5.5 平滑参数 \lambda 的自动选择
Contents
5.5 平滑参数 \(\lambda\) 的自动选择¶
回归样条的平滑参数包括样条的 degree,连接点的个数及位置。对于平滑样条,我们仅仅有惩罚参数 \(\lambda\) 可以选择,因为连接点是所有不同的 \(X\) 取值,且在实际中 degree 经常取三 。
选择回归样条连接点的位置及数目是一项复杂的组合任务,除非强加一些简化。第 9 章的 MARS 过程采用贪婪算法以及额外的近似来达到实际的妥协。这里我们不会深入讨论。
5.5.1 固定自由度¶
因为对于平滑样条而言,\(\mathrm{df}_\lambda=\mathrm{trace}(\mathbf S_\lambda)\) 是关于 \(\lambda\) 的单调函数,这个关系是可逆的,并且通过固定自由度来确定 \(\lambda\)。实际中,这可以通过简单的数值方法实现。举个例子,在 R 中,可以采用 smooth.spline(x,y,df=6) 来确定平滑的程度。这鼓励更加传统的模型选择的模式,其中我们可能尝试一系列不同的自由度,然后根据近似的 \(F\) 检验,残差图以及其它更客观的准则来选择。通过这种方式使用自由度提供了更加统一的方式来比较许多不同的平滑方法。在广义可加模型 (generalized additive models) 中特别有用(第 9 章),其中多种平滑方法可以同时应用在一个模型中。
5.5.2 偏差-方差的权衡¶
图 5.9 显示了在如下简单的模型中应用平滑样条 \(df_\lambda\) 的选择的效果:
其中 \(X\sim U[0,1], \varepsilon\sim N(0, 1)\)。我们的训练样本包含从该模型中独立抽取的 \(N=100\) 个数据对 \(x_i,y_i\)。
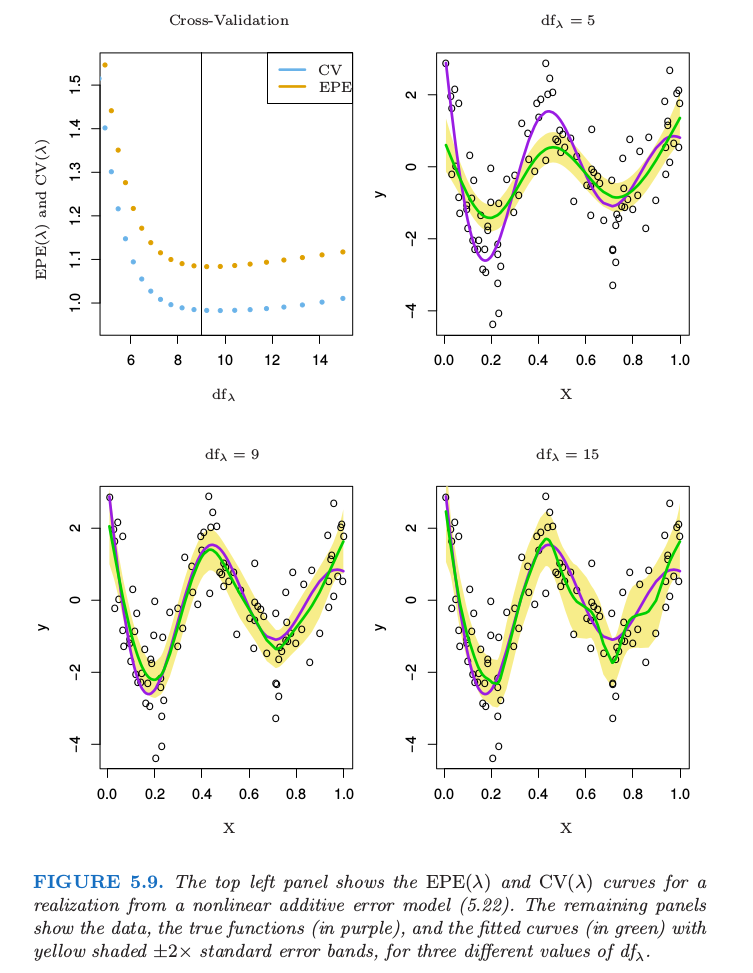
图中显示了 3 个不同 \(\mathrm{df}_\lambda\) 的拟合样条。图中黄色阴影部分表示 \(\hat f_\lambda\) 的逐点标准差,也就是,我们将区域 \(\hat f_\lambda(x)\pm 2\cdot se(\hat f_\lambda(x))\) 画成阴影。因为 \(\hat{\mathbf f}=\mathbf S_\lambda \mathbf y\),
对角元包含训练点 \(x_i\) 的逐点方差。偏差由下式给出
其中 \(\mathbf f\) 是真实的 \(f\) 在训练点 \(X\) 处的取值得到的向量(未知)。期望和方差是从模型 (5.22) 中重复采样得到的大小为 \(N=100\) 的样本。类似地,\(\mathrm{Var}(\hat f_\lambda(x_0))\) 和 \(\mathrm{Bias}(\hat f_\lambda(x_0))\) 可以在任意点 \(x_0\) 处计算得到(练习 5.10)。
图中的三个拟合直观展示了与选择平滑参数有关的偏差——方差权衡 (bias-variance tradeoff)。
\(df_\lambda=5\): 样条欠拟合,并且很明显坡顶被削减波谷被充填 (trims down the hills and fills in the valleys)。这导致在高曲率的地方有更显著的偏差。标准差带非常狭窄,所以我们估计了真实函数的一个相对稳定但偏差较大的版本。
\(df_\lambda=9\): 尽管少量的偏差看起来很明显,但这里拟合函数接近真实函数。方差没有明显地增长。
\(df_\lambda=15\): 拟合函数有点弯曲,但是接近真实函数。这种弯曲也意味着标准差带宽度的增长——曲线开始紧密地跟随一些个别点
注意到在这些图中我们看到的是每种情形下数据的单个实现以及因此得到的拟合样条 \(\hat f\) 的实现,但偏差会涉及到期望 \(\mathbb{E}(\hat f)\)。我们将这留作练习( 5.10) 来绘制类似的图象,其中要求画出偏差。
中间的曲线似乎恰恰实现了偏差与方差之间的平衡。
积分平方预测误差 (EPE) 用一个总结式结合了偏差和方差:
注意到这是在训练样本(得到 \(\hat f_\lambda\) )和(独立选择的)预测点 \((X,Y)\) 的值中进行平均。
EPE 是一个很自然的感兴趣的量,而且确实能在偏差和方差之间创造平衡。图 5.9 的左上图中的蓝点表明正好满足 \(\mathrm{df}_\lambda=9\) !
因为我们不知道真实函数,所以无法得到 EPE,因此需要一个估计。这个话题将在第 7 章中详细展开,以及像 \(K\) 折交互验证,GCV 和 \(C_p\) 等广泛使用的方法。在图 5.9 中我们展示了一个 \(N\) 折(留一法)交互验证的曲线:
上式可以从原始的拟合数据中计算每个 \(\lambda\) 值以及 \(\mathbf S_\lambda\) 的对角元素(练习 5.13)来得到。
EPE 和 CV 曲线有着相同的形状,但是整个 CV 曲线都是在 EPE 的下面。对于有些正则化,则相反,而且总体来看,CV 曲线作为 EPE 曲线的估计是近似无偏的。