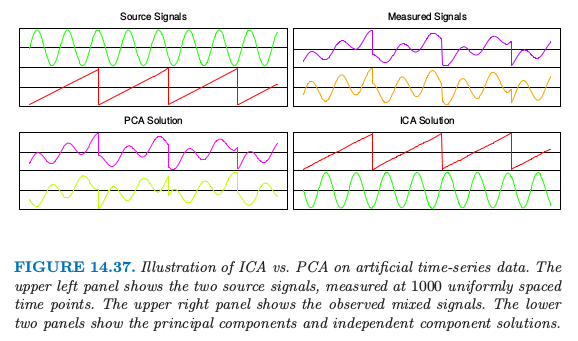
图 14.37 显示了在分离两个混合信号例子中 ICA 的能力。这也是经典的 cocktail party problem 的一个例子,不同的麦克风 \(X_j\) 接受来自不同独立源 \(S_\ell\)(音乐、不同人说的话等等)的混合信号。 ICA 通过利用原始信号源的独立性和非高斯性,能够进行 盲信号分离 (blind source separation)。
许多流行的 ICA 方法是基于熵。 密度为 \(g(y)\) 的随机变量 \(Y\) 的 微分熵 (differential entropy) \(H\) 由下式给出
\( H(Y)=-\int g(y)\log g(y)dy\tag{14.82} \)$
信息理论中一个著名的结论是在所有同方差的随机变量中,高斯随机变量有最大的熵。最后,随机向量 \(Y\) 的组分之间的 互信息量(mutual information) \(I(Y)\) 是独立性的一个自然度量:
\( I(Y)=\sum\limits_{j=1}^pH(Y_j)-H(Y)\tag{14.83} \)$
值 \(I(Y)\) 称为 \(Y\) 的密度 \(g(y)\) 与其独立版本 \(\prod\limits_{j=1}^pg_j(y_j)\) 之间的 Kullback-Leibler 距离, 其中 \(g_j(y_j)\) 是 \(Y_j\) 的边缘密度. 如果 \(X\) 有协方差 \(\I\), 且 \(Y=\A^TX\), 其中 \(\A\) 是正交, 则易证
note “weiya 注: (14.85) 的证明” 只要证
对 式( 14.82 ) 进行变量替换有
其中$\J_{ij}=\frac{\partial y_i}{\partial x_j}$.
又
故
所以 $\det\J = \det \A'=\det \A$.
另外, $X$ 的密度函数为
于是 $(*)$ 式可以写成
证毕。
寻找 \(\A\) 最小化 \(I(Y)=I(\A^TX)\) 也就是寻找使得组分间的独立性最强的正交变换。考虑到式 \(式( 14.84 )\), 这等价于最小化 \(Y\) 的各组分的熵的和, 反过来意味着最大化它们与高斯分布的距离。
注解: 因为高斯随机变量的熵最大, 则让各组分熵之和最小, 意味着各组分远离高斯分布。
为了简便, 与其采用熵 \(H(Y_j)\), Hyvärinen and Oja (2000)2 采用 负熵 (negentropy) \(J(Y_j)\)
\( J(Y_j) = H(Z_j)-H(Y_j)\tag{14.86} \)$
其中 \(Z_j\) 是与 \(Y_j\) 同方差的高斯随机变量。负熵是非负的, 它度量了 \(Y_j\) 与高斯随机变量之间的距离。他们提出负熵的一个简单近似, 这个近似可以用来计算和优化数据. 图 14.37 至图 14.39 中的 ICA 都采用下面的近似
\( J(Y_j)\approx [\E G(Y_j) - \E G(Z_j)]^2\tag{14.87} \)$
其中 \(G(u)=\frac 1a\log\cosh(au), 1\le a\le 2\)。当应用到实际数据时, 期望用数据的平均值代替。这是这些作者们提供的FastICA软件中的一个选项. 更经典(但不太鲁棒)的度量是基于四阶矩, 也因此可以通过 峰度 (kurtosis) 来衡量与高斯分布的距离。更多细节参见 Hyvärinen and Oja (2000)2. 在 14.7.4 节我们讨论他们寻找最优方向的近似牛顿算法.
note “weiya 注:” 峰度是四阶标准矩
总结一下,ICA 应用到多元数据中,来寻找一系列的正交投影,使得投影数据尽可能远离高斯分布。采用白化后的数据(协方差为 \(\I\)),这意味着寻找尽可能独立的组分。
ICA 本质上从因子分析的一个解出发,并且寻找一个旋转得到独立组分。从这点看, ICA 与在心理测量学中采用的传统方法 “varimax” 和 “quartimax” 一样, 仅仅是因子旋转的一种方式.
()例子: 手写数字¶
我们再次讨论 14.5.1 节用 PCA 分析的手写数字“3”。
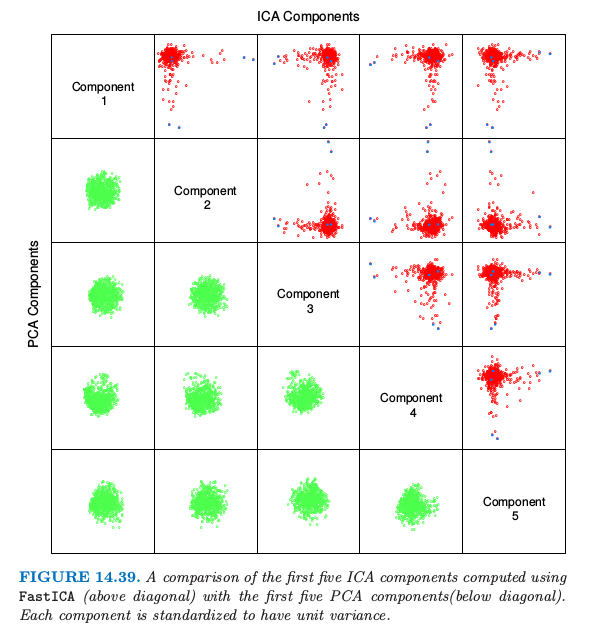
图 14.39 比较了前五个主成分(标准化)和前五个 ICA 成分,都显示在标准化后的同一单位尺度下。注意到每张图都是 256 维空间的二维投影。所有 PCA 组分看上去都服从联合高斯分布,而 ICA 组分都服从长尾分布。这并不是很奇怪,因为 PCA 主要考虑方差,而 ICA 特地寻找非高斯的分布。所有的组分都已经标准化,所以我们看不出主成分的方差降低。
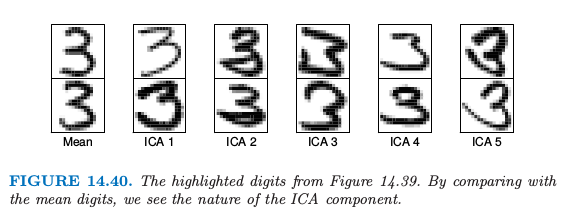
图 14.40 展示了每个 ICA 成分的两个极端的数据点,以及均值的两个极端点。这解释了每个组分的实际意义。举个例子,第五个 ICA 成分捕捉具有长扫尾 (long sweeping tailed) 的“3”。
()例子: 时序脑电图数据¶
ICA 已经成为 脑动力学 (brain dynamics) 中的重要工具, 这里介绍的例子采用 ICA 来理清多频脑电图 (EEG) 数据中信号的组分 (Onton and Makeig, 200612)。
被试者戴上装有 100 个 EEG 电极的帽子, 这些用来记录头皮上不同部位的脑活动。
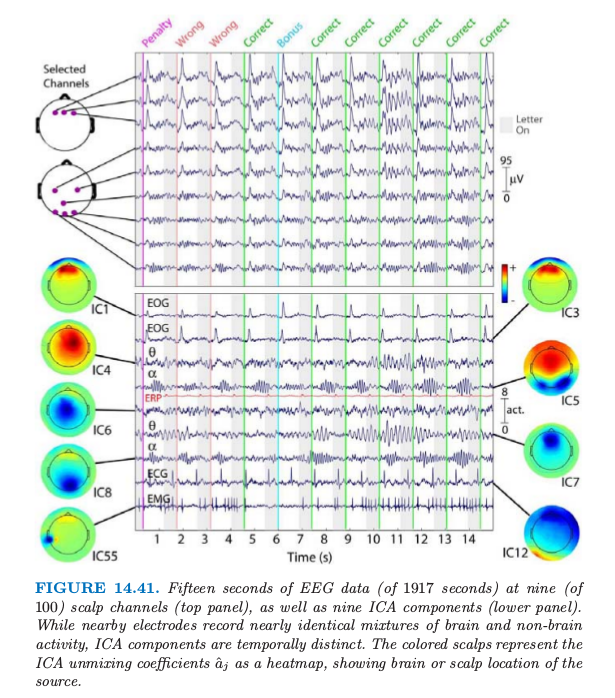
图 14.41(上图)显示了被试者在 30 分钟的周期内进行标准的”two-back”学习过程时,这些电极中的 9 个电极在 15 秒内的输出结果。 大约间隔 1500ms 依次给被试者呈现一个字母 (B, H, J, C, F 或者 K), 然后被试者通过按“是”或“否”的按钮来判断当前的字母与前两步出现的字母是否一致。
note “weiya 注: n-back” 参考wiki: \(n\)-back, \(n\)-back是指给被试者连续的刺激, 要求其判断当前刺激与前\(n\)步的刺激是否一致. 举个例子, 在3-back测试中, 若给被试者如下刺激
则当前刺激为高亮部分时, 被试者应当判断”是”, 因为在前3步出现了高亮部分相同的刺激.
根据被试者的回答,他们得分或者失分,并且偶尔赚取 bonus 或者额外惩罚。脑电图信号中这个时序的数据表现出空间上的相关性———邻近的信号感受器看起来非常相似。
这里重要假设是每个头皮电极上记录的信号是从不同表皮活动以及非表皮区域的人工活动(如下文中提到的眨眼)中产生的独立的电势的混合。 更多ICA在这个领域的细节参见参考文献。
图 14.41 的下半部分展示了 ICA 组分的选择. 彩色图象用(画在头皮上的)热图表示未混合的系数向量的估计值 \(\hat a_j\), 它表明了活性的位置. 对应的时序数据展示了 ICA 组分的活动.
举个例子, 每次反馈信号之后被试者的眨眼(彩色的垂直直线), 它解释了 IC1 和 IC3 中的位置和人工信号. IC12 是与 心脏脉冲 (cardiac pulse) 有关的人工信号. IC4 和 IC7 对应额骨 (frontal) theta-band 的活动, 而且这出现在回答正确后被试者身体的舒展. 更多细节参见 Onton and Makeig (2006)12中对这个例子的讨论, 以及ICA在脑电图模型中的应用.
()探索投影寻踪¶
Friedman and Tukey (1974)3 提出了 探索投影寻踪 (exploratory projection pursuit),这是可视化高维数据的图象探索技巧。他们的观点是高维数据的大多数低维(一维或二维)投影看起来是高斯分布的。 他们提出一系列 projection indices 的方法用于优化, 每个集中在与高斯分布的不同距离。自从他们最先提出该方法, 陆续有各种改进的建议 (Huber, 19854; Friedman, 19875),以及交互式图形软件包 Xgobi(Swayne et al., 19916, 现在叫做 GGobi)中实现的各种指标,包括熵。 这些投影指标与上文介绍的 \(J(Y_j)\) 形式一样, 其中 \(Y_j=a_j^TX\) 是 \(X\) 组分的标准化的线性组合。实际上,交互熵的一些近似和替代与投影寻踪中提出的指标重合。一般在投影寻踪中, 方向 \(a_j\) 不需要限制为正交。Friedman (1987)5将数据在选定的投影上转换使之看起来像高斯分布,然后搜索接下来的方向。尽管他们的出发点不一样,但是 ICA 和探索投影寻踪非常相似,至少对于这里描述的表示形式。
()独立分量分析的一种直接方法¶
由定义知独立组分有如下联合乘积密度
所以这里展示一种采用广义可加模型(9.1 节)来直接估计这个密度的方式。全部细节可以在 Hastie and Tibshirani (2003)7中找到, 并且这个方法已经在ProDenICA的 R 包中实现了, 这可以在 CRAN 上下载.
根据与高斯分布的距离的表示, 我们将每个 \(f_j\) 写成
这是倾斜的 (tilted) 高斯密度。这里 \(\phi\) 是标准高斯分布密度, 并且 \(g_j\) 满足密度函数所要求的标准化条件。和之前一样假设 \(X\) 已经预处理,观测数据 \(X=\A S\) 的对数似然为
note “weiya 注:” 式( 14.90 )原书中 \(\phi\) 有下标 \(j\), 但是因为 \(\phi\) 为标准正态, 所以应该直接忽略下标, 原书中后面的 式( 14.91 ) 也确实没有下标。
我们希望在 \(\A\) 为正交且 \(式( 14.89 )\) 定义的 \(g_j\) 的条件下, 最大化上式。对 \(g_j\) 不添加额外的约束, 模型 式( 14.90 ) 是过参数化的, 所以我们最大化下面的正则化版本
受 Silverman (1986)8的启发,在 \(式( 14.91 )\) 中, 我们(对每个 \(j\))减去了两个惩罚项:
第一个在任意解 \(\hat g_j\) 上强制要求密度约束 \(\int \phi(t)e^{\hat g_j(t)}dt=1\)
第二个是鲁棒性惩罚, 保证了解 \(\hat g_j\) 是结点在观测值 \(s_{ij}=a_j^Tx_i\) 的四次样条.
note “weiya 注:” 下面说明为什么第一个惩罚项能够对 \(\phi(t)e^{\hat g_j(t)}\) 的密度进行约束。假设随机变量 \(X\) 的密度函数为 \(f(x)\),其对数似然函数为 \(g(x)\propto \log f(x)\),这个问题归结为说明
在 $\int e^g=1$ 的约束下的 $\arg\max$ 等于
的 $\arg\max$。
考虑$g^*=g-\log \int e^g$
则
于是
因 $t-\log t\ge 1, \forall t>0$,当且仅当 $t=1$ 取等号,
则 $A(g^*)\ge A(g)$,也就是当且仅当 $\int e^g = 1$ 时,$A(g)$会取得最大值,而这时候$A(g)=A_0(g)-1$,所以$A_0(g)$也会取得最大值。由此看出,$A_0(g)$在$\int e^g=1$的约束下的$\arg\max$等于(无约束的)$A(g)$的$\arg\max$。
关于第二个点说得到四次样条,我想可以这样类比理解(但不严谨),我们知道四次样条有三阶连续的导函数,且对于[光滑样条(三次)](../05-Basis-Expansions-and-Regularization/5.4-Smoothing-Splines/index.html)有如下形式
可以类比看出第二个惩罚正是针对四次样条。
可以进一步证明每个解密度 \(\hat{f_j}=\phi e^{\hat g_j}\) 的均值为 0, 方差为 1(练习 14.18)。当我们增大 \(\lambda_j\),这些解近似标准高斯密度 \(\phi\)。

如在算法 14.3 中描述, 以一种轮换的方式优化 \(式( 14.91 )\) 来拟合函数 \(g_i\) 和方向 \(a_j\)。
第 2(a) 步等价于半参密度估计,可以采用广义可加模型来求解。为了方便,我们取 \(p\) 个独立问题中的一个
尽管 \(式( 14.92 )\) 的第二个积分导出光滑样条, 但第一个积分比较困难,需要近似。我们构造一个 \(L\) 个值为 \(s_\ell^*\) 的细网格,这些值间距为 \(\Delta\)、覆盖观测值 \(s_i\) 的取值范围, 并且统计得到的小块中 \(s_i\) 的个数:
一般我们取 \(L\) 为 1000 就已经足够了。 则 \(式( 14.92 )\) 可以近似为
note “weiya 注:翻译相关” 原文 \(y\) 的脚标是 \(i\),但应该是个 typo,应为 \(\ell\).
这个表达是可以看成是与惩罚的 Poisson 对数似然成比例,其中响应变量为 \(y_\ell^*/\Delta\),惩罚参数为 \(\lambda/\Delta\),均值为 \(\mu(s)=\phi(s)e^{g(s)}\)。
note “weiya 注:Poisson 对数似然” 有关讨论详见 Issue 54
这是一个 广义可加样条模型 (generalized additive spline model)(Hastie and Tibshirani, 19909; Efron and Tibshirani, 199610),其中的 offset 项为 \(\log \phi(s)\), 并且可以以 \(O(L)\) 的复杂度用牛顿算法进行拟合。尽管要求四次样条,但是实际中我们发现三次样条就足够了。我们有 \(p\) 个调整参数 \(\lambda_j\) 需要设定,在实际中我们使得它们相等,然后通过有效自由度 \(\mathrm{df}(\lambda)\) 来确定光滑的程度。我们的软件采用 \(5\df\) 作为默认值。
算法 14.3 的 2(b) 要求在给定 \(\hat g_j\),对 \(\A\) 进行优化。和式中仅仅第一项有涉及 \(\A\),并且因为 \(\A\) 是正交的,则涉及 \(\phi\) 的所有项的集合不依赖 \(\A\)(练习 14.19)。
note “weiya 注:Ex. 14.19” 已解决,详见 Issue 55: 练习 14.19.
因此我们只需要最大化
\(C(\A)\) 是拟合的密度与高斯密度间的对数似然比,而且可以看成是负熵 式( 14.86 ) 的一个估计, 其中每个 \(\hat g_j\) 就像 式( 14.87 ) 中的差异函数。第 2(b) 步中的固定点更新是修改后的牛顿法(练习 14.20):
对于每个 \(j\),更新
\( a_j\leftarrow \mathbb{E} \{X\hat g_j'(a_j^TX)-\mathbb{E}[\hat g_j^{(2)}(a_j^TX)]a_j\}\tag{14.96} \)$
其中 \(\E\) 表示关于 \(x_i\) 的期望。因为 \(\hat g_j\) 是拟合的四次(或者三次)样条,则式中第一项和第二项已经计算好了。 2. 采用对称平方根变换将 \(\A\) 化为正交矩阵:\((\A\A^T)^{-\frac 12}\A\)。如果 \(\A=\U\D\V^T\) 是 \(\A\) 的 SVD 分解,则易证 \(\A\leftarrow \U\V^T\)。
note “weiya 注:Ex. 14.20” 已解决,详见 Issue 56: Ex. 14.20.
我们的 ProDenICA 算法和 FastICA 算法在图 14.37 中的模拟时间序列数据、图 14.38 的均匀分布数据的混合以及图 14.39 中的数字数据都表现得一样好。
()例子:模拟¶
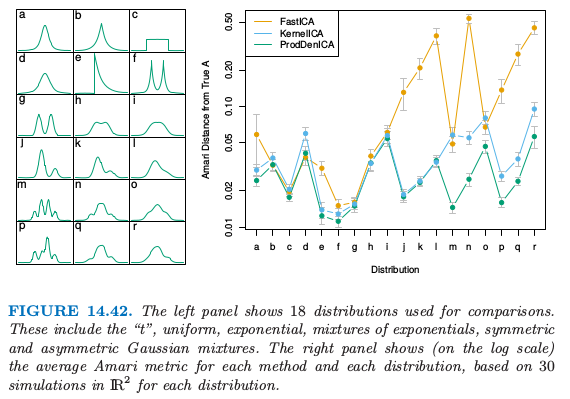
图 14.42 展示了比较 ProDenICA 与 FastICA 以及另外一个半参方法 KernelICA(Bach and Jordan, 200211)的模拟的结果。左图展示了作为比较的基础的 18 个分布。对于每个分布,我们产生成对的独立组分(\(N=1024\)),以及随机的混合矩阵 \(\mathbb{R}^2\),条件数为 1 到 2 之间。
note “weiya 注:条件数” 矩阵\(A\)的条件数为
若$\Vert\cdot \Vert$为二范数
其中$\sigma_\max(A)$和$\sigma_\min(A)$分别为$A$的最大和最小的奇异值。
对于正规矩阵,即满足
有
其中$\lambda$为特征值。
当$A$为单位阵时,$\kappa(A)=1$。
我们采用FastICA的 R 语言实现,采用 \(式( 14.87 )\) 的负熵准则,ProDenICA也是这样。对于KernelICA,我们采用作者的MATLAB代码。因为搜索准则是非凸的,我们对每种方法采用 5 个随机初始值。每个算法都传入正交的混合矩阵 \(\A\)(数据已经进行了白化),这可以用来比较产生的正交混合矩阵 \(\A_0\)。我们采用 Amari 距离(Bach and Jordan, 200211)来度量两个矩阵接近程度:
其中 \(r_{ij}=(\A_o\A^{-1})_{ij}\)。图 14.42 的右图比较了真实矩阵与估计的矩阵的 Amari 距离(对数尺度下)。ProDenICA在所有的情形都可以与FastICA和KernelICA进行比较,并且在大多数混合情形下表现最好。
- 1
Mardia, K., Kent, J. and Bibby, J. (1979). Multivariate Analysis, Academic Press.
- 2(1,2,3)
Hyvärinen, A., Karhunen, J. and Oja, E. (2001). Independent Component Analysis, Wiley, New York.
- 12(1,2)
Onton, J. and Makeig, S. (2006). Information-based modeling of event-related brain dynamics, in Neuper and Klimesch (eds), Progress in Brain Research, Vol. 159, Elsevier, pp. 99–120.
- 3
Friedman, J. and Tukey, J. (1974). A projection pursuit algorithm for exploratory data analysis, IEEE Transactions on Computers, Series C 23: 881–889.
- 4
Huber, P. (1985). Projection pursuit, Annals of Statistics 13: 435–475.
- 5(1,2)
Friedman, J. (1987). Exploratory projection pursuit, Journal of the American Statistical Association 82: 249–266.
- 6
Swayne, D., Cook, D. and Buja, A. (1991). Xgobi: Interactive dynamic graphics in the X window system with a link to S, ASA Proceedings of Section on Statistical Graphics, pp. 1–8.
- 7
Hastie, T. and Tibshirani, R. (2003). Independent components analysis through product density estimation, in S. T. S. Becker and K. Obermayer (eds), Advances in Neural Information Processing Systems 15, MIT Press, Cambridge, MA, pp. 649–656.
- 8
Silverman, B. (1986). Density Estimation for Statistics and Data Analysis, Chapman and Hall, London. 下载
- 9
Hastie, T. and Tibshirani, R. (1990). Generalized Additive Models, Chapman and Hall, London.
- 10
Efron, B. and Tibshirani, R. (1996). Using specially designed exponential families for density estimation, Annals of Statistics 24(6): 2431–2461.
- 11(1,2)
Bach, F. and Jordan, M. (2002). Kernel independent component analysis, Journal of Machine Learning Research 3: 1–48. 从作者主页下载代码和文章,备用下载