6.6 核密度估计和分类
Contents
6.6 核密度估计和分类¶
核密度估计是非监督学习过程,在历史上先于核回归。它还自然地导出了非参分类的一系列简单的过程。
6.6.1 核密度估计¶
假设从概率密度 \(f_X(x)\) 中取随机样本 \(x_1,x_2,\ldots,x_N\),并且希望估计 \(x_0\) 处的 \(f_X\)。为了简化,我们现在假设 \(X\in \mathbb{R}\)。与前面一样,一个自然的局部估计有如下形式
其中 \(\mathcal N(x_0)\) 为 \(x_0\) 附近的宽度为 \(\lambda\) 的很小的邻域。这个估计非常振荡,所以更倾向于使用光滑的 Parzen 估计
因为它考虑离 \(x_0\) 近的观测点,并且观测点的权重系数随着离 \(x_0\) 的距离增大而减小。这种情形下 \(K_\lambda\) 受欢迎的选择是高斯核 \(K_\lambda(x_0,x)=\phi(\vert x-x_0\vert/\lambda)\)。图 6.13 显示了根据 CHD 群中 systolic blood pressure 的样本值来拟合高斯核密度。令 \(\phi_\lambda\) 是均值为 0 标准差为 \(\lambda\) 的高斯密度,则 式( 6.22 ) 有如下形式
这是经验分布函数 \(\hat F\) 和 \(\phi_\lambda\) 的卷积。
note “weiya 注:” 按照卷积的定义,
另外,两个独立随机变量和的分布也可以表示为卷积形式。具体地,假设 $X$ 和 $Y$ 独立,分布函数分别为 $F(x)=P(X\le x), G(y)=P(Y\le y)$,则 $X+Y$ 的分布函数为
分布函数 \(\hat F(x)\) 在每个观测 \(x_i\) 处赋予 \(1/N\) 的权重,并且是跳跃的;在 \(\hat f_X(x)\) 中我们已经对每个观测 \(x_i\) 加上独立高斯噪声来光滑 \(\hat F\).
Parzen 密度估计是局部平均的等价,并且根据局部回归提出了改进【在密度的对数尺度下;见 Loader (1999)1】。我们这里不继续讨论这些。在\(\mathbb{R}^p\)中,高斯密度的自然推广意味着在 式( 6.23 ) 中使用高斯积的核,
tip “weiya 注:” 分享一篇介绍 Python 实现核密度估计的博客。
6.6.2 核密度分类¶
利用贝叶斯定理可以直接地对分类做非参数密度估计。假设对于 \(J\) 分类问题,我们对每个类别单独拟合非参密度估计 \(\hat{f_j}(X),j=1,\ldots,J\),并且我们有类别先验概率 \(\hat \pi_j\) 的估计(通常是样本比例)。则
图 6.14 将这个方法应用在心脏风险因子研究中估计 CHD 的患病率中,并且应该与图 6.12 的左图进行比较。主要的差异出现在图 6.14 中右图的高 SBP 区域。这个区域中对于两个类别的数据都是稀疏的,并且因为高斯核密度估计采用度量核,所以密度估计在其他区域中效果很差(高方差)。局部逻辑斯蒂回归方法(6.20)采用 \(k\)-NN 带宽的三次立方核;这有效地拓宽了这个区域中的核,并且利用局部线性假设来对估计进行光滑(在逻辑斯蒂尺度上)。
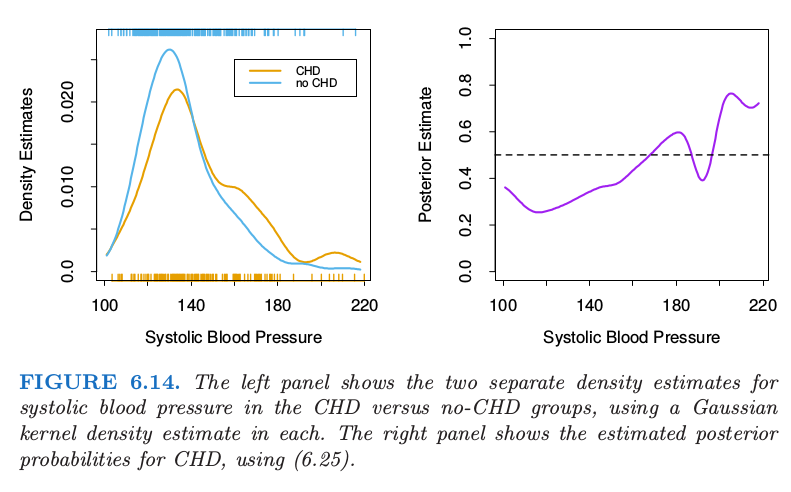
左图显示了在 CHD 和 no-CHD 群体中 systolic blood pressure 的两个独立的密度估计,每个都采用高斯核估计。右图显示了用(6.25)估计的CHD的后验概率。
如果分类是最终的目标,则将单独的类别密度学得很好可能不是必要的,并且可以实际上有误导。图 6.15 显示了密度都是 多模的 (multimodal) 的例子,但是后验比例非常光滑。从数据中学习单独的密度,可能考虑设置一个更粗糙,高方差的拟合来捕捉这些特征,这与估计后验概率的目的是不相关的。实际上,如果分类是最终目标,我们仅仅需要估计在判别边界附近的后验(对于两个类别,这也就是集合 \(\\{x\mid \mathrm{Pr}(G=1\mid X=x)=\frac{1}{2}\\}\))
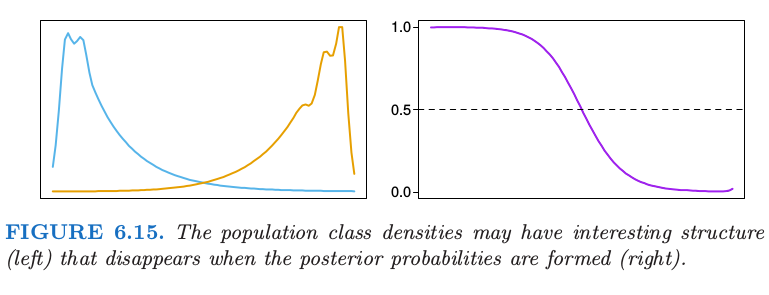
总体类别的密度可能会有有趣的结构(左图),但是这种结构会在后验概率中消失(右图)。
6.6.3 朴素贝叶斯分类器¶
不管其名字如何,这是近年仍然流行的技巧。当特征空间的维数 \(p\) 很高时,此方法特别合适,使得密度估计不再吸引人。朴素贝叶斯模型假设给定类别 \(G=j\),特征 \(X_k\) 是独立的:
尽管这个假设一般是不对的,但是确实很大程度上简化了估计:
单独的类别条件的边缘密度 \(f_{jk}\) 可以采用一维核密度估计分别估计出来。这实际上是原始朴素贝叶斯过程的泛化,采用单变量高斯分布来表示这些边缘密度。
如果 \(X\) 的组分 \(X_j\) 是离散的,则可以使用合适的直方图估计。这提供了在特征向量中混合变量类型的完美方式。
尽管这些假设过于乐观,朴素贝叶斯分类器经常比更复杂的分类器做得更好。原因与图 6.15 相关:尽管单独的类别密度估计可能是有偏的,但这个偏差或许不会对后验概率不会有太大的影响,特别是在判别区域附近。实际上,这个问题或许可以承受为了节省方差造成的相当大的偏差,比如“天真的”假设得到的。
从 式( 6.26 ) 开始我们可以导出逻辑斯蒂变换(采用类别 \(J\) 作为基底):
这有广义加性模型的形式,更多细节将在 第 9 章 中描述。尽管模型以完全不同的方式来拟合;它们的差别将在练习 6.9 中探索。
朴素贝叶斯和广义加性模型间的关系可以类比成线性判别分析和逻辑斯蒂回归(4.4.5 节)。
- 1
Loader, C. (1999). Local Regression and Likelihood, Springer, New York.